On connait tous les paradigmes de programmation les plus populaires (objet, impératifs, fonctionnels, logiques), mais la créativité n'est heureusement pas limité et il en existe d'autre très intéressants.
Voici une petite liste non exhaustive de quelques paradigmes curieux, mais assez stimulants pour tout créateur de langage un peu fou.
La plus connue est sans doute la programmation événementielle, elle a sa page wikipedia en français programmation événementielle. Elle consiste à baser le flot du programme sur des évènement en y associant des bouts de code et en récupérant de ces évènements des informations.
Le système de signal/slot de QT est une application intéressante de ce principe, en ce qu'elle permet de "connecter" directement des évènements à des valeurs quelques part dans le programme, ou plus prosaïquement à des bouts de code.
Les langages classique implémentent plus ou moins heureusement ce genre de paradigme. Les langages ayant des des types block ou des lambda, le gèrent plus facilement, les autres utilisent des grosses bidouilles ou des préprocesseurs, comme QT.
Le gros défaut de ce paradigme c'est qu'il reste un hack qui rentre en pleine collision avec le paradigme de programmation impératif/fonctionnel/objet qui descend directement de la logique de batch des ordinateurs des années 50.
Rule Based Programming
La programmation orienté règle (Rule Based Programming) est peu connue et assez intéressante. Elle se rapproche plus d'une logique du premier ordre, donc assez haut niveau. Il n'y a pas grand chose de très différent avec un moteur à la Prolog. Seul le contrôle de flot diffère puisque le moteur va "surveiller" la base de fait pour appliquer une règle qui pourrait "matcher"
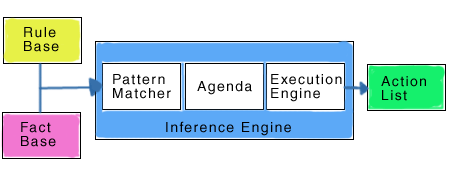
Elle est à la base de Drools, qui est un moteur d'inférence libre pour le monde Java, distribué par Apache
Les langages orientés agent "BDI"
Alors là c'est vraiment intéressant et vraiment exotique.
Basés sur la théorie de Michael Bratman du "human practical reasoning", les langages Belief, Desire, Intention modélisent l'agent comme une entité ayant des objectifs finaux (Desire), des croyances issus de son passé ou de ses perceptions et des intentions immédiates lui permettant d'atteindre ses objectifs.
Les langages BDI font l'objet de pas mal de recherches dans les laboratoires car ils sous-tendent tout un ensemble de problèmes théoriques.
La formalisation de ce genre d'approche a été en effet l'occasion de développer différents modèles de logique modale.
Les logiques modales, à la différence de la logique classique permettent d'exprimer des concepts un peu plus fin que "il est vrai que Jean habite à Paris".
Elles permettent par exemple d'exprimer qu'"il est possible que Jean habite à Paris" (logique aristotélicienne), qu'"il est connu que Jean habite à Paris" (logique épistémique), "il est obligatoire que Jean habite Paris" (logique déontique) ou encore qu'"il est permis que Jean habite à Paris". N'oublions pas la logique temporelle qui permet d'exprimer la variabilité d'une vérité en fonction du temps.
S'ensuivent toute sorte de problèmes lorsque l'on veut faire de la logique multi-modale, qui supposent pas mal de difficultés en terme de complexité (ça peut être gérable), voire de complétude (c'est plus gênant).
Pour illustrer à quoi ressemble ce genre de langage, je vous propose de regarder l'implémentation du jeu de la vie. La cellule est ici un agent, et elle a une perception alive_neighbors qui lui permet d'ajouter des croyances au fur à mesure des "tours".
Ce bout de code est issu de Jason (http://jason.sourceforge.net/Jason/Jason.html) , qui est un excellent environnement de développement orienté BDI. Tout est là pour vous faciliter la vie : débuggeur, outils graphique, exemples, etc...
http://jason.sourceforge.net/mini-tutorial/getting-started/
Cela se lit de la manière suivante : Si un nouvelle perception/croyance step(_) et que alive_neighbors(2) alors exécute skip. Si on avait écrit !skip, cela
signifierai que skip est un nouveau but (Desire) de l'agent, ce qui ne voudrait rien dire dans notre cas.
