Sommaire
Introduction
Cher journal, ça fait quelque temps (première tentative de réponse en 2019…) que je me pose ces questions : existe-t-il un déphasage entre le prix des carburants à la pompe et le prix du pétrole brut ? Si oui, quelle est sa durée ? Dépend-il de la hausse ou de la baisse des cours ? En anglais on parle de "rocket and feathers effect" : les prix montent-ils comme une fusée et redescendent-ils comme une plume ?
Niveau recherche bibliographique sur ce sujet, je n'ai rien fait.
Mon analyse se cantonnera au Gazole et SP95, carburants pour lesquels les données disponibles pour la France sont continues depuis 2007.
Avertissement :
- je ne suis pas statisticien, encore moins économétricien.
- j'ai demandé un coup de main aux modèles d'IA suivants : OpenAI ChatGPT, Google Gemini et Microsoft Copilot. Pour cette étude, le premier est clairement le plus pertinent. Là où tous se valent pour de la syntaxe de base python/dataframe ou pour optimiser un peu la lecture des fichiers XML, j'ai trouvé que ChatGPT apportait vraiment une plus-value critique sur le code, sur l'analyse que je voulais mener et sur des propositions d'améliorations de méthodologie.
C'est parti !
Avant de s'attaquer aux carburants, intéressons-nous à leur origine : le pétrole brut.
Pétroles bruts et carburants raffinés
Il existe plusieurs pétroles bruts, nommés en fonction de leur origine géographique.
Les plus connus sont le Brent de mer du Nord et le WTI américain (West Texas Intermediate). La très grande majorité des bruts échangés sur les marchés financiers ont des prix indexés sur le Brent ou le WTI. À titre d'exemple il existe, entre autres, les bruts suivants : le Arab Light, le Dubai Crude, le Murban ou le Urals.
Cours des bruts
La FRED (Federal Reserve Bank of St. Louis) propose ces données alors profitons-en tant qu'elles sont disponibles pour nous autres non-citoyens des États-Unis d'Amérique :
- https://fred.stlouisfed.org/series/DCOILBRENTEU
- https://fred.stlouisfed.org/series/DCOILWTICO
Je n'ai pas cherché à automatiser la récupération de ces données, il y a une API si ça intéresse certains : https://fred.stlouisfed.org/docs/api/fred/ et là : https://fred.stlouisfed.org/docs/api/fred/v2/
Comme les choses sont bien faites™, Brent et WTI ont des cours boursiers 'très' proches (sauf à de rares occasions[1]) ce qui permet de faire le raccourci suivant sans trop d'erreur : "LE" prix du brut.

On observe des changements importants bien délimités temporellement et qu'il est facile de relier à de grands évènements :
- en 2008 : Grande Récession de 2008
- en 2020 : pandémie COVID-19
- en 2022 : début de la seconde agression de la Russie envers son voisin ukrainien (oui, il ne faut pas oublier l'annexion de la Crimée dix ans plus tôt, en 2014)…
- en 2026 : le conflit USA+Israël / Iran autour du détroit d'Ormuz.
Les cours des bruts sont ainsi une signature (d'une partie) de l'histoire géopolitique.
On observe aussi une forte augmentation de fréquence et d'amplitude du cours des bruts, ça devient vraiment chaotique ! Pas sûr que ça soit rassurant.
Carburants raffinés
Le gouvernement français met à notre disposition des archives des prix des carburants, point de distribution par point de distribution depuis 2007 ! Les données sont disponibles en Open Data : https://www.prix-carburants.gouv.fr/rubrique/opendata/
for i in $(seq 2007 2026); do wget https://donnees.roulez-eco.fr/opendata/annee/$i -O $i.zip; done
for i in *.zip; do unzip $i; doneUn peu plus de 400 Mo d'archive et 4.3 Go de xml décompressé.
On charge tout ça dans une DataFrame qui a un peu plus de 62 millions de lignes ! (N.B. : prévoyez de la RAM, chez moi ça en a pris ~22 Go pour parser tout ça)
En agrégeant par jour ça devient nettement plus raisonnable : 39000 lignes.
