
Pendant l’année scolaire 2016-2017, j’étais en dernière année d’école d’ingénieurs (l’ENSICAEN). J’ai donc fait un stage de fin d’études (à Orange, en France), avec le rapport qui va avec. J’ai fait un logiciel libre qui a été publié. En conséquence, il m’a paru logique de publier mon rapport, après avoir enlevé quelques parties (remerciements, présentation du collectif de production, conclusion personnelle, etc.) et fait de petites retouches pour qu’il soit cohérent avec ce nouveau format et la visibilité qui va avec. Cela permet de présenter plus largement ce que j’ai fait, tout en expliquant le pourquoi et comment, ce qui pourrait servir à d’autres personnes.

Sommaire
- Le sujet
- État de l’art
-
La réalisation du projet
- Les outils utilisés
-
Le résultat
- Comparaison avec un proxy classique
- « Proxifier » une URL
- Récupérer une ressource Web
- La gestion du HTML
- La gestion du CSS
- La gestion du HTTP
- Gérer les formulaires Web
- La gestion du JavaScript
- La configuration
- Enregistrement des données
- Conversion des données
- L’API Web
- L’interface graphique
- L’installation facile
- Le paquet Debian
- Possibilités pour améliorer les performances
- Et après ?
- Pourquoi ce nom ?
- Conclusion
Le sujet
Celui qui a été mon tuteur de stage participe activement au développement d’un outil de test de mesure des performances à travers le réseau, qui s’appelle CLIF et qui est présenté plus loin dans cet article. Le cas le plus courant est le test pour le Web, avec le protocole HTTP et sa version chiffrée HTTPS. Pour faciliter l’usage pour ce cas commun, il faut que créer un scénario de test pour ce dernier soit aisé.
Il existait déjà une solution : un proxy pouvait être configuré dans le navigateur Web pour intercepter les flux réseau et ainsi enregistrer les informations pertinentes dans le format adéquat (basé sur XML) pour rejouer une session Web avec CLIF. Configurer un proxy dans un navigateur Web peut être difficile pour certaines personnes ou perçu comme tel. De plus, le proxy ne gère pas le HTTPS (qui est de plus en plus courant), bien qu’il aurait été possible d’en ajouter la gestion, cela aurait nécessité d’ajouter un certificat dans le navigateur Web. Mon tuteur voulait un outil plus simple à utiliser et qui gèrent le HTTPS, d’où ce stage.
Comme CLIF, l’outil réalisé devait être du logiciel libre sous licence GNU LGPL en version 3.
État de l’art
Outils de test de charge
La liste n’est pas exhaustive, mais il y a un article sur Wikipédia en anglais si l’on en désire une qui cherche à l’être. Cette partie a pour intérêt de présenter rapidement des outils cités plus loin dans l’article présent et de mettre en perspective le programme de mon tuteur de stage.
Apache JMeter
JMeter est un logiciel libre de la Fondation Apache. Il est très populaire et empaqueté par au moins Debian et Trisquel GNU/Linux. Pour définir un test de charge, il faut lui soumettre un fichier XML. Il est extensible avec des modules complémentaires.

Gatling
Gatling est un logiciel de test de charge, avec un focus sur les applications Web. Il est sous licence Apache 2.0, donc libre. Il est écrit en Scala. Il est empaqueté par au moins Debian et Trisquel GNU/Linux.
Selenium
Selenium est un logiciel pour automatiser la navigation Web à travers un navigateur Web. Il peut donc servir à faire des tests, mais aussi automatiser des tâches administratives se faisant via le Web. Il est libre via la licence Apache 2.0.
Tsung
Tsung est un logiciel de test de charge distribué. Il gère différents protocoles (dont HTTP, XMPP, LDAP et MQTT). Il est libre sous licence GNU GPL version 2.0. Le langage de programmation utilisé est Erlang. Il prend en entrée un fichier XML. Il est disponible sous forme de paquet dans au moins Trisquel GNU/Linux et Debian.

Locust
Locust a la particularité d’utiliser des scripts en Python pour définir le comportement des utilisateurs virtuels, alors que les autres outils utilisent généralement du XML et/ou une interface graphique. C’est un logiciel libre sous licence « MIT ».

The Grinder
The Grinder est un cadriciel (framework) pour le test de charge. Il est adapté pour le test distribué sur plusieurs machines. Il est libre et écrit en langage Java.
Taurus
Taurus a pour but de cacher la complexité des tests fonctionnels et de performance. Il fait cela en étant une enveloppe pour JMeter, Gatling, Locust, Grinder et Selenium WebDriver. Il prend en entrée un fichier au format YAML. C’est un logiciel libre sous licence Apache 2.0.

CLIF
CLIF est un logiciel libre initié, piloté, et maintenu par celui qui a été mon tuteur de stage (Bruno Dillenseger). C’est un acronyme récursif pour « CLIF is a Load Injection Framework ». Ce projet est hébergé par le consortium OW2. Il est écrit dans le langage de programmation Java. Il a une interface en ligne de commande et une interface graphique sous forme de module complémentaire pour Eclipse. Il propose plusieurs manières de définir un test de charge, comme cela est expliqué dans une sous‐sous‐section (de cet article) partiellement dédiée. Il n’y a pas de paquet Debian, notamment à cause des nombreuses dépendances et d’au moins une dont les sources n’auraient pas été retrouvées.

CLIF permet de déployer des injecteurs de requêtes répartis pour mesurer les temps de réponse. Il permet également de déployer des sondes afin de mesurer la consommation des ressources (processeur, réseau, mémoire, disque, etc.). Son environnement de scénario ISAC offre une façon formelle de définir les scénarios sous forme de comportements d’utilisateurs virtuels et d’une spécification du nombre d’utilisateurs virtuels actifs de chaque comportement au cours du temps. CLIF a été spécialement conçu pour être rapidement adaptable à toute sorte de cas de test (un assistant Eclipse permet de définir ses propres modules complémentaires pour intégrer de nouveaux protocoles ou de nouveaux jeux de données), y compris des hauts niveaux de charge (comme des centaines d’injecteurs et des millions d’utilisateurs virtuels). En pratique, CLIF est utilisé pour des tests de tenue en charge, mais également pour des tests fonctionnels, des tests en intégration continue et de la supervision de qualité d’expérience utilisateur, notamment via son module complémentaire pour Jenkins.
Le code source est sur l’instance GitLab d’OW2, à part le module complémentaire pour Jenkins qui est sur GitHub. CLIF est aussi disponible sur la forge historique d’OW2 (qui propose des versions compilées).
Loads et Molotov
Loads et Molotov sont libres et écrits en langage Python. Ils permettent d’écrire des tests unitaires. Loads est développé et testé sur Python 2.6 et 2.7, tandis que Molotov nécessite Python 3.5 ou plus.

HPE LoadRunner
HPE LoadRunner est un logiciel privateur de test de charge, qui ne fonctionne complètement que sous Microsoft Windows. Il peut être étendu via des formats d’autres outils (comme JMeter) et des scripts dans différents langages (comme C et Java). Sa première version date de l’an 2000, il est depuis toujours amélioré, ce qui lui a permis d’acquérir une place importante dans le domaine du test de charge.
megaLOAD
megaLOAD est présenté comme étant une plate‐forme en ligne de test de charge qui serait facile à utiliser et capable de monter à l’échelle. Il aurait été spécialement créé pour tester les services de type back‐end ayant vocation à être très robustes. Il est fait par Erlang Solutions. Il gère HTTP et serait suffisamment extensible pour gérer n’importe quel protocole. Il serait possible de l’utiliser via un navigateur Web et/ou une interface de programmation RESTful. Il est disponible sur AWS (Amazon Web Services).
Siege
Siege est un outil libre pour tester la capacité de charge des implémentations des protocoles HTTP(S) (version 1.0 et 1.1) et FTP. Il est écrit en langage C et fonctionne sur divers systèmes d’exploitation POSIX (comme GNU/Linux et des BSD récents, mais pas Windows). Il est libre sous la licence GPL en version 3.0.