// If there are 2 alive neighbors, the cell remains in the state it is in.
+step(_) : alive_neighbors(2) <- skip.
// If there are exactly three alive neighbors, the cell becomes alive.
+step(_) : alive_neighbors(3) <- live.
// If there are less than two alive neighbors, then the cell dies.
// If there are more than three alive neighbors, the cell dies.
+step(_) <- die.
Bref, tout cela pour dire que l'on va un peu plus loin que nos automates de Turing améliorés qui nous servent de langages de programmations quotidiens.
Pour ma part, je crois que les langage agent BDI ont un grand avenir devant eux, mais cela mettra quelques décennies à s'imposer.
# Rule Based Programming
Posté par Sytoka Modon (site web personnel) . Évalué à 10.
Deux exemples de langage très utilisé utilisant ce principe
C'est donc plus utilisé qu'on ne le croit ;-)
[^] # Re: Rule Based Programming
Posté par B16F4RV4RD1N . Évalué à 4.
Inform7 utilise également des règles : http://inform7.com/sources/src/stdrules/Woven/index.html
http://en.wikipedia.org/wiki/Inform#Inform_7
Une analyse de ce paradigme de programmation appliqué aux fictions interactives :
http://eblong.com/zarf/essays/rule-based-if/
Only wimps use tape backup: real men just upload their important stuff on megaupload, and let the rest of the world ~~mirror~~ link to it
# De l'intérêt de ces paradigmes ?
Posté par ǝpɐןƃu∀ nǝıɥʇʇɐW-ǝɹɹǝıԀ (site web personnel) . Évalué à 3.
Une question de programmeur inculte de C. Pour moi programmer c'est retranscrire un problème (parfois complexe) dans des instructions simples, les plus proches que possible, du fonctionnement de la machine.
Apparemment tout ces paradigmes de programmation permettent d'exprimer de manière aisée certains problèmes. Du coup une très large part de la difficulté de programmation usuelle est transférée au compilateur/interpréteur. Est-ce bien là l'utilité pratique de ces langages : quasiment automatiser l'art de la programmation ?
« IRAFURORBREVISESTANIMUMREGEQUINISIPARETIMPERAT » — Odes — Horace
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Maclag . Évalué à 10.
Évidemment présenté comme ça, on a l'impression de comparer un robot automatique de peinture de voiture dans une chaîne de production avec un Rembrandt.
Il y a pour sûr une part d'automatisation, mais ça n'enlève rien à l'art de la programmation elle-même, à mon humble avis.
Les langages de haut niveau permettent de se focaliser sur un problème de complexité plus élevé, on gagne ainsi un temps précieux et un code plus facile à comprendre et maintenir.
Du reste, en quoi un compilateur "non C" serait moins artistique qu'un compilateur C?
On peut descendre au niveau de l'assembleur, et prétendre que le C est là pour automatiser l'art de la programmation. La programmation se fait en assembleur!
C'est sûr qu'on peut tout faire en C, comme avec quasiment n'importe quel langage. Le C est juste le langage le plus populaire de ces dernières années, avec un lien très fort avec le développement d'Unix.
Il est proche du niveau de la machine comparé à d'autres. Mais à une époque, il était considéré comme suffisamment éloigné pour lui préférer l'assembleur.
Les compilateurs ayant l'efficacité qu'ils ont actuellement, il n'y a plus aucun intérêt à programmer en assembleur, le code C sera mieux optimisé dans la plupart des cas.
Qui nous dit qu'un autre langage doté d'un bon compilateur et basé sur un paradigme différent de l'impératif ne détrônera pas un jour le C, relégué au rang des langages inutilement compliqués au point que le "nouveau" langage aura un compilateur capable de produire un meilleur résultat que le couple C+compilateur C?
Dira-t-on que l'art de la programmation disparait, ou qu'il évolue vers un autre niveau?
Pour prendre un parallèle un peu foireux:
Depuis qu'on a les ordinateurs pour produire des dessins, dit-on que la machine remplace l'art du dessin parce qu'on n'a plus à se soucier du mélange des couleurs nous-mêmes? Le dessin vectoriel est-il moins un art que la peinture parce qu'il est "trop loin de la couleur sur le support"?