On a ainsi une ligne par jour avec la moyenne, le minimum, le maximum et l'écart-type.

À partir de 2016, on observe que le prix du gazole rejoint celui du sans-plomb. C'est purement un effet fiscal. On le voit d'autant mieux en faisant la différence entre les deux carburants :

Quand vous entendez nos chers commentateurs économistes parler de spread, c'est ça : la différence entre 2 indicateurs (et son évolution au cours du temps).
En comparant deux périodes de 4,5 ans autour de ce changement de fiscalité : on était en moyenne à +20 centimes sur le litre de SP95 sur la première période, contre +10 centimes sur la seconde période.
Mais revenons à nos moutons : y a-t-il des corrélations entre le prix du carburant et celui du brut.
Corrélations
Pour chercher des corrélations, il faut comparer des choux avec des choux. Pour le moment on a vu des cours de bruts en dollars US par baril et des prix de carburants en euros par litre.
La première chose à faire est de passer le prix du brut de US$ par baril en € par L en tenant compte de l'évolution du taux de change € ↔ US$. On lira au passage que le barrel oil utilisé est issu de la normalisation du volume des barils en bois utilisés par l'industrie pétrolière américaine au XIXᵉ siècle. Un baril valait 42 gallons US soit ~159 L. On se retrouve alors à comparer des carburants en €/L avec du brut en €/L. On avance, mais, en France, nos litres de carburants sont taxés !
La seconde chose à faire est de tenir compte de ces taxes (et de leurs évolutions au cours du temps bien sûr) pour deux raisons : elles constituent une part fixe et significative du prix final à la pompe, sans corrélation avec le prix de la matière première et elles évoluent au cours du temps. On est ainsi passé de la TIPP (Taxe Intérieure sur les Produits Pétroliers) introduite en 1976 à la TICPE (Taxe Intérieure de Consommation sur les Produits Énergétiques) en 2011[2], elle-même remplacée par l'"Accise sur les produits énergétiques autres que les gaz naturels et les charbons" (on n'a même plus fait l'effort de trouver un bel acronyme, APEAGNC ?). Ces dernières incluent depuis 2014 la "Taxe Carbone" ("Contribution Climat Énergie"). Enfin nous n'oublierons pas la TVA qui a pour assiette le produit hors taxe et l'APEAGNC! Bien évidemment tout ça dépend du carburant.
Bon là, il faut commencer à faire de l'archéologie parce que trouver des sources fiables sur les évolutions de ces taxes depuis 2007 est compliqué. Outre les changements de noms, il faudrait se palucher toutes les lois de finances et décrets d'applications pour obtenir les valeurs exactes. Tu t'en doutes cher journal, je n'ai pas fait ça. J'ai demandé à mes AmIes de m'en faire un résumé. Elles n'étaient pas trop en désaccord les unes avec les autres (figure) mais ça reste des pincettes à ajouter aux précautions qu'on prendra pour interpréter les résultats de l'analyse.