Outils de capture d’utilisation Internet
Différentes organisations proposent des services Web pour l’injection de charge. Certaines d’entre elles proposent un outil pour facilement capturer une session d’usage du réseau, ce qui permet ensuite de la rejouer facilement.
On pourrait naïvement penser que tcpdump, Wireshark ou Scapy sont de bons candidats sans rien faire. Ce serait vrai si les communications passaient toutes, ou au moins une vaste majorité, en clair sur les réseaux et que cela n’était pas amené à changer. En effet, elles sont de plus en plus chiffrées (avec une accélération depuis 2013 suite aux révélations d’Edward Snowden), ce qui permet de « garantir » (par les mathématiques) la confidentialité de ce qui est chiffré (il y aura toujours un minimum de méta‐données non chiffrées). Il faut donc trouver un moyen de contourner le chiffrement quand il y en a, ce que tcpdump, Wireshark, et Scapy ne font pas automatiquement. De plus, ces derniers montrent une quantité de détails techniques inutiles pour l’individu (dans notre contexte) et qui pourraient le perturber (par peur de l’inconnu et/ou la difficulté à percevoir ce qui est pertinent).
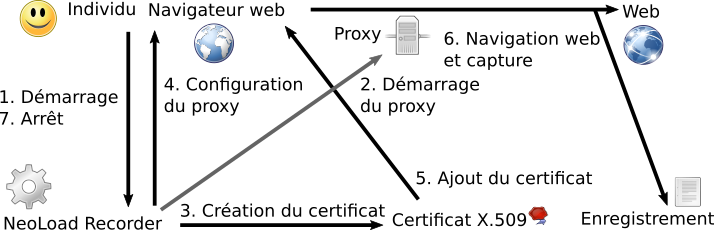
NeoLoad
NeoLoad Recorder est une application qui enregistre un parcours utilisateur fait à travers un proxy. Pour cela, il crée un proxy sur la machine sur laquelle il est exécuté. Ensuite, il génère un certificat X.509 qui va servir à déchiffrer les échanges chiffrés via TLS. Puis, il démarre Firefox dans lequel il faut configurer le proxy et ajouter le certificat si on souhaite enregistrer les communications chiffrées via TLS. Après cela, il n’y a plus qu’à naviguer. Une fois que l’on veut arrêter, il faut penser à enlever le proxy (mais on s’en rendra vite compte si on l’oublie) et ne plus faire confiance au certificat (ce qui ne sera rappelé par aucune erreur).
Cette solution technique est problématique si l’on doit passer par un proxy pour accéder à un réseau sur lequel le site Web à tester est accessible. Techniquement, il est écrit en Java. Les données sont enregistrées dans un format inconnu et non trivial.
HPE StormRunner Load
HPE StormRunner Load est un service distant pour faire du test de charge et en analyser les résultats. Il est basé sur du logiciel privateur et se manipule via une interface Web. Pour faciliter son usage, divers outils (non libres) sont mis à disposition.
Pour rendre aisé la capture de la navigation Web, il propose deux outils : TruClient Lite et TruClient Standalone. Ils ont pour but de capturer (directement) ce qui se passe dans un navigateur Web (donc sans proxy externe et sans certificat pour le HTTPS). TruClient Lite est un module complémentaire pour Chromium (et donc son principal dérivé Google Chrome), qui utilise les paramètres de proxy du navigateur Web. TruClient Standalone est un logiciel (fonctionnant uniquement sur Windows) qui peut au choix se baser sur les moteurs de Firefox (Gecko), Chromium ou Internet Explorer, mais également simuler un mobile ou une tablette (en configurant correctement la résolution du navigateur Web et son agent utilisateur), il prend les contrôles sur le proxy du navigateur Web. L’absence de contrôle sur le proxy est problématique si l’on doit passer par un proxy pour quitter un réseau interne, mais il est possible de lui indiquer un proxy après que le script soit généré. Ils enregistrent les clics sur les boutons avec leurs intitulés (même s’ils ne sont pas des liens) et se basent sur l’intitulé des boutons pour naviguer et pas sur les URL, ce qui est pratique si les références des liens changent. Ils permettent également de rejouer (automatiquement) un script enregistré avec une visualisation graphique, cependant ils sont perdus s’ils essayent de rejouer mais que le texte du bouton n’est pas le même (par exemple à cause de la langue par défaut différente en fonction du navigateur Web).
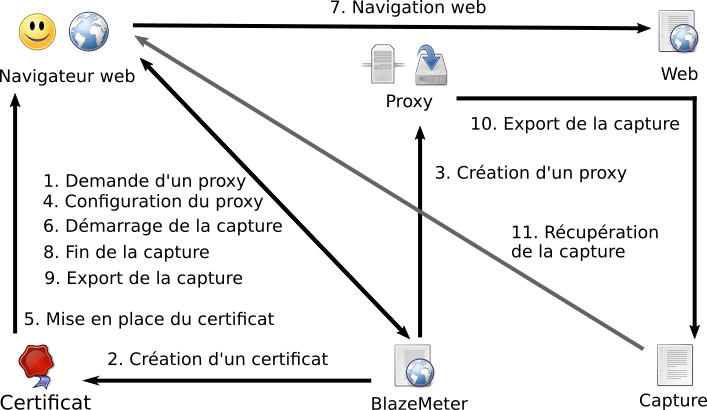
BlazeMeter
BlazeMeter est une plate‐forme SaaSS Web. Il peut réaliser des tests de charge et montrer des statistiques (en temps réel) qui en résultent. Il propose une API Web pour automatiser les tests, par exemple dans le cadre de l’intégration continue (via Jenkins ou un autre outil similaire). Il utilise divers logiciels libres (dont JMeter, Gatling, et Taurus) et gère donc leurs formats de données.
Pour simplifier les tests Web, un outil de capture de session Web est proposé, BlazeMeter Proxy Recorder. C’est malheureusement du logiciel privateur. On peut le tester gratuitement pendant un mois. Pour l’utiliser, il faut s’inscrire et l’activer. Ensuite, il faut aller dans son interface, ce qui crée un proxy (sans intervention du testeur ou de la testeuse) et un certificat X.509 (souvent appelé d’une manière réductrice certificat TLS). Pour enregistrer ce que l’on fait via un client Web, il faut activer le proxy (via un simple bouton) et configurer ce dernier dans notre client Web. Si l’on souhaite que les communications chiffrées soient enregistrées, il faut ajouter un certificat qui va permettre au proxy de déchiffrer avec une de ses clefs privées (au lieu d’une clef privée du service Web consulté). Au fur et à mesure de la navigation (via le proxy), l’interface graphique de BlazeMeter Recorder montre ce qu’il a capturé. Pour finaliser une session, il suffit de cliquer sur un bouton (de l’interface Web). On peut ensuite avoir le résultat sous divers formes (URL pour BlazeMeter, fichier JMeter, fichier pour Selenium WebDriver ou fichier pour Taurus).
SOASTA Cloud Test
SOASTA Cloud Test est un SaaSS Web pour le test de charge et l’analyse des données (en temps réel) qui en sont issues. Parmi les analyses qu’il propose, il a l’originalité de proposer une comparaison du temps de chargement et du revenu généré sur une période. Il permet de choisir où seront géographiquement les utilisateurs virtuels d’un test. Il propose une interface en trois dimensions avec les flux réseaux qu’il génère sur une carte de la Terre, dont l’intérêt est probablement discutable, mais cela peut être pertinent pour se faire payer le service par un·e commercial·e. Il peut importer des fichiers JMeter.
Contrairement à certains de ses concurrents, son outil de capture d’usage du réseau fonctionne sur plusieurs protocoles Internet (temps des connexions TCP, DNS, TLS, HTTP, etc.). C’est une machine virtuelle (sous CentOS) qui fonctionne avec VMware Player, ce qui est très lourd (en termes de puissance de calcul, de mémoire vive et de place dans la mémoire persistante, puisque le disque de la machine virtuelle fait 15 Go). Ce choix technique le réserve à des informaticien·ne·s ayant du temps ou des personnes ne voulant pas se limiter au Web.