De la même manière, la réponse est: on peut encore faire des choses avec un pinceau et de la peinture difficiles à reproduire sur ordinateur, mais on peut également utiliser des outils de sorte que l'artiste se focalise plus sur le résultat qu'il veut obtenir que sur la qualité des poils de son pinceau.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par ǝpɐןƃu∀ nǝıɥʇʇɐW-ǝɹɹǝıԀ (site web personnel) . Évalué à 3.
C'est là le cœur de ma question sans doute exprimé de manière plus claire. De mon point de vue naïf, le C se rapproche raisonnablement du fonctionnement des microprocesseurs actuels. Cela me semble permettre qu'un programme bien exprimé puisse être compilé efficacement et qu'au final un « bon » programmeur puisse obtenir une efficacité de calcul optimale.
Il me semble que les autres paradigmes de programmation sont « plus éloignés » de la machine. Sans nier le moins du monde qu'il aient leurs intérêts pour de nombreuses situations et des raisons variées ; je me demandais simplement s'il était (raisonnablement) envisageable que ces paradigmes modernes apportent de l'efficacité de calcul ; que ce soit par l'amélioration des compilateurs, par l'apparition de nouvelles architectures de microprocesseurs, ou par tout autre moyen.
Si la réponse à cette question devait être positive, il ne me semble pas pertinent d'affirmer que « l'art de la programmation disparaît ; que voulez-vous ma bonne dame, tout fout le camp ! » Plutôt, j'imaginerais un bouleversement radical des compétences et processus intellectuels qui font un bon programmeur dans le domaine du calcul intensif.
« IRAFURORBREVISESTANIMUMREGEQUINISIPARETIMPERAT » — Odes — Horace
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par scand1sk (site web personnel) . Évalué à 4.
Il y a toujours plusieurs moyens d'optimiser un programme, mais le moyen le plus efficace, ça reste de concevoir des algorithmes nécessitant moins d'opérations (en termes de complexité, notamment). Ces algorithmes seront d'autant plus faciles à implémenter que le langage est de haut niveau. Passer moins de temps à optimiser des bouts de chandelle permet de passer plus de temps à concevoir de meilleurs algorithmes…
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 5.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par thoasm . Évalué à 4.
Tu pense à quoi comme structure pas implémentable ? Que ce soit possible de les implémenter plus efficacement en C je veux bien, mais qu'elle soit carrément pas implémentable j'ai quand même du mal.
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 2.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par thoasm . Évalué à 2.
Il y a des vecteurs en o(1) en python ...
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 4.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par thoasm . Évalué à 2.
Ça ca doit être si tu dois redimensionner dynamiquement ton tableau ... ce que tu peux pas faire facilement dans un algo en C non plus.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par 태 (site web personnel) . Évalué à 3.
o(1) ça fait vraiment pas beaucoup ! Plus le vecteur est long moins ça prend de temps d'accéder à ses éléments ?
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 1.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 2.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par barmic . Évalué à -1.
Tu connais beaucoup de langages qui n'ont pas la notion de référence ou de pointeur ?
Dans la liste que tu cite, python et ruby en ont pour les deux autres je sais pas. La seule chose que tu perd c'est la gestion de la mémoire (devoir "nullifier" des références au lieux de simplement libérer).
Je dirais même que le C est juste une abomination sans nom pour faire de la structure de données, simplement parce qu'il n'a pas de paradigme objet. Faire des structures structures de données sans polymorphisme (on peut aussi l'obtenir par duck typing) et sans masquage de l'implémentation, je trouve ça juste ridicule (c'est toi qui a commencé à troller sévère).
Pour moi le meilleur langage pour faire des structures de données c'est le C++ :
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 3.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Sytoka Modon (site web personnel) . Évalué à 3.
L'intérêt du C est que la liaison C <-> .so est simple. Du coup, il est facile d'utiliser une bibliothèque écrite en C.
Les autres langages compilés n'ont pas normalisé à ma connaissance la laison bas niveau coté OS. Les objets que l'on retrouve dans les .so via nm dépendent du compilateur. Par exemple, en Fortran 90, chaque compilateur fait ce qu'il veut, c'est catastrophique. Au final, toutes les bibliothèques de bas niveau sont écrites en C !