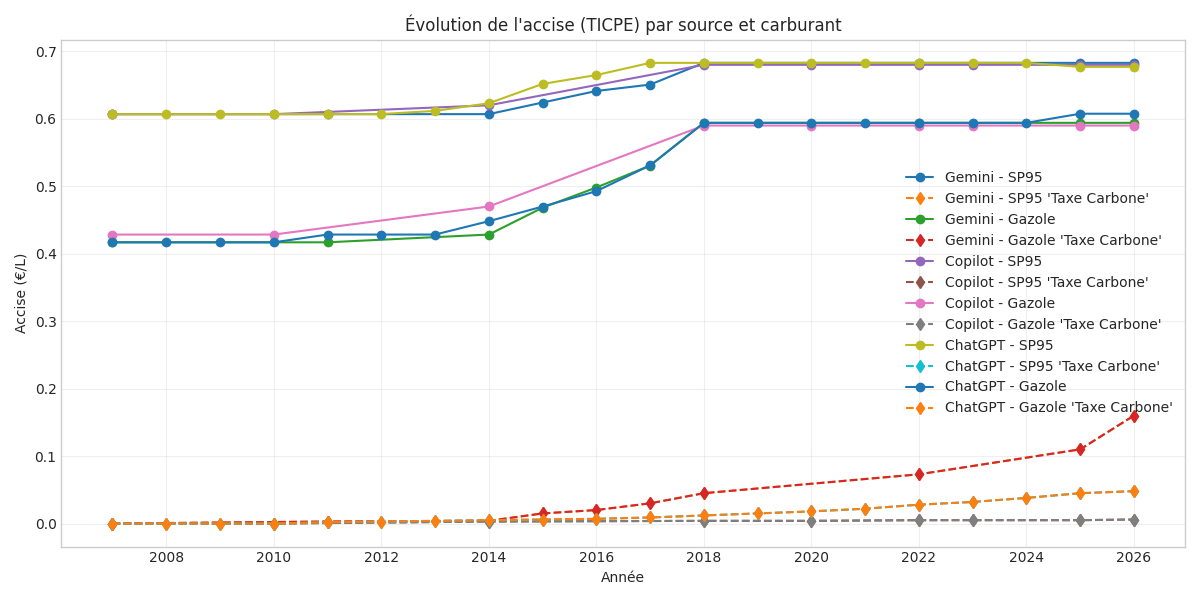{kind=link}
Par flemme, et parce que je passe déjà bien plus de temps qu'imaginé à explorer tant de subtilités, mon analyse ne retire pas les coûts de raffinage, de transport et les marges des vendeurs finaux (ou tout autre facteur que mon esprit n'imagine même pas).
Vouloir établir des corrélations sur presque 20 ans d'histoire économique, c'est osé.
Corrélation simple
En utilisant un premier modèle, on obtient le graphique suivant :

On y remarque deux choses :
- les coefficients de corrélation ne sont pas bien élevés : plus ils sont proches de 1, plus le modèle représente les données avec fidélité. Compte tenu des limites de l'analyse et de tout ce dont le modèle ne tient pas compte, il est quand même intéressant de voir une corrélation statistiquement significative.
- les coefficients de corrélation sont différents selon que le brut est à la hausse ou à la baisse. On a là une première indication d'un effet fusée / plume. Lorsque le brut est à la hausse, l'impact sur le prix du gazole est le plus important dès le lendemain. Tandis que pour un brut à la baisse, il faut attendre entre 2 et 3 jours pour voir un effet sur le prix à la pompe.
Ce modèle de corrélation simple ne prend pas en compte différents phénomènes, par exemple le fait que tout s'enchaine : la baisse du brut du jour J a un impact à partir de J+2, mais le cours du brut à J+1 peut aussi affecter les prix à J+2 (quand le Brent à la hausse) etc.
Méthode des moindres carrés ordinaire
Pour affiner, on peut utiliser une régression linéaire par moindres carrés. Ici je n'invente rien non plus, j'utilise un modèle fourni par StatsModels. Et comme on dépasse déjà les limites de mes connaissances en statistiques et que je ne veux pas raconter trop de conneries, je n'irai guère plus loin.
L'avantage de ce modèle par rapport au précédent est qu'il permet de distinguer les effets de chaque délai. Par exemple : après avoir pris en compte tous les délais jusqu'à 10 jours, est-ce que le délai au jour 2 importe toujours ?
En pratique la différence avec le modèle précédent est très faible :

On a toujours un effet majeur à J+1 en cas de hausse du brut et un effet important seulement à partir de J+2 en cas de baisse.
Un des gros avantages, c'est qu'on a maintenant des intervalles de confiance qui nous indiquent à partir de quand les changements ne sont plus significatifs. Ici on voit que à partir de J+6, la hausse du brut au jour J n'a plus d'influence alors qu'en cas de baisse, il faut attendre J+9 pour que tous les effets soient estompés.