La réalisation du projet
Les outils utilisés
Les outils pour le développement lui-même
- système d’exploitation : Debian GNU/Linux 9 Stretch (qui, devenu stable pendant mon stage, inclut PHP 7, et est vastement utilisé) ;
- éditeur de code : GNU Emacs (parce qu’il ne nécessite pas de souris et qu’il est beaucoup plus léger qu’un environnement de développement intégré) ;
- langage de programmation : PHP 7 (qui a une librairie standard fourni pour le Web, permet la déclaration de type sur tous les types non objets, et a des avantages de facilité d’installation pour les applications se basant dessus comme cela est expliqué dans la partie qui est dédiée à ce sujet).
Les outils pour gérer le développement
- gestionnaire de versions : Git (« le gestionnaire de contenu stupide » (d’après son manuel) est un logiciel libre de gestion de versions décentralisé, libre, performant, et populaire) ;
- forges logicielles :
Les outils pour les tests
Outils de tests
- outils de tests génériques (pour des choses simples comme le nombre maximal et la taille maximale des lignes des fichiers) :
- outils de tests pour PHP :
- PHPMD (PHP Mess Detector), un équivalent de PMD pour PHP, qui permet de prévenir quand le code contient de potentiels problèmes,
- PHPCDP (PHP Copy/Paste Detector), qui détecte les copier‐coller pour inciter à factoriser le code plutôt qu’à le dupliquer,
- PHP_CodeSniffer, pour alerter que la manière, préalablement définie, d’écrire le code n’est pas suivie,
- PHPUnit, pour les tests unitaires (en version 5, parce que c’est la version fournie par Debian 9 Stretch) ;
- outils de tests pour JavaScript :
- Closure Compiler, qui permet notamment de vérifier la syntaxe et la cohérence des types en se basant sur des annotations au format JSDoc ;
- outils de tests pour XML :
- xmllint (du projet GNOME),
- processeurs XSLT :
- xsltproc (du projet GNOME),
- Apache Xalan,
-
Saxon XSLT (uniquement les versions libres, c’est‐à‐dire dans Debian 9 :
libsaxon-java,libsaxonb-java,libsaxonhe-java) ;
- outils de tests pour YAML :
Intégration continue (pour exécuter automatiquement des tests quand des modifications ont été validées)
- Jenkins, avec le greffon Travis YML (pour mettre les tests dans un fichier versionné plutôt que dans l’interface graphique) ;
- GitLab CI (qui utilise aussi un fichier versionné au format YAML).
Les outils « annexes »
- automatisations diverses : make ;
- génération d’une documentation : Doxygen avec Graphviz (pour les graphiques) ;
- paquets Debian : devscripts et dh-make.
Le résultat

Comparaison avec un proxy classique
Un proxy classique est légèrement plus dur à utiliser. En effet, il faut que l’utilisateur ou utilisatrice configure un proxy. De plus, pour les échanges chiffrés, il faut ajouter un certificat.
Néanmoins, un proxy classique a un énorme avantage, il est techniquement plus simple, puisqu’il fait moins de choses, et est donc bien plus performant. En effet, le proxy que j’ai réalisé doit détecter puis analyser, entre autres, le HTML et les CSS, et enfin potentiellement les modifier, ce qui nécessite une puissance de calcul non négligeable si plusieurs agents l’utilisent en même temps.
« Proxifier » une URL
Mon proxy n’est pas un proxy « classique », il change les URL pour qu’elles pointent toutes vers lui, c’est ce que l’on peut nommer la « proxification » d’URL. En simplifiant, cela revient à ajouter un préfixe à l’URL. Techniquement, le préfixe est une référence du proxy (nom de domaine, adresse IP, ou nom purement symbolique comme localhost), puis la page qui « proxifie », et enfin le ou les différents paramètres GET à passer à la page.
Il y a un paramètre obligatoire qui est l’URL de la page à « proxifier ». Celui‐ci peut contenir des caractères illégaux comme valeur de paramètre GET (comme un point d’interrogation « ? » ou une esperluette « & »), il faut donc encoder ce paramètre au moment de la « proxification », et le décoder au moment de son usage. Cela est fait avec les fonctions PHP urlencode et urldecode (pour lesquels il existe des équivalents en JavaScript).
Il y a aussi deux paramètres GET facultatifs. Ils ont pour nom proxy-url et proxy-port et permettent d’indiquer à mon proxy d’utiliser un proxy classique (en spécifiant a minima une URL et potentiellement un numéro de port). Il y a d’autres moyens pour cela, mais ce moyen est prioritaire sur les autres. Si au moins un est indiqué, il faut le(s) propager à toutes les URL à « proxifier ».
Récupérer une ressource Web
Un proxy réseau sert d’intermédiaire pour récupérer une ressource. La problématique est banale, mais nécessite néanmoins un peu de temps pour être gérée correctement.
La première approche que j’ai utilisée est d’utiliser la fonction file_get_contents. C’est une fonction de haut niveau qui prend en entrée obligatoire le chemin vers une ressource (du système de fichiers ou via le Web), et retourne le contenu si elle a réussi à l’obtenir. C’est très facile d’emploi, cependant elle a un gros manque : elle ne récupère pas les en‐têtes HTTP. Or, elles peuvent être pertinentes pour rejouer une session Web (ce qui, pour rappel, est la finalité indirecte de mon proxy). Il fallait donc proposer un autre moyen activé par défaut si disponible.
Il y a une commande et une bibliothèque associée pour récupérer, entre autres, une ressource sur le Web qui est très connue et a de nombreuses options : il s’agit de curl. C’est libre et existe depuis longtemps (la première version date de 1997), ce qui explique au moins en partie qu’il y ait des fonctions pour utiliser curl dans la bibliothèque standard de PHP. Dans les archives officielles de Debian, il est dans le paquet php-curl, qui n’est pas une dépendance du paquet php, probablement pour mettre une installation minimaliste de PHP quand toute la bibliothèque standard du langage n’est pas nécessaire.
Une application Web ne se sert pas nécessairement que de l’URL pour définir (et potentiellement générer) la ressource à envoyer. En effet, un ou des en‐têtes HTTP de la requête peuvent être utilisés. Il a donc fallu faire suivre les en‐têtes du client Web envoyés au proxy au service Web « proxifié ». Cela a pu être fait avec les deux méthodes de récupération de ressources.
Certaines URL commencent par //, ce qui indique qu’il faut deviner quel protocole utiliser. Le moyen employé pour gérer ce cas est de faire d’abord une requête en HTTPS (la version sécurisée de HTTP), puis renvoyer la réponse si elle est non nulle, sinon renvoyer la réponse de la requête en HTTP.
Mon proxy peut nécessiter de passer par un proxy réseau non transparent pour accéder à Internet ou un autre réseau IP. C’est le cas dans un nombre non négligeable d’organisations. Or, certaines applications faites en interne peuvent n’être disponibles qu’en externe et le Web regorge d’exemples pour tester mon proxy. Il fallait donc que mon proxy puisse récupérer une ressource en passant par un proxy réseau non transparent. Cela a été implémenté avec les deux méthodes de récupération de ressources et il y a plusieurs manières de configurer un proxy (paramètres HTTP GET, cookies, et fichiers .ini).
La gestion du HTML
Il faut « proxifier » chaque URL d’un document HTML. Le HTML se manipule facilement via DOM et peut être parcouru avec XPath. Il paraît donc assez simple de gérer le HTML. Ça l’est… dans la majorité des cas, mais quelques cas rares compliquent les choses.
Dans les cas triviaux, on peut citer (avec l’expression XPath) : des liens avec a@href, des images avec img@src, les scripts avec script@src, les frames avec frame@src, des vidéos avec video@src, et d’autres. Mais comme nous allons le voir, le HTML est plus compliqué que cela.
Démarrons avec un cas méconnu si l’on a appris le HTML récemment, car notoirement obsolète : l’attribut background. Il permet de définir un fond avec l’URL d’une image pour un élément HTML. Pour séparer la structure de la forme, il faudrait utiliser du CSS. Mais il reste de veilles pages Web et des personnes n’ayant pas mis à jour leurs connaissances, il a donc fallu gérer ce cas. Cet attribut n’est valide que sur //html/body, mais en pratique certains sites Web l’utilisent sur d’autres éléments (comme http://www.volonte-d.com/) et au moins Firefox prend en compte ce cas non standard, qu’il a fallu gérer.
