
Les versions majeures précédentes de Rudder ont introduit de nombreuses nouveautés. Les retours des utilisateurs ont permis d’enrichir et de perfectionner ces fonctionnalités, d’où une version 4.3 de consolidation et d’optimisation en attendant les grandes nouveautés à paraître bientôt dans la version 5.
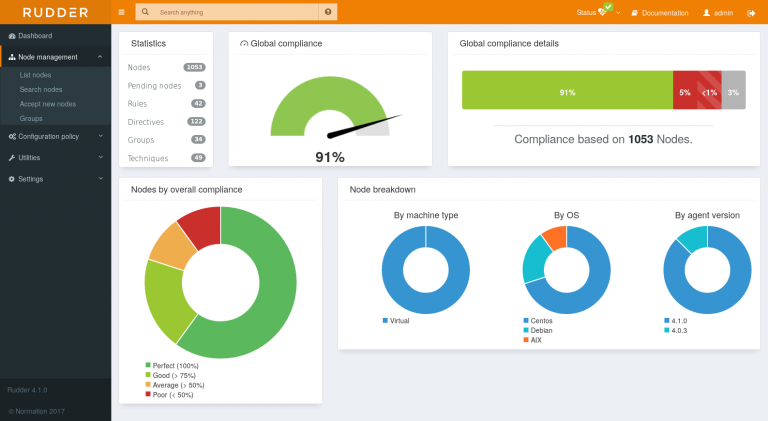
Rudder est une solution libre et multi‐plate‐forme de Continuous Configuration (gestion de configuration et audit en continu), visant particulièrement les besoins d’infrastructures de production.
Sommaire
- Qu’est‐ce que Rudder ?
- Rudder 4.3
- Et maintenant ?
Qu’est‐ce que Rudder ?
Rudder est une solution libre de Continuous Configuration qui audite le système d’information (SI) en continu et automatise les opérations logicielles de façon contrôlée et sécurisée.
Derrière le terme de Continuous Configuration, on trouve une base de gestion de configuration, alliée à des fonctionnalités d’audit en continu. La différence entre un outil de gestion de configuration traditionnel et Rudder, c’est que les changements peuvent être simulés individuellement avant d’être validés, puis vérifiés après être appliqués et, enfin, tracés et maintenus dans le temps. Tout ce qui n’est pas conforme à l’état cible, auquel on souhaite rester ou accéder, remonte des alertes en temps réel, crée des rapports de dérive ou déclenche une remédiation automatique. Cela en fait un outil particulièrement adapté pour répondre aux contraintes d’infrastructure de production.
D’un point de vue pratique, Rudder permet de :
- gérer le socle système (distribuer des clefs SSH, paramétrer le DNS, gérer les utilisateurs, gérer l’état des services, paramétrer les permissions sur les dossiers et fichiers, lancer des tâches, gérer les certificats, etc.) ;
- installer, mettre à jour et configurer des applications ;
- appliquer et vérifier en continu les politiques de sécurité, y compris pour des normes externes (ISO 27001, PCI-DSS, PSSI de l’ANSSI, etc.).
En bref, Rudder est :
- un outil de gestion de configuration et d’audit en continu, existant depuis 2011 ;
- libre (code sous GPL v3, documentation sous CC BY-SA 2.0, avec quelques bibliothèques sous licence Apache) ;
- composé d’un serveur qui gère les configurations et la remontée de conformité (en Scala) et d’un agent de configuration (en C), qui gère Debian, Ubuntu, RHEL/CentOS, SLES, Slackware et AIX ;
- utilisé par de larges productions critiques comme la Caisse d’Épargne, BMW ou Eutelsat ;
- principalement développé par Normation, qui propose différents services autour de Rudder, tels qu’une souscription incluant un support éditeur, de la formation et de l’expertise, ainsi que des greffons payants pour des besoins spécifiques (notamment pour le prise en charge des machines Windows).

Pour ceux qui veulent voir plus en détails le fonctionnement de Rudder, vous pouvez consulter le schéma d’architecture.