Conclusions
Oui, cette analyse imparfaite met en évidence un effet "fusée/plume" mesurable. Avec ces données et les hypothèses retenues, le prix des carburants à la pompe monte plus rapidement qu'il ne redescend. Mais cet effet n'est pas dramatique ni outrageusement dissymétrique, on parle d'une seule journée de décalage à la hausse contre 2 à 3 jours pour que la majorité d'une baisse du brut soit répercuté en station.
J'ai une quantification temporelle de la réponse à mes questions initiales. J'ai appris des choses et découvert de nouveaux outils.
Je connaissais Jupyter-notebook et les dataframes de pandas, je me suis essayé à utiliser proprement les venv, uv pour installer n'importe quel paquet python en un éclair, ty et ruff pour trouver des bugs dans mon code avant de le lancer (non je n'ai pas d'actions chez AstralOpenAI). J'ai découvert aussi jupytext qui permet d'avoir une version texte en clair d'un jupyter notebook, de travailler dessus, surtout pour le mettre en forme automatiquement avec black par exemple, et pouvoir le réinjecter dans le notebook tout en conservant le résultat de l'exécution de chaque cellule ! Et en facilitant le versionnage.
Le jupyter notebook de cette étude est disponible ici : https://github.com/nonas/carburants.gouv.fr/blob/master/carburants_vs._crude.ipynb
Il serait intéressant de mener la même étude, soit avec le SP95, soit sur des périodes plus restreintes pour voir si les corrélations y sont plus marquées voire si elles changent. Partir du brut pour aller en station est aussi un grand écart économique pour lequel j'ai fait de nombreux raccourcis, utiliser les "spot prices de Rotterdam" qui intègrent en autres les coûts de raffinage aurait pu être plus judicieux et plus juste mais je les ai découverts en fin d'analyse (et c'est là encore tout un monde avec ses acronymes et ses subtilités).
Une dernière image pour la route :

Oui ça n'a rien à voir mais c'est mon journal !
Dans un autre style vous pouvez tester Hypercube de Nathan Fake, découvert grâce à [DEEP]Search de Laurent Garnier sur FIP.
Bisous.
Sources des données
- https://www.prix-carburants.gouv.fr/rubrique/opendata/ (Open licence)
- U.S. Energy Information Administration, Crude Oil Prices: Brent - Europe [DCOILBRENTEU], retrieved from FRED, Federal Reserve Bank of St. Louis; https://fred.stlouisfed.org/series/DCOILBRENTEU
- U.S. Energy Information Administration, Crude Oil Prices: West Texas Intermediate (WTI) - Cushing, Oklahoma [DCOILWTICO], retrieved from FRED, Federal Reserve Bank of St. Louis; https://fred.stlouisfed.org/series/DCOILWTICO
- International Monetary Fund Exchange Rate, EUR vs. USD: https://www.imf.org/external/np/fin/ert/GUI/Pages/Report.aspx?CU=%27EUR%27&EX=REP&P=DateRange&Fr=633032064000000000&To=639252640000000000&CF=Compressed&CUF=Period&DS=Ascending&DT=NA
[1] : https://fredblog.stlouisfed.org/2020/05/wti-vs-brent-oil-prices-when-and-why-do-they-diverge 🇬🇧
[2] : les acronymes ont la vie longue en France, alors que la TIPP disparaît en 2011, certains en parlent encore 15 ans plus tard pour demander qu'elle soit flottante. C'est un peu comme pour l'Assédic ANPE Pôle Emploi France Travail.
# Sekicejan
Posté par Colin Pitrat (site web personnel) . Évalué à 5 (+3/-0).
Il manque une légende à cette nimage!
[^] # Re: Sekicejan
Posté par Ysabeau 🧶 (site web personnel, Mastodon) . Évalué à 7 (+4/-0).
Apparemment : Donna Summer Bruce Sudano Giorgio Moroder Beverly Hills.jpg.
Je n’ai aucun avis sur systemd
[^] # Re: Sekicejan
Posté par saltimbanque (site web personnel) . Évalué à 5 (+4/-1).
Oui jpg vient souvent au PMU on rigole bien ensemble
[^] # Re: Sekicejan
Posté par Ysabeau 🧶 (site web personnel, Mastodon) . Évalué à 3 (+0/-0).