Poursuivons avec un cas inverse, que l’on ne connaît bien que si l’on a des connaissances à jour : les images ! En effet, il y avait un temps où il y avait uniquement img@src. Cependant pour optimiser la bande passante et avoir une image matricielle d’une taille adaptée, il est maintenant possible de proposer plusieurs URL pour différentes tailles et formats. La balise img peut maintenant avoir un attribut srcset, qui contient une ou plusieurs URL séparées par des virgules et avec des indications de la qualité (par exemple <img srcset="img1.png 1x, img2.png 2x" />). Il y a également la balise picture qui peut contenir une ou plusieurs balises source qui peuvent avoir un attribut src ou srcset (//html/body/picture/source@srcset a la même syntaxe que //html/body/img@src).
La naïveté peut laisser penser que les liens sont triviaux à gérer, c’est presque le cas. Les liens commençant par http:// et https:// sont les plus courants et il faut les « proxifier », mais il y a d’autres cas. Tout d’abord, il n’y a pas que HTTP et HTTPS, il y a d’autres protocoles dont il peut y avoir des références sur le Web et qui ne sont pas gérés par mon proxy, le plus courant étant probablement l’historique FTP (File Transfer Protocol). De plus, il y a des liens sans protocole pour l’attribut href. En effet, il y a des liens d’actions (qui ne doivent pas être « proxifiés »), pour le courriel avec mailto:, pour le téléphone avec tel: (défini dans la RFC 3966), pour le JavaScript avec javascript: (malgré qu’il y ait l’attribut facultatif onclick et un événement associé en DOM 2), et pour une ressource d’un réseau pair à pair avec « magnet: ». Il y a également des liens avec un protocole implicite ! Ils commencent par // et les clients Web les remplacent par https:// ou http:// ou essayent l’un puis l’autre, il faut donc les « proxifier ».
Rediriger une page Web peut se faire via HTTP, mais aussi en HTML. L’intérêt de la méthode en HTML est de pouvoir rediriger après un certain temps (en secondes) et potentiellement uniquement s’il n’y a pas de prise en charge de JavaScript (en utilisant la balise noscript pour faire cette condition). Cela se fait avec une balise meta dans //html/head (et sans autre parent) en indiquant un temps et potentiellement une URL (par exemple <meta http-equiv="refresh" content="5" /> ou <meta http-equiv="refresh" content="0; url=https://example.net/" />). Il faut donc chercher ce genre de balise (par exemple avec /html/head/meta[lower-case(@http-equiv)='refresh' and contains(lower-case(@content), 'url=')] en XPath 2.0), puis extraire l’URL, ensuite la « proxifier », et enfin changer la valeur de l’attribut tout en conservant le temps.
Pour utiliser du CSS dans du HTML, il y a plusieurs possibilités. La méthode la plus utilisée et recommandée est de faire référence à un ou plusieurs fichiers via une balise meta avec un attribut rel avec la valeur stylesheet en indiquant l’URL comme valeur de l’attribut href. On peut également vouloir inclure du CSS dans le HTML, ce qui est une mauvaise pratique, mais elle est toujours permise par les navigateurs Web. Il y a deux moyens pour cela : la balise style (/html//style[not(@type) or lower-case(@type)='text/css'] en XPath 2.0) et l’attribut style (/html/body[string(@style)] | /html/body//*[string(@style)]). Il faut donc récupérer le CSS, puis le « proxifier » et ensuite mettre la version « proxifiée » dans la balise.
La gestion du CSS
Je n’y avais pas pensé au début, mais il peut y avoir des URL dans du CSS. Elles peuvent, par exemple, servir pour définir un fond avec une image, inclure un autre fichier CSS, ou importer une police d’écriture (depuis CSS3 avec @font-face). Puisque le CSS sert pour la mise en page, il n’est pas négligeable et a donc du être géré.
J’ai identifié deux situations où des URL sont utilisées dans du CSS. La première et la plus courante est avec la « fonction » url en tant que valeur d’une propriété (par exemple background-image: url(image.png);) Le paramètre peut contenir des espaces avant et après. De plus, il peut être entouré d’un séparateur (soit un guillemet simple soit un double guillemet, heureusement que les formes valides en ASCII sont prises en compte). Le deuxième cas est avec l’instruction @import. Elle peut prendre directement une URL (avec les mêmes séparateurs que la « fonction » url) (par exemple @import "style.css";) ou via la « fonction » url (par exemple @import url(style1.css);).
Même avec la version 7 de PHP (une version récente d’un langage de programmation orienté Web), il n’y a pas de manipulateur lexical pour CSS dans la bibliothèque standard. Plutôt que d’ajouter une dépendance potentiellement non maintenue sur le long terme, j’ai écrit du code pour mon cas particulier. Cela a été motivé par le fait que CSS continue d’évoluer et qu’une avancée de ce dernier pourrait casser le fonctionnement d’un analyseur lexical. Néanmoins mon code souffre d’une limitation : il analyse le CSS ligne par ligne, or la valeur d’une propriété peut être définie sur plusieurs lignes (mais c’est peu courant, notamment avec l’usage de programmes pour réduire la taille d’un fichier CSS comme clean-css et YUI Compressor). De plus, mon code ne « proxifie » pas toutes les URL sur certaines lignes longues pour une raison inconnue. Un analyseur syntaxique de CSS pourrait être utilisé pour « proxifier » toutes les URL (puisque mon code ne gère pas tous les cas), comme PHP-CSS-Parser de sabberworm, cssparser de Intekhab Rizvi, ou celui de Hord (pour lequel Debian a un paquet). Une option pourrait être ajoutée pour désactiver l’analyseur syntaxique au profit de mon code s’il venait à émettre une erreur fatale à cause d’un cas non géré (potentiellement nouveau) de CSS ou d’une approche moins laxiste que les navigateurs Web (qui ont tendance à vouloir gérer à tout prix du code même non valide).
La gestion du HTTP
Hormis la ressource demandée par une requête HTTP, il peut y avoir au moins une URL pertinente à « proxifier » (mais, cette fois, à la réception d’une requête et pas en modifiant préalablement les éléments pouvant en engendrer). Un cas a été identifié : l’en‐tête Location. Il permet d’indiquer une nouvelle URL pour une ressource. Expliqué autrement, il sert pour faire une redirection. C’est trivial à gérer si l’on a déjà le nécessaire pour « proxifier » une URL. En effet, chaque champ d’une requête a un intitulé et une valeur séparée par « : » et sur une seule ligne. C’est donc très simple à analyser et, par extension, de créer une structure de données pour le HTTP.
La gestion du HTTP ne s’arrête néanmoins pas là. En effet, un serveur Web répond à des requêtes HTTP, or le but de mon stage (et du projet qui en découle) est de rejouer une session Web. Il faut donc a minima enregistrer les URL demandées en extrayant chacune du paramètre GET correspondant. De plus, un serveur Web ou une application peut répondre différemment en fonction des en‐têtes HTTP (heureusement, sinon aucun logiciel ne les utiliserait et ils seraient donc inutiles). Il y a donc un intérêt potentiel à les stocker (pour pouvoir reproduire exactement une session Web) et en enlever certains (que l’on peut juger superflus). Il a donc été fait en sorte de les enregistrer et des options ont été créées pour en enlever certains.
Gérer les formulaires Web
Les formulaires Web représentent un cas spécial. On pourrait naïvement penser que ce n’est qu’une question de HTML. Mais c’est légèrement plus compliqué que cela.
Pour les formulaires qui utilisent (implicitement ou explicitement) la méthode HTTP GET (/html/body//form[not(@action) or (string(@action) and lower-case('@method')='get') or not(@method))], en XPath 2.0), il s’agit purement de HTML. Les paramètres GET potentiellement présents dans l’URL de l’attribut form@action (qui définit à quelle URL envoyer les données du formulaire) sont ignorés. En effet, ce sont les champs du formulaire qui sont passés en paramètres GET. Il faut donc créer un champ dans le formulaire (avec la balise input) pour l’URL « proxifiée » et le cacher (ce qui se fait en créant un attribut type et lui attribuant la valeur hidden).