Il est plus que temps que les langages compilés normalisent le mapping avec le format ELF. Il est par exemple idiot dans l'absolu de programmer une bibliothèque matricielle en C alors que le Fortran est conçu pour cela.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par ecyrbe . Évalué à 3.
Les arguments de Linus sont mauvais. Linus est fort en C, et n'aimes pas le C++ pour de mauvaises raisons. Que le c++ ne soit pas adapté à du code noyau, on le comprends facilement. Mais pour le polymorphisme du c++, on dirait que linus reproche au c++ d'être un langage objet. Cependant, il oublie le polymorphisme statique du c++ (avec les templates) qui permet de faire des algorithmes et structures de données vraiment génériques, et le C peut aller se coucher de ce côté là.
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 7.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par barmic . Évalué à 4.
N'empêche que le gars qui explique que Boost n'est pas portable et qui de son coté fait du code avec des extension GNU de partout et ne passe que sur gcc et les compilateurs qui tentent d'implémenter les extensions GNU (comme icc), je trouve ça ridicule.
L'unique abstraction dont il parle c'est la modélisation objet des programmes. C'est ce qui ne lui plaît pas. Il fait parti de ces programmeurs qui ont peur de perdre en performance parce qu'ils utilisent des objets. C'est plus ou moins du même niveau que croire que l'on perd en performance parce qu'on utilise trop de fonctions et qu'il vaut mieux coder de grosses fonctions pour qu'elles soient bien performantes.
Pour ce qui est des mérites de Linus, on sait tous ce qu'il a fait et fait toujours. Mais il n'est pas le développeur ultime. Par exemple affirmer :
Ça c'est juste un troll bien velux. Mercurial est un vrai concurrent. C'est ce voiler la face d'affirmer que git est le seul CVS bon qui existe et que tout le reste c'est de la merde. Par exemple Mercurial a fait un effort de modularité qui n'existe tout simplement pas dans git. Moi je vais essayer monotone d'ici peu, je ne le connaissais pas et c'est toujours intéressant de découvrir de nouvelles choses (j'utilise git actuellement).
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par barmic . Évalué à 0.
Sous Linux tu te retrouve avec un mécanisme de pagination de mémoire qui fait que l'accès à la mémoire peut être beaucoup plus complexe que ce que ton algo le laisse penser (chargement d'une nouvelle page mémoire par exemple).
Oui même en C tu as des mécanisme sous jacent. L'idée c'est qu'il faut les connaître et savoir s'en servir (c'est ce que l'on appel communément savoir programmer dans ce langage). En python (je connais pas ruby), tu as des mécanismes qui permettent de ne pas avoir les problèmes dont tu parle (notamment avec ce qu'ils appellent je crois les "nouveaux objets").
Donc nous sommes d'accord un langage que l'on maîtrise pas ou mal est une plaie pour faire de la structure de données, mais c'est aussi une plaît pour tout le reste.
Pour ce qui est du C, explique moi comment tu fait pour dans ta structure de donnée :
void*(parce qu'avec ça tu n'a plus aucune aide fournis par ton compilateur et c'est à l'utilisateur de se débrouiller pour savoir à tout moment ce qu'il traite et il se retrouveras à faire du transtypage de partout)Je comprends pas ce que tu veux dire.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 2.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par barmic . Évalué à 2.
Parce que tu as dis que quand on veut faire de la structure de données en python, il faut le faire en C. Je ne parle pas des « Ada, pascal, haskell, ocaml », parce que je ne les connais pas (bien qu'ocaml ayant un paradigme objet il a la même au minimum les même avantages que le C++ (sauf la gestion de la mémoire)).
Parce que tu cite Linus qui démoli le C++ et fait tout en C.
Mais si tu veut que je généralise tout ce que j'ai dis au sujet du s'applique tel quel à tout les langages impératifs (je ne m'exprime pas sur les langages fonctionnels).
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 1.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par barmic . Évalué à 2.
La manière de le présentais le sous-entendais.
Tu avais prévenus, tu confond structure de données et algorithme. C'est pas grave. Mais tout de même dans la littérature, comme tu dis, on défini les structure de données par un ensemble de fonctions qui leur sont applicable et par le comportement de ces fonctions. Dans quasiment tout les cas ces présentés avec des notations mathématiques.