Ça doit être pour ça que les autres rigolent en fait.
Je n’ai aucun avis sur systemd
[^] # Re: Sekicejan
Posté par nonas . Évalué à 3 (+1/-0).
L'image est un lien vers la page wikimedia commons de l'image ;-)
J'ai beaucoup écouté l'album Once upon a time de Donna Summer, produit par Giorgio Moroder pendant que je travaillais là-dessus.
# _pull requests_
Posté par BAud (site web personnel) . Évalué à 5 (+3/-0). Dernière modification le 14 juin 2026 à 16:58.
lo, si tu veux des pull-request, il vaudrait mieux indiquer quels fichiers sont tes sources ;-)
Pour ce nourjal : https://github.com/nonas/carburants.gouv.fr/blob/master/journal.md
:de[^1]:pour les notes de bas de page : de même, il y a eu des ajouts au wiki pour préciser comment les utiliser, mais ce n'est pas appliqué o_O[^NOTE_TIPP]pour ta 2ème notePour le code1 utilisé :
Pour les nimages : https://github.com/nonas/carburants.gouv.fr/tree/master/plots
Et donc des mises à jour du README.md principal afférentes. Et je n'aurais pas mis les
.csvà la racine du projet.je reste dubitatif sur les 22 Go de RAM consommés, un parcours linéaire des données aurait dû suffire pour ne pas avoir à faire la sérialisation en mémoire, m'enfin c'est pas la 1ère fois que je vois ça en python ou avec panda :/ ↩
[^] # Re: _pull requests_
Posté par nonas . Évalué à 3 (+1/-0).
Oubli de ma part, les instructions sont claires.
Ça je me suis posé la question mais sans aller jusqu'au test sans l'espace. Je pense que la différence est suffisamment subtile pour bien insister dessus dans le wiki.
Oui le dépôt mériterait un peu de nettoyage.
Pour les 22 Go de RAM, j'ai été désagréablement surpris aussi :-/
# Point encore lu
Posté par liberforce (site web personnel, Mastodon) . Évalué à 3 (+1/-0).
… si ce n'est en diagonale, mais quitte à te mettre à plein de trucs nouveaux, tu peux tester
polars(oui, c'est du rust) pour remplacerpandaset comparer les performances. Et virer black de ta stack et utiliserruff format. C'est tout pour cette fois-ci :-).[^] # Re: Point encore lu
Posté par liberforce (site web personnel, Mastodon) . Évalué à 4 (+2/-0).
Et maintenant que c'est lu, merci pour ce nourjal intéressant nourri à l'IA intelligemment !
[^] # Re: Point encore lu
Posté par nonas . Évalué à 3 (+1/-0).
Ah oui, quitte à ne pas maîtriser pandas, autant essayer polars, merci j'avais oublié son existence.
Je regarderai pour le début du notebook, surtout les parties où je charge tout dans la dataframe et l'agrégation quotidienne qui prennent un peu de temps.
# Une raison ?
Posté par 🚲 Tanguy Ortolo (site web personnel) . Évalué à 10 (+10/-0).
Sans parler de la méthode, je m'interroge sur ce fameux effet fusée–plume. Et je me demande si je ne viens pas d'en trouver une raison, sans aller jusqu'à prétendre avoir trouvé la raison.
Vous êtes pompiste. Vous avez acheté 10 kl de carburant E10 à pas cher. Suite au déclenchement d'une guerre ou quoi que ce soit d'autre, votre grossiste commence à augmenter ses prix. Que vont faire vos clients ? Se précipiter chez vous pour remplir leur réservoir, voire des bidons, avant que vous ne montiez vos prix. Du coup, dès le lendemain vos 10 kl sont tous vendus, vos citernes sont à sec et vous devez racheter du carburant alors que d'habitude il suffit d'une livraison par semaine. Et du coup, dès le lendemain vous vous retrouvez à vendre du carburant bien plus cher.