Pour les formulaires utilisant la méthode HTTP POST (c’est l’unique autre possibilité), il faut « proxifier » l’URL de l’attribut action s’il y en a un. Une fois la requête POST reçue sur mon proxy, il faut détecter que c’est une méthode POST pour : la renvoyer en méthode POST au service « proxifié » (par défaut, c’est la méthode GET qui est utilisée), ne pas essayer de « proxifier » le contenu, et ne pas renvoyer l’en‐tête HTTP Content-Length (défini dans la section 14.13 de la RFC 2616) (ce qui peut faire échouer l’appel PHP à curl, probablement dans le cas où PHP a encodé différemment le contenu et donc potentiellement changé la taille). Bien entendu, il faut aussi penser à enregistrer ces paramètres POST.
La gestion du JavaScript
Je n’y avais pas pensé au début (alors que c’est évident quand on fait du Web en 2017), mais le JavaScript peut être source de requêtes Web. Il faut « proxifier » les URL de ces requêtes ; bien entendu, avant qu’elles n’aient lieu. La première idée qui pourrait venir à l’esprit serait d’utiliser un analyseur syntaxique de JavaScript, ce qui serait très lourd et il en existe a priori qu’en C et C++ (comme V8 de Google qui est libre) (mais il est possible d’appeler des binaires issus de ces langages avec PHP). Heureusement, il n’y a pas de moyen de faire des requêtes avec le langage uniquement (c’est‐à‐dire avec des mots‐clés de ce dernier), il faut en effet utiliser la bibliothèque standard du JavaScript. En JavaScript, une fonction peut être redéfinie sans erreur, y compris celles de la bibliothèque standard, c’est considéré comme dangereux (à juste titre) par certains, mais cela peut être fort utile dans de rares cas, comme celui présentement décrit.
Deux cas de fonctions à surcharger pour « proxifier » des URL ont été identifiés et gérés. Dans chaque cas, il faut garder en mémoire la fonction actuelle (peut‐être qu’un autre script a déjà changé le comportement de base de la fonction), puis créer une nouvelle fonction qui « proxifie » le ou les arguments contenant potentiellement une ou plusieurs URL, et enfin appeler la fonction à « proxifier » avec les arguments potentiellement modifiés, tout en retournant son résultat si elle en retourne un. Il ne reste ensuite plus qu’à surcharger, en donnant le même nom pour une fonction ou en modifiant le prototype de la classe pour une méthode d’instance (en effet, le JavaScript a un système de classes par prototype qui diffère du modèle traditionnel présent par exemple en PHP et Java). Le terme « fonction » doit ici être compris comme une fonction en C ou en PHP, ce qui ne doit pas être confondu avec la notion de fonction en JavaScript, car celle‐ci est bien plus large (les constructeurs et les méthodes sont aussi des fonctions et sont d’ailleurs définis avec le même mot‐clé function).
Le premier cas est facile à deviner, il s’agit de la fonction à laquelle on passe une URL pour une requête AJAX. C’est l’abréviation d’Asynchronous JavaScript and XML et désigne un moyen de faire des requêtes synchrones ou asynchrones avec le langage JavaScript. Pour cela, il faut créer un objet de classe XMLHttpRequest (on passe ici sous silence partiel le cas de veilles versions d’Internet Explorer de Microsoft), ensuite définir un comportement (sous forme de fonction) pour le changement d’état (envoyé, reçu, etc.), puis utiliser sa méthode open, et enfin envoyer la requête avec la méthode send. Il suffit de « proxifier » le deuxième argument de la méthode open (le premier étant pour la méthode HTTP).
Le second cas est moins commun et je ne soupçonnais pas son existence. Il s’agit de l’inclusion dynamique (en JavaScript) de balises script avec un attribut src existant et avec une valeur non nulle. Cela déclenche la récupération du script (grâce à son URL issue de l’attribut src), puis l’exécute (ce qui permet d’éviter la fonction eval). Un élément DOM a une méthode setAttribute, il faut donc la « proxifier » quand elle est appelée sur une balise script et ne « proxifier » le second argument (qui correspond à la valeur de l’attribut) que quand le premier argument vaut (en étant insensible à la casse) src (puisque cette balise peut avoir d’autres attributs comme type).
La configuration
Un certain nombre de choses est configurable. Il y a quatre catégories : le proxy pour faire des requêtes (une URL et un numéro de port), la capture de session (enregistrer ou pas, en‐têtes HTTP à garder, etc.), le journal des erreurs et des avertissements (emplacement en tant que fichier, est‐il publique ou non, etc.), et l’interface graphique (montrer des aides au débogage ou pas, afficher certains éléments facultatifs ou pas, etc.).
La configuration se fait via plusieurs sources et sous forme de cascade. En effet, une source peut avoir une valeur indéfinie, mais une source de moindre priorité peut avoir une valeur définie. De plus, certaines sources ne doivent pas pouvoir définir des valeurs pour certaines propriétés. Par exemple, une source venant du client Web ne doit pas être en mesure de définir le chemin d’enregistrement du fichier journal (puisqu’il pourrait s’en servir pour écrire un fichier utilisé par une autre application). Pour configurer au niveau du serveur, il faut utiliser un ou plusieurs fichiers INI.
Les différentes sources de la plus prioritaire à celle qui l’est le moins :
- les paramètres GET dans l’URL ;
- les cookies HTTP ;
- la session PHP ;
- un fichier INI spécifique à une catégorie dans le dossier de l’application ;
- un fichier INI général pour toutes les catégories dans le dossier de l’application ;
- un fichier INI général pour toutes les catégories dans un dossier système ;
- les valeurs par défaut (qui sont codées en dur).
Exemple de configuration (au format INI)
# Une ligne commençant par un croisillon « # » est un commentaire.
# Le dièse "♯" ne marche pas.
# Une section aurait pu être utilisée.
proxy-url=https://proxy
proxy-port=80
[session-captured]
save-session=true
save-cookies=falseEnregistrement des données
À chaque fois qu’une ressource est récupérée par le proxy, celui‐ci doit pouvoir enregistrer la demande. L’enregistrement se fait dans le format XML, pour sa manipulation aisée (notamment via DOM, XPath et XSLT), les nombreuses bibliothèques le gérant, le fait qu’il soit standardisé et qu’il ne demande pas un serveur de gestion de bases de données. Néanmoins, l’enregistrement en XML est « isolé », de sorte qu’il soit facile (en ajoutant le code nécessaire) d’enregistrer dans un autre format (comme le JSON) ou avec un système de base de données (qui ajouterait une dépendance et une lourdeur) et d’ajouter une option pour choisir le format.
Un client Web peut faire plusieurs requêtes simultanées (notamment pour réduire la latence avec HTTP 1). Or, cela peut provoquer une écriture simultanée de nouveaux enregistrements, ce qui est presque certain de résulter en un fichier incorrect. Il a donc fallu mettre en place un verrou pour qu’un fichier d’enregistrement ne puisse être utilisé que pour un enregistrement à la fois. Cela a été fait avec la fonction flock (qui se base sur la fonction C du même nom). La mise en place et la gestion du verrou est dans une classe abstraite qui pourrait être réutilisée pour un autre format de fichier.
Le proxy était à la base mono‐utilisateur. En effet, toutes les données enregistrées étaient nécessairement dans un seul et même fichier. Pour que chaque utilisateur et utilisatrice n’ait pas à installer le proxy, il fallait qu’il soit mutualisable et donc capable de gérer plusieurs personnes. Plutôt qu’un processus de création d’un compte (qui aurait été lourd à utiliser et implémenter), un système d’identifiant de session a été mis en place. Concrètement, une personne qui demande à créer une session d’enregistrement se voit retourner un identifiant textuel sous forme de cookie HTTP. Cet identifiant est un nombre pseudo‐aléatoire (puisqu’il n’y a pas de réel aléatoire en informatique) obtenu avec une fonction réputée sûre pour la cryptographie (donc imprédictible) (dans mon cas, la fonction random_bytes de PHP), ce qui permet de s’assurer que l’on ne puisse pas prédire l’identifiant des autres utilisateurs et utilisatrices. L’identifiant est utilisé comme une partie du nom de fichier, or le nom du fichier aurait été très grand avec la valeur en décimale et illisible avec la valeur en ASCII ou Unicode, il est donc le résultat d’une fonction qui prend en entrée le nombre aléatoire et retourne une valeur hexadécimale. La fonction de hachage SHA-512 a été utilisée, car elle a l’intérêt de créer très peu de collisions (deux valeurs d’entrée ayant la même valeur de sortie) et peut compliquer une attaque s’il venait à être découvert que la fonction n’est pas cryptographiquement sûre (puisqu’une fonction de hachage est censée ne pas avoir de fonction réciproque).