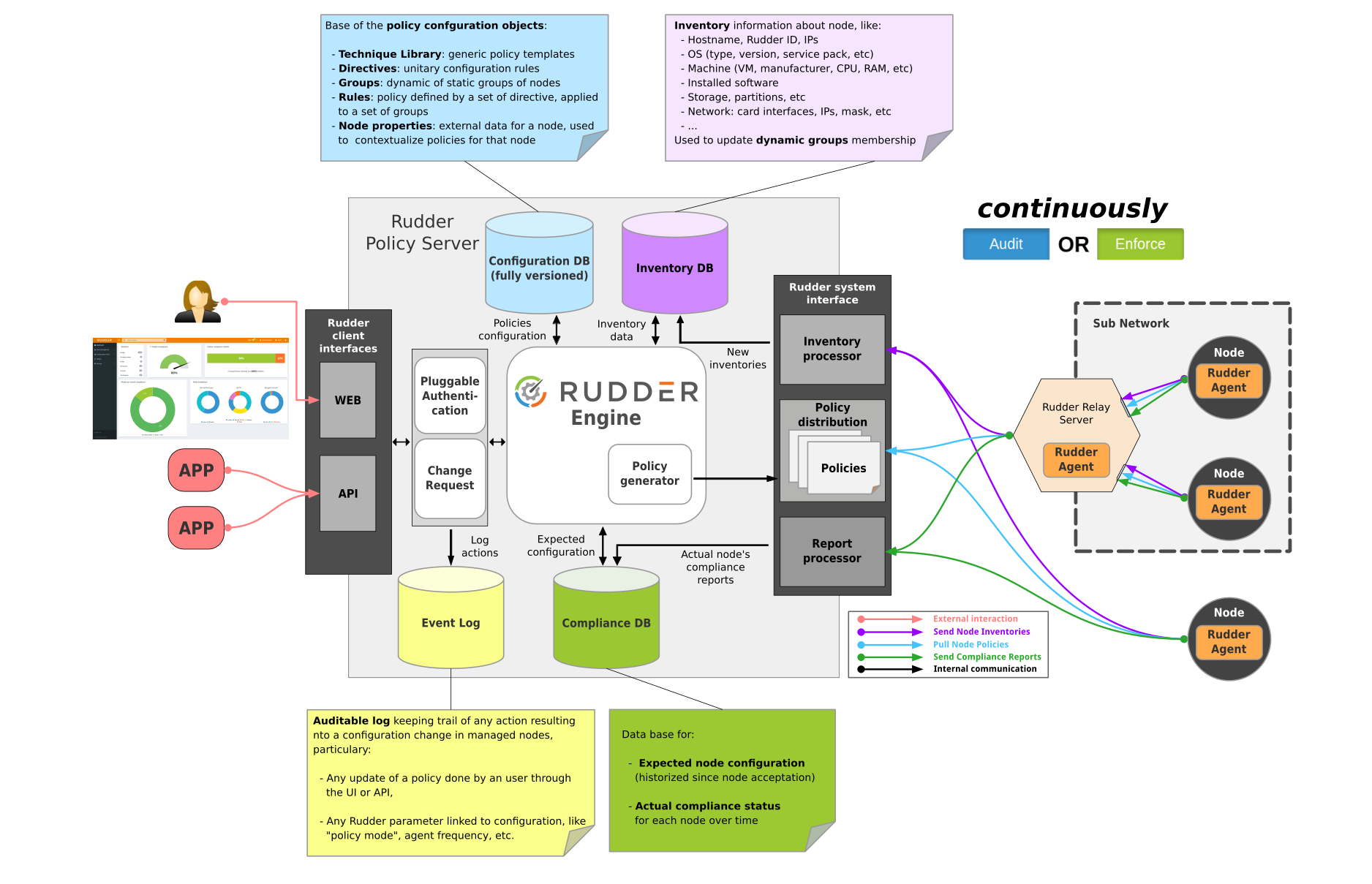{kind=link}
Rudder 4.3
Rudder 4.2 est sorti le 28 septembre 2017, et Rudder 4.3, le 19 avril 2018. Ces versions prolongent les changements entamés depuis la 4.0, en se concentrant sur l’élargissement des possibilités de définition de configurations à appliquer et sur l’amélioration de la gestion des machines dans Rudder.