Si tu implémente une liste chaînée en C par exemple. Comment est ce que tu empêche que l'utilisateur prenne un élément de ta chaîne et modifie le pointeur vers l'élément suivant à la main ? Comment tu fais pour qu'il passe d'une implémentation à une autre d'une même structure sans avoir à modifié chaque déclaration + chaque endroit où il les passe en paramètre ?
Puisque tu veux que je te donne des exemples précis pour python c'est grâce au
__slot__. Quand Tu déclare tes classes ainsi :L'accès aux attributs des objets se fait de manière statique (
v.marquene fait alors plus appelle à un index) et il n'est donc plus possible d'ajouter dynamiquement des attributs dynamiquement.Pour le masquage de l'information, il faut utiliser la méthode
property(mais c'est quelque chose qui semble moins t’intéresser).Pour ce qui est du model checking, c'est un peut comme si tu expliquait que pour être sûr qu'un programme est correcte il faut le prouver quelque soit le langage. Il y a des langages qui aident plus que d'autres. Il reste moins lourd d'utiliser les fonctionnalités du langage pour assurer la cohérence que d'utiliser des outils externes, lourd et à la charge de l'utilisateur.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Cédric Chevalier (site web personnel) . Évalué à 3.
Il est tout à fait possible de faire des objets opaques en C ...
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par barmic . Évalué à 2.
Donc faire de l'objet en C…
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par lasher . Évalué à 3.
De l'objet oui, mais pas de l'orienté objet, comme j'ai vu dire quelque part ici. En ce qui me concerne, un langage orienté objet est un langage qui propose des constructions pour facilement gérer les objets. Le C ne propose rien de ce côté. Après faire des ADT c'est toujours possible, quel que soit le langage, et idem pour les objets. :)
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Pascal Lambert . Évalué à -7.
Tout faut, le meilleur langage pour moi est le Pascal :
- L'objet inutile: présente qqcchose infaisable en Pascal non objet: je demande à voir !
- la gestion des pointeurs en 'C' est merdique (en C++ je sais pas!)
- la gestion des pointeurs en Pascal est plus facile que 1+1=10 !
- on a les records, qui permettent de faire des structures complexes.
- on peut faire des arbres / listes ou autre avec les pointeurs
- on peut faire 2 listes enlacées ( tu la connait celle-là???? )
etc ...
A +!
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par lolop (site web personnel) . Évalué à 3.
Ben oui, c'est Pascal Lambert :-)
Votez les 30 juin et 7 juillet, en connaissance de cause. http://www.pointal.net/VotesDeputesRN
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par barmic . Évalué à 1.
C'est rare que je fasse la remarque mais celle-la est un peu dure.
Je connais pas Pascal mais je ne connais d'autres mécanisme que l'objet pour masquer vraiment l'implémentation de ta structure à son utilisateur.
Déçu de l'arithmétique des pointeurs ? :)
Peut être
Ce sont des sortes de structures C en plus évoluées ?
Tu n'a sans doute pas compris ce que j'ai voulu dire (faut dire que je m'exprime pas super bien). J'ai juste dis que tout les langages qui ont la notion de pointeur ou de références sont capable de faire de la structure de données, j'ai juste ajouté que je trouve que le C++ est ce qu'il y a de mieux pour ça.
Non mais je présume qu'on peut la faire en C++
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Blackknight (site web personnel, Mastodon) . Évalué à 0.
C'est pas un peu gonflé de dire ça alors que tu connais pas tous les langages du monde notamment les Pascal et Algol-like ?
Allez, un bout de code Ada pour la gloire :D
PACKAGE Singly_Linked_Lists IS
------------------------------------------------------------------------
--| Specification for simple linked lists with a single pointer
--| Author: Michael B. Feldman, The George Washington University
--| Last Modified: September 1995
------------------------------------------------------------------------
ça vient de là, ça me prenait la tête d'écrire ça moi-même.
Bon, tu remarqueras aisément que :
- ce n'est pas de l'objet
- ça respecte l'encapsulation
- ça n'utilise pas de pointeur merdique avec arithmétique
Moi aussi, j'ai fait du C++, ça a des avantages, ça a des inconvénients. D'ailleurs, l'objet aussi, ne rêvons pas. En tout cas, il n'y a pas de langage parfait, ça se saurait.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par barmic . Évalué à 1.