Deux mois après, la guerre prend fin, et votre grossiste commence à baisser ses prix. De votre côté, vos citernes sont encore à moitié pleines vu que vous avez été livré il y a trois jours. Que vont faire vos clients ? Certainement pas se précipiter chez vous s'il leur reste un peu de carburant : puisqu'ils s'attendent à une baisse de prix il est plus intéressant pour eux de patienter pour en acheter plus tard. Du coup, il va vous falloir une semaine pour réussir à vendre le contenu de vos citernes à moitié pleines. Et seulement après, vous pourrez vous faire livrer du carburant moins cher et commencer à baisser vos prix.
Côté grossiste, ça doit être pareil en plus : en cas de hausse prévisible, les pompistes détaillants doivent se précipiter pour passer commande, et en cas de baisse, les commandes doivent se ralentir tout autant. Avec ce genre d'effet sur toute la chaîne, je suis même surpris que ces corrélations donnent un retard à la baisse de l'ordre d'un jour ou deux plutôt qu'une semaine entière.
[^] # Re: Une raison ?
Posté par NeoX . Évalué à 6 (+3/-0).
mais attendez, ce ne serait pas le principe de l'offre et la demande ?
[^] # Re: Une raison ?
Posté par Colin Pitrat (site web personnel) . Évalué à 4 (+2/-0).
Non. Le principe de l'offre er de la demande, c'est que le prix baisse si offre > demande et augmente si demande > offre.
Là c'est juste une différence dans les flux de sortie due aux attentes des consommateurs quand à l'évolution future des prix.
[^] # Re: Une raison ?
Posté par Tanouky . Évalué à 0 (+1/-1).
Plutôt de la spéculation de comptoir.
[^] # Re: Une raison ?
Posté par fearan . Évalué à 6 (+4/-1).
Alors ça c'est une vaste fumisterie, les gens vendent au prix auxquels ils pense pouvoir vendre, et les gens achète au prix où il estiment ce que ça vaut.
L'art du commerce, c'est trouver la borne la plus haute ne faisant pas perdre trop d'achats, et le mieux c'est si tu es en situation de monopoles ou alors juste ce qu'il faut pour pouvoir s'entendre sur les prix sans avoir besoin de se concerter.
Si tu veux la preuve que l'offre et la demande n'a que peu de rapport avec le prix final de l'objet vendu, va faire un tour sur Amazon, cherche différents articles, et change le .fr en .de, .it, .es…
Sinon plus 'sportif' va dans 2 marchés de proximité de ta ville (Monoprix, Carefour, Franprix…) peu importe l'enseigne, regarde différents produits (huile d'olive, café en grains, piment d’Espelette, chocolat, biscuits apéritifs, bière, cidre… ), note les prix au kilo, litre, et les marque (ça aide pour les comparaisons), et compare les résultats, et parfois sur les même marques ça peut être assez fort. Mais c'est rarement homogène certains articles peuvent être plus cher dans l'un, mais pour d'autre c'est l'inverse.
Il ne faut pas décorner les boeufs avant d'avoir semé le vent
[^] # Re: Une raison ?
Posté par Ysabeau 🧶 (site web personnel, Mastodon) . Évalué à 5 (+2/-0).
Ce qui influe aussi sur les prix de vente pour les commerces, ce sont aussi les loyers des locaux commerciaux qui peuvent être très élevés.
Je n’ai aucun avis sur systemd
[^] # Re: Une raison ?
Posté par fearan . Évalué à 5 (+2/-0).
T'as aussi les franchises qui prennent leur part du gâteau, mais dans ce cas ça devrait toujours être dans le même sens, pas des trucs plus chers et d'autres moins chers;
Il ne faut pas décorner les boeufs avant d'avoir semé le vent
[^] # Re: Une raison ?
Posté par Mikis . Évalué à 3 (+1/-0).
Pour éviter les comparaisons, le fabricant peut jouer sur des quantités variables. 1kg moins quelques grammes dans une chaîne, 1kg dans une autre. C'est le même produit mais pas exactement.