Politiques de configuration
Gestion de plusieurs types d’agents de configuration
La principale évolution de Rudder 4.2 est la possibilité de générer des configurations pour plusieurs types d’agents. En l’occurrence, nous avons ajouté la prise en charge de Windows DSC, l’outil d’application de configuration désormais intégré à Windows. Cette prise en charge est fournie sous la forme d’un greffon payant pour Rudder.
Éditeur visuel de politiques de configuration
L’une des particularités de Rudder est qu’il dispose d’une interface graphique complète, incluant la définition des configurations. Cette définition s’effectue à l’aide de blocs de configuration correspondant aux items de base du système (fichiers, permissions, paquets logiciels, services, etc.)
Les politiques de configuration ainsi définies sont ensuite utilisables sur les machines, aussi bien en mode audit (qui remonte les non‐conformités sans agir sur les machines) qu’en modification (pour effectuer les changements et atteindre l’état visé). De plus, Rudder vient avec une bibliothèque de configurations prédéfinies répondant aux besoins de gestion de base du système (configuration DNS, gestion des utilisateurs, NTP, distribution de clefs SSH, etc.)
Rudder 4.3 apporte une amélioration déterminante à cet éditeur en permettant la définition de paramètres pour ces politiques. Par exemple, il est possible de définir une politique de configuration d’une application prenant en paramètre la base de données à laquelle se connecter. Cela permet donc d’abstraire des configurations complexes et de les rendre accessibles avec une interface sur mesure simple et accessible (un formulaire Web), facilitant l’utilisation par des profils non‐spécialistes en gestion de configuration.

Une deuxième évolution importante est l’introduction d’une capacité d’importation et d’exportation de politiques de configuration depuis cet éditeur. Elle permet de facilement partager ces politiques entre serveurs et utilisateurs. Cela ouvre aussi la possibilité d’une future plate‐forme de partage de politiques de configuration.
Une nouvelle capacité a été ajoutée aux politiques de configurations prédéfinies qui acceptent plusieurs instances sur une même machine (présence d’un paquet logiciel, etc.) : une passe de configuration avant la première des instances et une après la dernière. Un cas d’utilisation classique est le redémarrage d’un service une seule fois à la fin d’une liste de vérifications, par exemple. Mais cela permet aussi d’effectuer des actions atomiques à partir de plusieurs configurations indépendantes : si vous voulez ajouter trois utilisateurs au fichier sudoers, l’édition ne sera faite qu’à la fin, en une seule fois.
Gestion des machines dans Rudder
En ce qui concerne la gestion des machines reliées à un serveur Rudder, la 4.3 a aussi apporté des nouveautés. Elles disposent maintenant d’un cycle de vie, qui permet de leur appliquer des politiques différentes, mais influence aussi leur comportement dans Rudder, pour faciliter la gestion à long terme.
Cela permet de gérer les cas suivants :
- les machines en cours d’installation, ce qui permet d’appliquer des règles de configuration particulières ;
- les machines en cours de dé‐commissionnement, ce qui permet d’appliquer des règles de configuration particulières ;
- les machines désactivées (éteintes, en maintenance), qui sont ignorées : aucune configuration n’est générée pour elles, et elles ne sont pas prises en compte dans la conformité ; cet état peut aussi servir pour des machines supprimées ;
- les machines non gérées mais avec un agent installé et dont la connexion est maintenue active pour pouvoir les réactiver facilement.
Concernant les informations sur les machines connues du serveur Rudder, elles sont issues d’un inventaire (matériel et logiciel) envoyé régulièrement par l’agent. Cet inventaire est, depuis la version 4.3, extensible par la mise en place de scripts dans un dossier prédéterminé, qui seront exécutés et dont la sortie (au format JSON) sera ajoutée à l’inventaire. Cela permet de compléter les propriétés de nœuds qui sont des variables (scalaires ou hiérarchiques) associées à chaque machine gérée, pouvant être utilisées comme critère de classification ou directement dans la configuration.