À tout cela, il manquait un élément clé. En effet, les données sont enregistrées pour rejouer un « session Web », ce qui nécessite d’enregistrer des éléments techniques, mais également la temporalité de ceux‐ci. Pour ce faire, un horodatage POSIX (c’est‐à‐dire le nombre de secondes depuis le 1er janvier 1970 — appelé POSIX timestamp en anglais) est enregistré pour chaque requête. Ce format a l’avantage d’être simple et d’être très courant. Néanmoins, la seconde (au format entier) n’est pas une unité très précise, puisqu’un client Web sur un ordinateur moderne met moins d’une seconde pour demander différents éléments d’une page Web. Donc, une fonction qui renvoie un horodatage avec les microsecondes a été utilisée (il s’agit en l’occurrence de la fonction microtime).
Conversion des données
Les données sont enregistrées dans un format de données en XML. J’ai moi‐même inventé ce format qui est simple et reflète la manière dont les données sont manipulées par le proxy. Cependant, les données ne sont pas enregistrées pour un usage interne au proxy, mais pour être données en entrée d’un programme de test de performance. Puisque mon tuteur travaille sur CLIF, c’est pour cet outil qu’il était nécessaire (dans le cadre du stage) de proposer un moyen de faire une conversion. Cependant, il n’y aurait aucun problème technique à effectuer des conversions pour d’autres outils similaires.
CLIF peut jouer un scénario de test avec du code Java (un langage de programmation très répandu) ou avec des données en XML pour ISAC (qui est un jeu de mot récursif : ISAC is a Scenario Architecture for CLIF). Un moyen de convertir pour le format d’ISAC est de loin ce qui est le plus simple et ne pose aucun problème de limitation dans ce cas (il est possible de coder des comportements plus complexes en Java). C’est donc ce format qui a été choisi.
Convertir un XML en un autre XML est une volonté courante. La structuration de ce format permet d’envisager facilement de répondre à cette volonté, et un langage est même dédié à cela : XSLT. La conversion est presque entièrement faite en XSLT (en moins de 300 lignes de code), malgré des différences non négligeables (notamment la manière d’enregistrer les en‐têtes HTTP). Cela a été fait en utilisant la version 1.0 du langage XSLT, car la version 2.0 apporte très peu et n’est a priori gérée que par deux implémentations libres : Saxon-B XSLT et Saxon-HE XSLT.
Le seul élément que je n’ai pas réussi à convertir avec XSLT est le temps. En effet, mon proxy enregistre l’horodatage de chaque requête alors qu’ISAC a besoin du temps entre chaque requête. Il faut donc vérifier pour chaque requête qu’il y en a une suivante (ou précédente), puis faire la soustraction des horodatages, pour ensuite ajouter un élément entre les deux indiquant le temps qui les sépare. Il a donc fallu faire un script, à appeler avant la conversion XSLT, pour ajouter cette pause.
L’exécution du script et l’appel de la conversion XSLT sont faits en JavaScript sur le client Web. L’opération est presque instantanée avec un ordinateur moderne ; néanmoins, c’est très dépendant de l’ampleur des données à convertir. L’avantage que ce soit le client Web qui fasse l’opération est que le serveur ne nécessite pas les ressources pour cela.
Exemple de données enregistrées par mon proxy
<?xml version="1.0" encoding="UTF-8"?>
<session>
<resource>
<url value="https://www.w3.org/XML/" />
</resource>
<pause value="5003.14" unit="ms" />
<resource>
<url value="http://clif.ow2.org/" />
<method value="GET" />
<timeRequest value="1497965627.5526"
unit="ms" type="unix-timestamp" />
<timeResponse value="1497965627.6498"
unit="ms" type="unix-timestamp" />
<headers from="client">
<header key="User-Agent"
value="Mozilla/5.0 (X11; i686) Firefox/45" />
<header key="Accept-Language" value="en-us"/>
<header key="Connection" value="keep-alive" />
<header key="If-Modified-Since"
value="Wed, 28 Oct 2015 15:47:33 GMT" />
<header key="Cache-Control" value="max-age=0" />
</headers>
<proxy url="https://proxy" port="80" />
</resource>
</session>Exemple de données converties pour ISAC de CLIF
<?xml version="1.0" encoding="utf-8"?>
<scenario>
<behaviors>
<plugins>
<use id="replayHttp" name="HttpInjector" />
<use id="replayTimer" name="ConstantTimer" />
</plugins>
<behavior id="session">
<sample use="replayHttp">
<params>
<param name="uri"
value="https://www.w3.org/XML/" />
</params>
</sample>
<timer use="replayTimer" name="sleep">
<params>
<param name="duration_arg" value="5003" />
</params>
</timer>
<sample use="replayHttp" name="get">
<params>
<param name="uri"
value="http://clif.ow2.org/" />
<param name="headers" value="header=User-Agent|value=Mozilla/5.0 (X11\; i686) Firefox/45|;header=Accept-Language|value=en-us|;header=Connection|value=keep-alive|;header=If-Modified-Since|value=Wed, 28 Oct 2015 15:47:33 GMT|;header=Cache-Control|value=max-age=0|;" />
<param name="proxyhost" value="https://proxy" />
<param name="proxyport" value="80" />
</params>
</sample>
</behavior>
</behaviors>
</scenario>L’API Web
Une API (Application Programming Interface) Web basique a été créée. Elle ne s’appuie ni sur XML ni sur JSON (qui sont beaucoup utilisés pour faire des API Web). En effet, elle utilise les paramètres GET (en entrée uniquement), les [cookies](https://fr.wikipedia.org/wiki/Cookie(informatique))_ HTTP (en entrée et en sortie) et le contenu HTTP (en sortie uniquement). Elle permet de « proxifier » une ressource, gérer une session (créer, détruire et en recréer une qui écrase l’actuelle), obtenir les données de la session dans mon format, et obtenir la configuration au format HTML (il pourrait être utile de faire de même en JSON et/ou XML). Elle est utilisée par l’application, mais elle pourrait être utilisée par une application tierce. Elle est plus amplement documentée dans un fichier qui est converti en page Web et accessible depuis le menu du proxy.
L’interface graphique
L’interface graphique est visuellement rudimentaire, mais elle est facile à utiliser et est adaptée à un écran de mobile. La page d’accueil permet de gérer une session (en utilisant l’API Web qui peut rediriger vers la page précédente), d’être envoyé sur le formulaire pour « proxifier », de télécharger les données de la session (s’il y en a) et de gérer la configuration.
Il est possible de télécharger les données de la session telles qu’elles sont enregistrées par mon proxy. Il est également possible de télécharger les données converties. La conversion est pour l’instant possible uniquement pour CLIF, mais il serait facile d’ajouter le nécessaire dans l’interface graphique pour d’autres outils similaires. Pour récupérer les données converties, il y a un formulaire prérempli avec les données de mon proxy (récupérées via l’API grâce à une requête AJAX) qui fait la conversion dans le format sélectionné au moindre changement dans les données d’entrée dans le client Web (pour éviter que le serveur ait à faire ce traitement) et en utilisant « uniquement » du JavaScript (mais JavaScript peut utiliser du XSLT).
La configuration se fait via des formulaires. Actuellement, ils sont gérés uniquement en JavaScript, mais il serait possible d’ajouter une gestion sans JavaScript. L’avantage de passer par JavaScript est de pouvoir afficher la nouvelle configuration effective sans recharger la page et sans soumettre le formulaire pour les cases à cocher (en positionnant des cookies dans ce langage et en utilisant des requêtes AJAX avec l’API Web pour la configuration).