En électroménager, j'avais vu un fabricant qui avait une ref pour une chaîne et une ref presque identique avec un produit à caractéristiques semblables mais différentes à la marge pour une autre chaîne. C'était en 2000, ça a pas dû s'arranger depuis.
Pour ça que le "vous trouvez moins cher ailleurs produit/service identique" : on vous paye la diff et on vous offre le champagne, c'est une offre de gascon (même si j'ai réussi à l'avoir une fois).
[^] # Re: Une raison ?
Posté par Claude SIMON (site web personnel) . Évalué à 4 (+2/-0). Dernière modification le 17 juin 2026 à 15:31.
Il y a plus simple : https://www.hagglezon.com/ :-) !
Zelbinium: pour la génération qui crée, pas celle qui scrolle…
[^] # Re: Une raison ?
Posté par Axone . Évalué à 4 (+2/-0).
Je plussoie, je pense que les hausses se répercute un peu plus vite, car les automobilistes se ruent dans les stations à la moindre inquiétude. Ils veulent compléter leur plein immédiatement. Donc les stocks dans les stations doivent être renouvelés plus vite avec les nouveaux prix.
Tandis que si le carburant est sur une tendance baissière, il vaut mieux en remettre le plus tard possible, donc faire durer son plein au maximum avant de retourner à la pompe. Les stocks en station sont moins sollicités. La rotation avec les nouveaux prix prennent plus de temps.
Bien sûr, ce n'est qu'une opinion.
[^] # Re: Une raison ?
Posté par Jean-Baptiste Faure . Évalué à 8 (+6/-0).
À mon avis la principale raison est la solidité ou la fragilité de la trésorerie du détaillant, puisqu'elle fait que la vente du reste de sa citerne lui permet ou non de payer le remplissage de la suivante avec un carburant plus cher. Éventuellement en devant commander la marchandise sans connaître le prix exact qui lui sera demandé à la livraison.
Au final si le détaillant a une trésorerie qui représente 10 remplissages de cuve il est bien plus confortable que si elle ne permet qu'un peu plus d'un seul remplissage.
[^] # Re: Une raison ?
Posté par Pol' uX (site web personnel) . Évalué à 4 (+2/-0).
Ya peut être un sujet aussi lié à la réglementation de la vente à perte.
Adhérer à l'April, ça vous tente ?
[^] # Re: Une raison ?
Posté par 🚲 Tanguy Ortolo (site web personnel) . Évalué à 4 (+1/-0).
Ça, ça a moyen de tuer une station service. Si j'ai une citerne entière, achetée au prix fort, à vendre avec interdiction de le faire à perte, je n'arriverai jamais à l'écouler si mon concurrent a déjà vidé la sienne et vend désormais à un prix bien plus faible .
[^] # Re: Une raison ?
Posté par Pol' uX (site web personnel) . Évalué à 4 (+2/-0).
Pas nécessairement car même si le périmètre se réduit, il y aura toujours des clients proches en besoin de carburant, qui n'ont pas intérêt à faire 15 km de plus pour économiser 5€.
Ceci étant je ne connais pas la réglementation à ce niveau. Je présume juste que le pompiste n'est pas complètement libre de brader à bas prix un carburant payé prix fort.
Adhérer à l'April, ça vous tente ?
# sauver un châton
Posté par steph1978 . Évalué à 7 (+5/-0).
Journal très sympa.
J'ai quand même buggé sur :
Ça veut dire une machine avec 32GB de RAM. Pas trop dans mes moyens en ce moment.
Je connais bien la structure des fichiers de données car j'ai déjà joué avec par le passé. Ils peuvent être parsé en mode texte car les xml sont bien indentés.
Pour chaque par points de vente (pdv), il y a toutes les modifications de prix effectuées dans l'année : type de carburant, date, prix.
Les fichiers ne sont pas triés pas dates mais par pdv, il faudra donc rassembler les données par date avant de les dumper.
J'utilise donc le script awk suivant :
Il y a une petite gymnastique avec les clés de tableaux associatifs car MAWK ne supporte pas les tableaux imbriqués contrairement à GAWK mais est au moins deux fois plus rapide.