Ces propriétés ont donc maintenant trois sources possibles :
- le serveur Rudder lui‐même, avec une définition utilisant l’interface Web ou l’API ;
- une API externe synchronisée (en utilisant le greffon datasources) ;
- des informations locales provenant de la machine, en utilisant l’extension d’inventaire.
En termes de classification des machines (définition des groupes Rudder), la possibilité d’utiliser l’appartenance à un groupe devient un critère de définition au même titre que le nome de l’hôte (hostname), etc. En effet, dans Rudder, les politiques de configuration sont appliquées à des groupes de machines, qui sont définis par des critères de recherche sur leurs informations, permettant une évolution continue du contenu des groupes en fonction de l’évolution du parc. Cela permet de construire des hiérarchies de groupes et, ainsi, de répercuter les évolutions des définitions des groupes de base sur des groupes composés.

Performances et scalabilité
La question des performances et de la scalabilité de Rudder est cruciale pour la gestion de parcs de grande ampleur. Rudder 2 visait une capacité de gestion de quelques centaines de machines, jusqu’à mille avec Rudder 2.11. Rudder 3.1 a atteint les 5 000, puis Rudder 4.1 les 10 000 (3 min pour générer une configuration complète pour 7 000 machines, ce qui est rarement le cas, seules les configurations modifiées étant recalculées).
Le travail sur la mise à l’échelle de Rudder a continué en version 4.3, pour suivre les besoins de nos utilisateurs et accompagner de nouveaux usages. Rudder 4.3 peut être utilisé pour gérer 15 000 machines depuis un même serveur central, grâce à des améliorations du moteur de génération de configuration.
Pour plus de détails, vous pouvez visionner How we scaled Rudder to 10k servers, and the road to 50k.
Côté agent, nous avons ajouté une nouvelle option permettent de suivre les durées d’exécution des différents éléments vérifiés, pour détecter facilement les causes éventuelles de lenteur.

Empaquetage et intégration système
Du côté de l’empaquetage de Rudder, de gros changements ont été réalisés, avec la mise en place de dépendances embarquées dans les paquets en fonction des systèmes d’exploitation. En effet, Rudder vise à prendre en charge des anciennes versions de systèmes d’exploitation pour permettre l’automatisation d’infrastructures existantes, et les faire évoluer plus facilement.
Sur l’agent, nous avons migré nos services vers des units systemd sur les systèmes d’exploitation compatibles, en découpant au passage le service en deux sous‐services correspondants au serveur intégré à l’agent et au service chargé de l’exécuter régulièrement. De plus, la prise en charge de l’IPv6 est désormais activée par défaut.
Intégration et extension
L’API REST de Rudder, qui permet d’effectuer tout ce qu’il est possible de faire dans l’interface (et même plus), a été enrichie d’un nouveau système de droits, permettant :
- de limiter les droits d’un jeton d’API ;
- de donner une durée de validité à un jeton lors de sa création.

Cela sera enrichi par un futur greffon, permettant de définir des listes de contrôle d’accès (ACL) plus fines.
Autour du développement
Priorisation des résolutions de bogues
Lors du cycle de développement de la 4.3, nous avons travaillé à la priorisation des tickets. Jusque‐là, nos tickets pouvaient être priorisés sur une échelle de 1 à 5, qui était très peu renseignée, et donc peu utilisée. Cela conduisait à laisser de côté des bogues qui auraient dus être prioritaires. Pour remédier au problème, nous avons décidé de changer notre classification des bogues et d’organiser régulièrement une classification systématique des nouveaux tickets. Cela nous permet de prioriser la correction de bogues en toute transparence. La nouvelle classification comporte trois critères, avec des choix possibles les plus clairs et objectifs :
- visibilité utilisateur : elle désigne le type de cas d’utilisation concerné et permet de savoir s’il s’agit d’un problème courant ou rencontré uniquement dans certains cas rares ;
- criticité : désigne la gravité du problème ;
- effort : désigne une estimation de la quantité de travail nécessaire pour résoudre le problème.