Et puis quoi encore ? Si je veux dire que j'adore les croissants et que c'est ma viennoiserie préférée et que je la trouve formidable, je m'autorise à le dire malgré le fait que je ne les ai pas toutes goûtées (je ne les connais même pas toutes).
C'est nouveau ça de ne plus pouvoir donner son avis par le simple fait que l'on est pas une connaissance de l'ensemble des possibilités. C'est comme si je disais qu'il était gonflé de dire que Linux c'est bien sans avoir touché à un BSD ni à QNX ou Haiku.
Sinon les prés et post condition c'est des commentaires où c'est formellement vérifié à la compilation ou à l'exécution ?
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Blackknight (site web personnel, Mastodon) . Évalué à 1.
Y a une grande différence entre dire j'adore les croissants et les croissants, c'est ce qu'il y a de mieux. Le premier annonce clairement la subjectivité, le second donne un fait... Mais bon, je chipote.
Sinon, pour les Os cités, j'ai touché aux quatre... ;-)
Ici, c'est du commentaire mais en passant du Spark Ada, ce serait vérifié à la compilation. Enfin, le langage seul vérifie déjà pas mal de choses.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par barmic . Évalué à 0.
Lis avant de répondre ça seras plus simple. Pour rappel voici ce que j'avais écris (tu peut le vérifier plus haut :
Alors oui j'ai pas mis en gras les deux premiers mots, mais il me semble que la subjectivité était assez claire, non ? En plus c'est en début de phrase, il y a même pas besoin de lire jusqu'au bout.
J'aurais put en citer d'autres : AIX, HPUX, ReactOS, Minix,… Je doute qu'il soit possible d'avoir touché à tout les OS, ni tout les langages (ça serait intéressant mais il y en a bien trop et il faut approfondir un minimum pour connaître).
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Dr BG . Évalué à 1.
C'est subjectif sur ton appréciation de l'ensemble des langages, mais encore faut-il connaître l'ensemble des langages. Donc ça ne change rien. tu voulais dire « Mon langage préféré pour...», mais ce n'est pas strictement équivalent.
Alors, on pinaille et je comprends bien ce que tu voulais dire, mais l'interprétation de ton interlocuteur est tout de même correcte à la base.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par barmic . Évalué à 2.
Vive la mauvaise foie, la prochaine fois il faudra écrire :
Comme ça peut peut être que je ne choquerais personne…
Il y a vraiment que sur DLFP qu'on peut se faire reprocher de ne pas avoir précisé que l'on ne connais pas tout les langages.
Pour parler plus sérieusement, ma phrase voulais dire d'une part que c'est mon opinion (donc évidement avec mes connaissances) et le coté affirmatif c'est parce que je ne vois pas d'inconvénients à celui-ci.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Dr BG . Évalué à 0.
Je répondait simplement à ta réponse plus haut. Ton opinion et le C++ je m'en balance pas mal.
Tu pouvais simplement répondre que ça n'était pas la peine d'être si pointilleux et qu'on comprenait très bien ce que tu voulais dire, mais non, tu vas nous raconter que ta phrase ne souffrait d'aucune ambiguïté et qu'elle était correcte en nous la décortiquant. Sauf que ton explication ne change rien. C'est tout, le reste je m'en fiche.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par barmic . Évalué à 1.
C'est toi qui à commencé l'orgie avec les mouches, je n'ai fais que continuer...
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Blackknight (site web personnel, Mastodon) . Évalué à 0.
Juste pour les archives du Web, pour moi, aujourd'hui, la meilleure façon de programmer, c'est en Ada sous FreeBSD avec Emacs...
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par barmic . Évalué à 1.
Et ?
Tu remarqueras que pour ma part j'avais argumenté.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Blackknight (site web personnel, Mastodon) . Évalué à 0.
Ok, on y va.