Je fais la glue avec le script bash suivant:
Le premier AWK permet de récupérer le contenu de la balise ouvrante XML. Pour le second on découpe les attributs XML avec le caractère
".Le script prend 54.73s pour process les 4.257GB de données et consomme en pic 3.356Mo de RAM ; oui, moins de 4 mégaoctets de RAM. Le script AWK est bien le facteur limitant (pas le premier awk ni le unzip).
Pour produire six fichiers - un par type de carburant - de 7000 (=19*365) lignes chacun, pour 280Ko en tout, qu'il faudra alors charger dans pandas. J'imagine que cela ne prendra que quelques dizaine de Mo de RAM.
Il faudra encore réaliser l’agrégation par semaine car le script AWK ne le fait pas. Il n'est là que pour diminuer drastiquement la quantité de données à charger dans Python.
[^] # Re: sauver un châton
Posté par nonas . Évalué à 4 (+2/-0).
Pour ma défense, j'ai de la chance : des gens trop gâtés à $dayjob jettent (trop) régulièrement des machines dans la benne. Mon PC actuel est un "vieux" Dell avec un Core i5-7500 qui, au fil des ans et de mes trouvailles heureuses, est passé de 8 à 16, puis récemment à 32 Go de RAM. Franchement à part pour ce genre de trucs gourmands (parce que pas sérialisés), je n'en ai pas besoin. Là j'ai 1,6 Go de RAM utilisé (y compris les caches). J'ai même hésité à un moment donné à revenir à 8 Go de RAM mais comme je n'ai pas observé de différence significative de conso électrique, j'ai laissé en l'état.
Oh, ce journal ne me dit rien ! Je vais le lire avec grand intérêt ! J'avais commis il y a quelques années un journal aussi porté sur la cartographie : https://linuxfr.org/users/nonas/journaux/communes-de-france-finissant-par-ville
Alors là, il va me falloir un peu de temps pour comprendre ces scripts AWK. J'en avais fait des biens plus simples il y a longtemps pour un autre truc mais c'est loin de mon niveau actuel tout ça ^
Et oui, c'est le gros avantage du traitement ligne par ligne.
Merci !
[^] # Re: sauver un châton
Posté par steph1978 . Évalué à 3 (+1/-0).
Je me rappelle de ce journal sur les villes en ville. Il a fait partie d'une série de journaux sur les cartes en générale ; très cool.
J'avais essayé de résumer ses principes dans ce journal ; je ne sais pas si ça aide.
Cela parait abscons au premier abord car il y a une partie implicite : on ne voit pas les boucles ; il y a des variables non initialisées un peu partout. Mais une fois qu'on a le modèle mental en tête, la syntaxe est très simple et, pour ma part, je n'ai que rarement besoin d'aller voir la doc.
C'est peut être le même manque de pratique qui m'oblige à avoir la doc de Pandas sous les yeux quand j'en fait.
Pour moi, AWK, c'est vraiment la botte secrête quand on a masse de données texte à processer.
[^] # Re: sauver un châton
Posté par BAud (site web personnel) . Évalué à 3 (+1/-0).
même si ce n'est pas utile, autant les mettre à 0 dans un bloc
BEGINce qui permet notamment de décrire leur utilité. Par ailleurs, j'ai tendance à préfixer mes variablesvNomVariablem'étant fait avoir plus d'une fois avec des mots-clefs réservés :Davant un
awkun peu élaboré, je remonte en commentaire la structure du fichier traité (j'allais dire parsé :p) ce qui permet de documenter les traitements effectués pour chaque type de ligne et le blocENDdocumente de lui-même les résultats calculés/attendus (sauf quand leawksert d'entrée à un autre traitement ligne à ligne).[^] # Re: sauver un châton
Posté par steph1978 . Évalué à 3 (+1/-0).
Pareil. AWK est data driven, si on connais pas le format de l'input, difficile de comprendre le programme.
Envoyer un commentaire
Suivre le flux des commentaires
Note : les commentaires appartiennent à celles et ceux qui les ont postés. Nous n’en sommes pas responsables.