De plus une étiquette (tag) « Sponsorisé » est ajouté aux tickets dont la résolution est financée par un utilisateur.
À partir de ces différents critères, un calcul de priorité est effectué, et les bogues sont ensuite traités par l’équipe en ordre de priorité décroissante. Une réunion hebdomadaire permet d’attribuer les tickets et de suivre leur résolution. Pour plus d’informations sur cette priorisation, vous pouvez consulter notre entrée de FAQ.
Par ailleurs, pour améliorer la qualité des rapports de bogues et faciliter leur résolution, nous avons aussi ajouté un modèle de rapport de bogue permettant d’identifier les informations à donner plus facilement.
Événements
Nous avons participé cette année encore au Configuration Management Camp à Gand, qui rassemble les communautés libristes de gestion de configuration et d’automatisation système. Nous avions cette année une salle dédiée et avons accueilli quatre discussions à cette occasion. BMW, un de nos utilisateurs, a fait un retour d’expérience sur son utilisation de Rudder en session principale (When Production means building Premium Cars).
Divers
Quelques informations diverses :
- l’équipe s’est agrandie, avec l’arrivée d’un nouveau développeur sur la partie « agent et politiques de configuration » ;
- en plus du manuel de référence, nous travaillons sur de nouvelles ressources de documentation, plus axées sur l’utilisation de Rudder en pratique :
- un guide de démarrage à destination des nouveaux utilisateurs, qui se basera sur un exemple de configuration sur une plate‐forme de démonstration,
- un guide de cas d’utilisation, Rudder by example,
- puis des guides par types de fonctionnalités (gestion de fichiers, interaction avec l’API, etc.) dans un second temps ;
- suite aux revues d’utilisateurs sur G2Crowd, Rudder a été classé dans leur palmarès des outils de gestion de configuration.
Et maintenant ?
Nous avons commencé à travailler sur la prochaine version majeure, la 5.0, qui apportera de nombreux changements autant à l’intérieur qu’à l’extérieur de Rudder, notamment :
- un greffon de rapport permettant l’extraction de rapports de conformité historisés ;
- de nombreuses intégrations à d’autres outils :
- Centreon,
- iTop,
- etc.
Pour en savoir plus et tester Rudder, vous pouvez :
- vous connecter à une démo en ligne pour découvrir l’interface ;
- utiliser l’environnement de démonstration basé sur Vagrant pour tester facilement l’application de configuration sur un environnement réel ;
- installer Rudder en utilisant les paquets fournis et en suivant la documentation d’installation ;
- venir participer à un atelier de découverte d’une journée, la prochaine aura lieu dans les locaux de Normation à Paris le 28 juin 2018 (bénéficiez de 50 % de réduction avec le code de réduction
LINUXFR) ; - venir discuter et poser vos éventuelles questions directement à l’équipe de développement et à la communauté Rudder par courriel, sur IRC ou sur Twitter.
Et pour ne rien manquer des annonces de nouvelles versions, prochains ateliers et événements, nouvelles ressources, actualités de l’équipe de développement, etc., vous pouvez vous inscrire à la la lettre d’information RUDDER en suivant ce lien : <http://eepurl.com/b-_wK9>.
Aller plus loin
- Site officiel du logiciel libre Rudder (883 clics)
- Atelier de découverte pratique de Rudder le 28 juin à Paris (265 clics)
- Liste complète des changements dans Rudder 4.3 (90 clics)
- Démonstration en ligne (214 clics)
# Objectif du logiciel
Posté par Yves (site web personnel) . Évalué à 1.
Si je comprends bien, Rudder est comme un Ansible (avec probablement moins de modules), avec un mode « dry-run », un paramétrage graphique à la souris et un tableau de bord de santé du parc. C’est bien ça ?
[^] # Re: Objectif du logiciel
Posté par Jonathan Clarke . Évalué à 7.
Pas vraiment. Rudder remplit une fonction similaire à Ansible, dans le sens où il gère des configurations, mais le fonctionnement est très différent : pour commencer, Rudder fonctionne avec des agents locaux à chaque machine gérée (agent léger et très performant, écrit en C), là où Ansible se connecte en SSH ou similaire pour exécuter des commandes distantes. Il en résulte une panoplie de différences, la décentralisation et l'autonomie de chaque machine notamment, la charge réseau, la capacité de passer à l'échelle sur des dizaines de milliers de noeuds, etc.