Pour le langage :
- Typage fort (moi, je trouve ça bien)
- Possibilité de faire de la POO
- Encapsulation forte
- Utilisation des génériques (ou template pour un équivalent C++)
- Bibliothèque de base standardisée
- Limite de portée des pointeurs pour éviter les pointeurs pendants
- Impossibilité de faire de l'arithmétique de pointeur
- Véritable gestion des spécifications (compilable, n'est pas un bidule géré par un macro-processeur et reste indépendant du source contrairement à Java)
- Multithreadé de base
- Lisible donc maintenable dans la limite du design de départ
Pour l'Os :
- Robuste
- Consistent (on n'a pas d'un côté le noyau et de l'autre, le reste du monde, les deux évoluant à des rythmes différents)
Bien sûr, cela ne reste que ma vision des choses. D'ailleurs, y a six ou sept ans, j'aurais pu te parler dans des termes aussi élogieux du C++ et de l'Objective-C et il y a treize du Java. Comme quoi, faut pas se focaliser
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Alex . Évalué à 4.
Utilisation des génériques (ou template pour un équivalent C++)
Les 2 sont loin d'être équivalents quand même
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Blackknight (site web personnel, Mastodon) . Évalué à 0.
Je vais encore faire mon bourrin mais tu peux développer ?
Il y a bien des différences mais de là à dire que c'est loin d'être équivalent...
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par shbrol . Évalué à 1.
C'est très, très loin d'être équivalent. Les generics, c'est juste un jouet, du sucre pour avoir des collections typees.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Blackknight (site web personnel, Mastodon) . Évalué à 1.
Mais encore ?
Parce que là, c'est un poil restrictif comme définition. L'existence même des paquetages IO, Numerics et j'en passe va à l'encontre des restrictions que tu imposes à cette fonctionnalité... Ou alors, c'est encore le départ du troll sur les langages :D
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Alex . Évalué à 4.
Au cas où j'aurai dit une connerie, je parlai des generics java, je ne connais pas ceux du C#
Donc les template, qui ne sont pourtant qu'une grosse macro, ont le bon gout d'être turing complet, ce qui n'est pas le cas des generics java.
Les generics, à part de ce facilité la vie sur les cast, je n'y ai pas trouvé grande utilité.
Par contre les template ont peut les dériver des types de la template, ou encore instancier ce type au sein de la template, ont peut les spécialisés en fonction du type...
En pratique que peut on faire avec des template qu'on ne peut faire avec les generics: duck typing, développement d'algorithme génériques (type les graphs de boost), modifier le comportement d'un objet sans modifier l'interface de celle ci (typiquement lorsqu'on écrit un garbage collector pour c++, au lieu d'instancier l'objet, on laisse la template le faire et on redefini les opérateurs . et ->, comme les smart pointers de boost).
Je dis pas que c'est sans défaut, ne serait ce que la syntaxe très lourde (perso je n'ai jamais réussi à lire std::string), c'est statique (il faut connaitre la template à la compilation et si on modifie celle-ci, il faut tout recompiler, y compris les modules annexes), de plus pendant longtemps les compilos géraient très mal les templates.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Blackknight (site web personnel, Mastodon) . Évalué à 1.
J'ai réalisé après qu'effectivement on parlait pas de la même chose :)
Perso, je parlais des generic Ada dont seul le mot clé a été re-pompé par Java car à part ça, on en est à des kilomètres. C'est d'ailleurs le même problème pour les enum mais bon, passons.
En Java, on est bien d'accord, les generic, c'est plus pour rassurer des dinos comme moi qu'autre chose :D
En C++, les template, c'est bien mais je suis bien d'accord avec toi, la syntaxe peut vite devenir imbuvable pour peut que tu fasses des templates de templates.
De toutes façons, je crois que quel que soit le langage, la généricité, c'est lourd ;-)
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Dr BG . Évalué à 2.
En Ocaml ou Haskell c'est plus simple ;-)
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Blackknight (site web personnel, Mastodon) . Évalué à 0.
Beaucoup, non mais quelques-uns comme :
- Lisp et ses descendants
- Prolog
- Smalltalk
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Krunch (courriel, site web personnel) . Évalué à 5.
Très, très naïf.
pertinent adj. Approprié : qui se rapporte exactement à ce dont il est question.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Lutin . Évalué à 1.
Cependant, il faudra toujours des gens pour développer les compilateurs, et là l'assembleur reste nécessaire.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par scand1sk (site web personnel) . Évalué à -1.