L’installation facile
Il n’y avait aucune certitude que quelqu’un continue régulièrement de développer l’outil, il fallait donc considérer par précaution qu’il n’y aurait que moi qui en aurait une bonne connaissance technique. Il faut donc que l’installation soit facile, même sans moi, pour éviter que ce que j’ai créé tombe dans l’oubli.
La partie cliente nécessite un navigateur Web avec JavaScript, comme Mozilla Firefox ou Chromium, ce qui est très simple à installer et très courant. La partie serveur est faite en PHP (dans sa version 7), qui est très courant pour faire un site Web ou une application Web. C’est un langage de script sans compilation, il suffit donc d’appeler un script PHP avec un interpréteur adéquat (ainsi que la bibliothèque standard) pour l’exécuter avec succès. Pour appeler automatiquement les scripts via le Web, il faut un serveur Web gérant CGI (Common Gateway Interface). Il y a pour cela Apache qui est libre (sous licence Apache 2.0), fonctionne sur les principaux systèmes utilisés comme serveurs (GNU/Linux, les BSD, Microsoft Windows, et Apple macOS), est empaqueté par les principales distributions GNU/Linux (notamment Debian, RHEL/CentOS et Ubuntu) et est le logiciel faisant serveur Web le plus utilisé au monde. Cela n’a pas été testé, mais il ne devrait pas y avoir de problème avec nginx, qui est le principal concurrent libre. Les prérequis pour l’installation et l’utilisation sont donc, aussi bien au niveau client que serveur, simples et courants, tout en ne nécessitant pas du logiciel privateur.
Ce que j’ai créé ne s’appuie sur rien de spécifique à un système d’exploitation (y compris pour écrire de potentielles données de sessions et de potentiels journaux d’erreurs ou avertissements) et n’a besoin que de la bibliothèque standard de PHP. Déposer le code source à un endroit où un serveur Web va chercher des ressources et potentiellement exécuter du code PHP (en version 7) suffit pour installer et faire fonctionner la partie serveur. Cette méthode est simple et ne nécessite que d’avoir des droits d’écriture dans un dossier qu’un serveur Web utilise.
Le paquet Debian
Il y a de fortes probabilités pour que mon outil soit utilisé sur un système Debian ou un dérivé (comme Ubuntu, Mint ou Trisquel GNU/Linux). La manière propre et usuelle pour installer un élément sur un de ces systèmes est de passer par un ou des paquets Debian (qui sont des archives organisées d’une certaine manière et ont usuellement .deb comme extension). Un paquet Debian a des avantages (par rapport à une installation par copier‐coller), tels que pouvoir être facilement mis à disposition via un dépôt de paquets, contenir des métadonnées (comme la version, un journal synthétique des modifications et la licence de chaque fichier du paquet source), permettre l’installation automatique des dépendances (avec APT ou un outil similaire), et il peut être vérifié qu’il suit les bonnes pratiques. Il a donc été décidé de faire un paquet Debian, ou plutôt un moyen automatique et aisé d’en faire un.
Le plus gros du travail est fait par dh_make, qui est un programme libre qui automatise de nombreuses parties de la construction d’un paquet Debian propre. Hormis le fichier control (qui contient une partie importante des métadonnées) et le fichier copyright (qui indique des informations vis‐à‐vis des auteurs et autrices ainsi que des licences), il a essentiellement fallu faire une règle install et une autre uninstall dans le Makefile (qui permettent respectivement, par logique élémentaire et convention, d’installer et de désinstaller un projet utilisable) (en utilisant le paramètre facultatif DESTDIR, qui permet par exemple de faire une installation à un emplacement où il n’y a pas besoin de privilèges d’écriture de super‐utilisateur root) que dh_make utilise automatiquement, comme la règle test (quand elle existe) qui lui permet de tester que les tests passent avant une potentielle construction du paquet.
La construction est faite avec debuild qui appelle le programme Lintian. Celui‐ci fait des tests sur les paquets et signale des erreurs pour les problèmes graves (qui ne sont pas tolérés pour un paquet dans l’archive Debian officielle) ainsi que des avertissements pour les problèmes non significatifs (mais dont l’évaluation pourrait changer à l’avenir) (comme des fichiers sans licence ou l’inclusion de jQuery alors que cette bibliothèque JavaScript est déjà empaquetée dans libjs-jquery et ne devrait pas être installée plusieurs fois). Toutes les erreurs et avertissements ont été corrigés, mais il y aurait probablement des petites choses à améliorer. La création automatique du paquet en génère donc un de qualité, bien qu’il ne soit pas parfait.
Possibilités pour améliorer les performances
Quelques pistes :
- réécrire le logiciel en langage Go : c’est un langage avec deux implémentations libres (l’officielle et gccgo), qui peut se compiler en code natif (contrairement à PHP) et est adapté pour le Web (ce dont on peut se douter quand on connait son auteur, à savoir Google) ;
- réécrire les parties nécessitant une puissance de calcul non négligeable en C ou C++ et les appeler en PHP (le C peut aussi être appelé en Go) ;
- actuellement, il y a une classe par cas à gérer (lien, image, formulaire, script, etc.), ce qui permet de décomposer au maximum ; pour les documents HTML, chaque classe fait une requête XPath ; il serait possible d’en faire moins avec une classe qui aurait plus de responsabilités, au détriment de la qualité et de la maintenabilité du code source ;
- manipuler le HTML en JavaScript sur le client : cela déchargerait notablement le serveur, mais cela nécessiterait la gestion du JavaScript sur le client et il faudrait arriver à faire les changements d’URL avant que le client Web ne les utilise pour obtenir les ressources correspondantes ;
- mon proxy récupère toutes les ressources demandées, mais il n’a aucun mécanisme de cache, ce qui peut le conduire à demander inutilement une même ressource plusieurs fois. Une solution serait d’implémenter un mécanisme de cache dans mon proxy, cela demanderait du temps mais aurait l’avantage que ce soit intégré et donc installé automatiquement. Une autre solution serait de lui faire utiliser un proxy Web (comme Squid, Polipo ou Varnish HTTP Cache), ce qui est facile et permet de ne pas réinventer la roue, ainsi que d’être optimisé et déjà testé. Cette possibilité d’ajouter un cache n’a d’intérêt que s’il y a plusieurs utilisateurs ou utilisatrices, si plusieurs clients Web ne partageant pas un cache commun sont utilisés, ou si au moins un des clients Web utilisés n’a pas de cache.
Et après ?
Il reste des cas non gérés ou mal gérés, comme la « proxification » des URL dans le CSS, l’attribut pour l’intégrité en HTML et un problème d’encodage sur de rares sites Web. De plus, l’interface graphique est fonctionnelle et simple, mais a une apparence graphique très sobre, ce qui pourrait être changée par exemple avec un style CSS préexistant comme KNACSS (qui est sous licence WTFPL), Milligram ou Twitter Bootstrap (qui sont sous la licence libre MIT). Il y a donc des choses à faire pour améliorer l’existant.
On peut aussi vouloir aller au‐delà. Il pourrait par exemple être intéressant de faire un moyen d’exporter les données pour Apache JMeter et Tsung, qui sont deux outils libres qui peuvent prendre du XML en entrée et qui sont empaquetés par la majorité des distributions GNU/Linux. Les flux de syndication (au format Atom et RSS) ne sont pas gérés, or certains navigateurs Web les gèrent. De plus, on pourrait imaginer une séparation de l’API Web et de l’interface graphique en deux services différents (mais dont l’un dépend de l’autre), ce qui faciliterait la contribution à une seule des deux parties et simplifierait la maintenance de chacune.