Le mode "dry-run", Rudder l'a aussi (tout comme Ansible d'ailleurs) mais Rudder va bien plus loin en remontant une vraie conformité sur chaque item. Là où un mode dry-run "essaie" tout mais ne fait rien, la conformité dans Rudder va remonter un rapport propre à chaque configuration avec un status (OK, réparé, erreur, sommairement), donc beaucoup plus fin qu'un mode dry-run. Sur une machine, ca ne change pas grand chose, certes, la puissance réside en la capacité d'agréger ces rapports pour avoir une vision d'ensemble sur un parc.
Un cas d'exemple : on veut savoir si un élément de sa politique de sécurité, disons l'auto-logout du terminal, est bien appliqué sur un parc, on crée la config dans Rudder en mode "audit", il vérifie sur tous les noeuds, dit qqch comme "OK à 96%", et là 1) on sait où on en est, et 2) on peut décider de forcer la config (passage en mode "enforce") sur les 4% restants si c'est des machines où on accepte le risque, et ainsi l'appliquer partout. Ensuite, la config est vérifiée en continu, et on a une alerte dès qu'une machine n'est pas OK.
Le paramétrage peut être graphique, oui, il peut aussi être fait en CLI ou via l'API REST complète. En pratique, on a tendance à écrire les modules plutôt en dehors de l'interface graphique, puis on assemble des modules avec leurs paramètres dans l'interface graphique. L'idée fondamentale étant de faire des modules très génériques (contenu d'un fichier, état d'installation d'un paquet, existence d'un utilisateur, etc - comme les modules d'Ansible, et oui il y en a moins, mais ca suffit dans beaucoup de cas :-) ) et de batir avec ces briques les configurations plus complexes.
Une vidéo vaut peut être mieux qu'un long discours, c'est une démo sur la version précédente, mais ca montre les concepts qui sont les mêmes : https://www.youtube.com/watch?v=_N_Xbs_yRaw
[^] # Re: Objectif du logiciel
Posté par Yves (site web personnel) . Évalué à 2.
Merci Jonathan pour ce complément d’information, qui pour moi clarifie le positionnement et le rôle (et la valeur ajoutée) de cet outil !
[^] # Re: Objectif du logiciel
Posté par Anonyme . Évalué à 6.
Du coup ça me fait plus penser au fonctionnement de Salt, qui est un outil que j'ai pas mal utilisé et que j'apprécie, mais j'ai toujours trouvé compliqué de valider des configurations avec cet outil et il est pas rare qu'on doivent s'y reprendre à plusieurs fois car un dry-run est valide mais que cela ne fonctionne pas une fois les settings appliquées, ce qui est une source de stress assez important…
Rudder semble plus aboutie de ce point de vue là.
[^] # Re: Objectif du logiciel
Posté par Noobinux . Évalué à 1.
Je n'ai pas bien saisie la différence entre Rudder et un couple d'outil comme :
=> Ansible (https://github.com/ansible/ansible) + AWX (https://github.com/ansible/awx)
Ansible nous propose la gestion de configuration tandis que AWX nous permet une interface web à celle-ci (avec stats d'exécution, mise en conformité du parc, exécution sur hôte spécifique, gestion d'accès du panel web, etc.). Si nécessaire, une modification manuel dans AWX permet un déploiement de la nouvelle configuration sur le/s hôte/s
Si quelqu'un peut m'aider à comprendre les différences clefs, merci par avance :)
[^] # Re: Objectif du logiciel
Posté par valentin.napoli . Évalué à 2.
Ansible et Rudder n'abordent pas l’automatisation de l’infrastructure avec la même approche :
Cependant, au delà de la dimension conceptuelle, il y a aussi de véritables spécificités fonctionnelles :
Après c’est peut-être un détail suivant l’utilisation mais je pense que ça peut compter à partir d’une certaine criticité et/ou volumétrie dans le parc géré : Rudder est une solution professionnelle utilisée par de nombreux clients ce qui donne au logiciel une meilleure stabilité par rapport au mode upstream d’AWX.
Dans la pratique, on découvre d’autres différences, mais pour faire une réponse pas trop longue, je pense que ce sont les principales. Au final ce qu’il faut retenir, c’est que les deux outils sont davantage complémentaires que concurrents. Une bonne partie des utilisateurs Rudder utilisent les deux outils. Il existe d’ailleurs un plugin Ansible permettant de se connecter à Rudder afin d’utiliser les groupes construits sur les données d’inventaires plus complètes que Rudder récupère.
# raspberrypi
Posté par warmup . Évalué à 0.
Hello,
Est-ce qu'une version supérieure à la 4.1.6-0 existe pour l'agent-rudder sur raspberrypi ?
Merci.
[^] # Re: raspberrypi
Posté par Fanf (site web personnel) . Évalué à 0.
Le build de l'agent sur RaspberryPI n'est encore qu'expérimentale. L'agent fonctionne pour toutes les versions récentes de Rudder, mais nous n'avons pas de plateforme de build / crossbuild continue pour l'instant (c'est un chantier en cours :), et nous créons les paquets en fonction des besoins remontés.
Si vous avez besoin de plus d'information sur le sujet, venez en discuter sur IRC (freenode/#rudder) ou autre !
# ... par rapport à d'autres outils de gestion de parc
Posté par darkjuju . Évalué à 0.
Quels sont les avantages d'une solution comme Rudder par rapport à Puppet ?
[^] # Re: ... par rapport à d'autres outils de gestion de parc
Posté par valentin.napoli . Évalué à 3. Dernière modification le 18 juin 2018 à 11:22.
C’est une vaste question qui mériterait un article à part entière tant les différences sont nombreuses. Mais afin que la question ne reste pas sans réponse ici, allons-y ! :)
--
1) Côté opérationnel
A] Conformité en continu
Rudder se distingue de Puppet sur 2 axes :
D’un point de vue fonctionnel, ça se traduit en premier lieu par une vérification en continu de la conformité, avec remédiation automatique → Puppet a récemment raccroché les wagons sur ce point, mais il reste 2 différences avec Rudder : l’une se trouve au point suivant ; l’autre est le mode “ audit “ qui permet à Rudder d’auditer un parc sur la base de l’état cible visé sans pour autant faire la moindre modification. Ce mode audit peut être défini pour l’ensemble de Rudder, comme pour une sous-partie des machines gérées et/ou seulement certaines règles.
Techniquement, ce qui permet cette vérification continue, c’est avant tout :
B] Une solution d’équipe vs un outil d’expert
En parallèle de cette orientation conformité en continu, Rudder a été conçu pour être utilisé pour l’intégralité d’une équipe IT, et pas seulement un expert en infra-as-code.
Fonctionnellement ça se traduit par :
Du coup Rudder s’adresse aussi bien :
2) Côté business
Enfin, en marge du côté opérationnel, Rudder se distingue aussi par son modèle économique plus proche de l’esprit du Logiciel Libre que du modèle à deux vitesse Open Core vs Enterprise et ses effets pervers. Rudder n’existe qu’en version libre. Des fonctionnalités à destination des très grosses structures et/ou spécifiques à des cas d’utilisation moins courants, sont disponibles dans des plugins payants.
Les fonctions centrales de Rudder comme l’interface de gestion et l’éditeur en drag-&-drop ne seront jamais rendues payantes, là où l’interface de Puppet est propriétaire.
--
Pfiou ! J’avais prévenu que ça serait long ! Au moins j’espère avoir su répondre de manière complète sur les différences avec Puppet. Après je ne connais pas aussi bien Puppet que Rudder, et je ne suis pas forcément l'évolution du produit au jour près, mais dans les grandes lignes je pense que ce sont les points sur lesquels les deux logiciels se distinguent.
Suivre le flux des commentaires
Note : les commentaires appartiennent à celles et ceux qui les ont postés. Nous n’en sommes pas responsables.