Il y a de nombreux tests unitaires, du moins pour PHP (qui représente la vaste majorité du code). Ainsi pour environ 15 000 lignes de codes PHP utilisés dans l’application, il y a environ 10 000 lignes de tests unitaires en PHP (chiffres obtenus respectivement avec wc -l src/include/php/class/* et wc -l tests/php/*, ce qui inclut les commentaires dont les en‐têtes pour spécifier la licence de chaque fichier, les lignes vides, etc.). Il y a également d’autres tests automatiques et pas uniquement sur le code PHP. Il y a donc un filet de sécurité si l’on veut contribuer sans casser le fonctionnement et écrire le code en respectant certaines règles (pour qu’il garde une certaine homogénéité et soit donc plus facile à lire que s’il n’en avait pas). Puisque les deux langages de programmation utilisés sont PHP et JavaScript (on fait ici exception du XSLT qui représente environ 300 lignes de code, ainsi que de HTML et CSS que tout développeur et toute développeuse Web connaît), il est facile de trouver une personne compétente pour modifier le code, car ce sont des langages courants et qui ne disparaîtront pas avant de nombreuses années.
Pourquoi ce nom ?
Le nom originel est CLIF Web Proxy (d’où le logo qui n’a pas été modifié par la suite). C’était trivial et ça reflétait bien le projet, un proxy Web pour le logiciel CLIF pour celles et ceux qui auraient directement sauté à cette partie (ou presque). Puisque le logiciel que j’ai produit peut être utilisé comme simple proxy Web et qu’il pourrait servir pour d’autres logiciels de test de charge que CLIF, j’ai décidé de lui donner un nom plus général.
Continuant dans mon imagination prodigieuse, je l’ai nommé RyDroid Web Proxy. Cela permet de rendre hommage au Créateur Suprême. En effet, RyDroid est un pseudonyme qu’il utilise couramment sur Internet. Certains racontent que c’est un mégalomane, tandis que d’autres prétendent qu’il avait bien peu d’imagination (au moins à ce moment‐là), je vous laisse vous faire votre avis. Après tant d’explications techniques, vous me ou lui (c’est qu’on se perd !) pardonnerez un moment de déconne et ça peut permettre de faire émerger un sourire avant la conclusion (quel sens de la transition !).
Conclusion
J’ai réalisé un proxy pour enregistrer une session Web et la sauvegarder dans un format pour un outil de test de charge (en l’occurrence CLIF). Il est utilisable en l’état, mais il y a des manques qui peuvent être dérangeants dans certaines situations et des fonctionnalités additionnelles qui pourraient être plaisantes. Deux moyens simples d’installation sont proposés, ce qui facilite l’utilisation de ma réalisation technique.
Celle‐ci a été publiée via Internet sous une licence libre, ce qui en fait un bien commun. De plus, il ne dépend que de technologies libres, ce qui permet d’avoir un contrôle total sur ce qu’il fait, mais aussi sur son évolution future, à laquelle un ou plusieurs autres contribueront potentiellement. Grâce au copyleft, les personnes distribuant des versions modifiées ont l’obligation légale de mettre leurs apports dans le pot commun, et ainsi créer un cercle vertueux qui ne soit pas basé sur l’exclusivité.
Bonnes captures Web et vive le logiciel libre !
Aller plus loin
- Présentation de RyDroid Web Proxy sur mon site Web (1057 clics)
- Dépôt Git sur l’instance GitLab d’OW2 (149 clics)
- Dépôt Git sur GitLab.com (157 clics)
- Site Web du projet CLIF (193 clics)
- Paquet Debian (159 clics)
# Trou de mémoire
Posté par Thierry Thomas (site web personnel, Mastodon) . Évalué à 4.
Article très intéressant, qui me rappelle des souvenirs…
Au début du siècle, pour des tests de charge, j’avais utilisé un outil dont j’ai oublié le nom. Il n’enregistrait rien au niveau du réseau, mais seulement les séquences de touches et les actions à la souris d’un utilisateur, qu’il permettait ensuite de rejouer sur de nombreuses instances en parallèle, un peu comme Loadrunner.
L’avantage, c’est que c’était très simple à mettre en œuvre, mais évidemment ça ne mesurait pas uniquement les temps de réponse du serveur, puisque cela sollicitait également le client.
C’était une application qui à l’origine avait été développée sous licence propriétaire, puis qui avait été libérée lors de la fermeture de la boîte, mais bien que libre, le code était non portable et ne fonctionnait que sous MS-Windows ; quelqu’un voit ce dont je parle ?
# Différence avec un reverse proxy ?
Posté par RoyalPanda . Évalué à 4.
Bonjour,
Quelle est la différence avec un reverse proxy que tu pourrais logger ?
[^] # Re: Différence avec un reverse proxy ?
Posté par RyDroid . Évalué à 1. Dernière modification le 30 juin 2018 à 13:32.
# Quels cas d'usage ?
Posté par Kerro . Évalué à 2.
Je n'ai pas compris à quels besoins cet outil répond, dans quels cas il est utilisé.
[^] # Re: Quels cas d'usage ?
Posté par Mathieu CLAUDEL (site web personnel) . Évalué à 5. Dernière modification le 22 juin 2018 à 08:55.
salut,
quand tu fais des scénarios de tests fonctionnels, tests de charges,… pour simuler les clients on utilise des injecteurs qui doivent être "programmer".
Tu peux faire tout à la main à coup de commande Curl ou utiliser un logiciel dédié (jmeter,… liste non exhaustive en début d'article).
Dans ces logiciels tu peux de même tout décrire les scénarios à la main ou lancer un proxy http dédié qui intercepte les requêtes et les réponses. Le logiciel pourra ensuite les rejouer (bien sur, il est possible de variabiliser les requêtes et contrôler les réponses attendus).
Dans le cas de jmetre que je connais un peu, on te propose de lancer un proxy et de modifier la configuration de ton navigateur pour l'utiliser.
Ici l'idée pour simplifier l'utilisation pour l'utilisateur non technique et leur permettre de créer les scénarios et de (si j'ai tout bien compris):
=> les requêtes sont mémorisés et peuvent ensuite être charger dans CLIF pour être rejouées dans le cadre de tests automatisés.
[^] # Re: Quels cas d'usage ?
Posté par RyDroid . Évalué à 1.
Tu as très bien fait mon travail d'explication. Néanmoins, j'ai tout de même 2 choses à rajouter.
Ton commentaire ne parle que de CLIF, mais mon format est plus verbeux que celui d'ISAC (en gros le module de scénario utilisant du XML de CLIF). En effet, il pourrait être transformé pour d'autres outils (dont Apache JMeter et Tsung qui peuvent aussi prendre en entrée du XML). Ce serait d'ailleurs assez simple puisque c'est du XML et qu'il y a XSLT, c'est d'ailleurs avec 300 lignes environ de XSLT que du JavaScript translate mon format vers celui d'ISAC.
En lisant juste ton commentaire, ce que certaines personnes feront potentiellement par flemme, on pourra croire que mon proxy enregistre nécessairement ce qui passe vers lui. C'est effectivement ce pour quoi il a été créé. Mais étant donné la facilité de rajouter une option pour qu'il n'enregistre pas, je l'ai fait. Il peut donc servir de simple proxy web, potentiellement pour contourner la censure : d'abord mettre le proxy dans une zone non censurée, puis y accéder via une zone censurée, enfin lui demander une ressource inaccessible dans la zone censurée mais à laquelle le proxy a accès puisqu'il est dans la zone non censurée. En le rendant accessible via HTTPS et en désactivant l'enregistrement, on peut le considérer comme un "VPN web".
# Demande de petite correction
Posté par RyDroid . Évalué à 1.
Dans la première phrase, il y a un saut de ligne entre "ingénieurs" et "(l'ENSICAEN)". C'est une erreur (qui, pour les curieux et curieuses, est du au fait que
pandocn'a pas ce comportement et que j'ai fait en sorte d'éviter d'avoir des lignes de plus de 80 caractères dans mon fichier pré-LinuxFr).[^] # Re: Demande de petite correction
Posté par Benoît Sibaud (site web personnel) . Évalué à 4. Dernière modification le 30 juin 2018 à 13:32.
Corrigé, merci.
[^] # Re: Demande de petite correction
Posté par RyDroid . Évalué à 1.
Merci à toi et quelle rapidité !
Suivre le flux des commentaires
Note : les commentaires appartiennent à celles et ceux qui les ont postés. Nous n’en sommes pas responsables.