Ça fait longtemps que les compilateurs ne sont plus programmés en assembleur. C'est le principe même du « bootstrap » : on commence par écrire le compilateur d'un nouveau langage dans un autre langage existant, et une fois que le compilateur tourne, l'ancien langage n'est plus utile.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Lutin . Évalué à 8.
Je sais bien qu'un compilateur n'est pas écrit en assembleur, mais la compréhension de l'assembleur est nécessaire pour écrire un bon compilateur.
Et le jour où l'on créé une nouvelle famille de CPU avec des instructions supers exotiques (autre chose que changer mov A,0x32 par movwf 0x32), il faudra redescendre d'un niveau.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par ymorin . Évalué à -2.
Ou faire de la compilation croisée.
Pour une nouvelle architecture, on prend un compilateur existant (eg. gcc), on écrit un 'backend' pour cette nouvelle architecture, on génère un compilateur croisé.
Ce compilateur croisé génère du code pour la nouvelle architecture, et avec ce compilateur, on cross-compile le compilateur pour obtenir un compilateur natif sur la nouvelle architecture.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par fearan . Évalué à 3.
Et tu fais un compilo qui génère du code sans la nouvelle instruction de la mort qui tue.
De même connaitre le fonctionnement du proc peut aussi apporter un plus. Par exemple si je code sur une machine sparc, ma façon de coder ne sera pas la même (le principe des registre i/o est tout simplement génial :) )
Il ne faut pas décorner les boeufs avant d'avoir semé le vent
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par scand1sk (site web personnel) . Évalué à 1.
Rester au plus près du fonctionnement de la machine n'est pas du tout indispensable, dans la mesure où l'on puisse toujours tout faire/calculer de manière raisonnablement efficace.
Les « difficultés » de programmation que l'on transfère au compilateur n'en sont généralement pas : il s'agit le plus souvent de choses relativement simples et automatiques, qui peuvent justement être automatisés (par exemple, la gestion des allocations/désallocations de mémoire, les compteurs dans les boucles, la gestion des piles, des messages…)
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Sytoka Modon (site web personnel) . Évalué à 6.
A chaque langage son utilité. Si tu fais du C, tu utilises certainement des Makefile donc utilise aussi un autre paradigme de programmation à ce niveau la. Faire l'équivalent du boulot d'un Makefile en C est possible mais particulièrement pénible...
Idem pour la programmation événementielle. Il est préférable d'utiliser POE ou Any::Event (Perl), une boucle AMQ... que de vouloir faire un monstre en C qui sera tout sauf souple. C'est aussi ce qui est réalisé dans tous les toolkits graphiques.
Un langage de programmation a son utilité s'il sers à écrire des programmes efficaces ayant le moins de bogue possible. Le lien avec ce qui se passe dans un microprocesseur est de plus en plus éloigné. Même le C n'est pas si proche que cela d'une architecture x86... Avec le temps qui passe, il y a de moins en moins de raison de trop collé à l'architecture matérielle. En plus, celle-ci évolue de son coté (multi-core...).
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par barmic . Évalué à 6.
Il permettent d'aborder les problèmes sous un angle différent ce qui peut simplifier drastiquement la maintenance et l'évolution du logiciel. Cette simplification pourrait permettre d'avoir plus de fonctionnalités dans les logiciels ou moins de bug.
Je ne pense pas qu'il faut avoir peur de voir disparaître le boulot de programmeur à cause de ces choses là. C'est à nous de nous adapter, de modéliser les problèmes comme il faut, de faire les bons choix de technologies en fonction du problème, de tester de manière fine nos programme pour finalement avoir une qualité de logiciel toujours meilleure.
Dernière chose :
> Pour moi programmer c'est retranscrire un problème (parfois complexe) dans des instructions simples, les plus proches que possible, du fonctionnement de la machine.
Le C a était conçu comme une transposition de l'anglais en langage machine. Ses concepteurs n'avaient absolument pas pour but d'être proche de la machine au contraire, ils cherchaient à obtenir quelque chose de haut niveau (même si avec l'évolution il existe actuellement des langages encore bien plus conceptuels).
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 4.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Nerdiland de Fesseps . Évalué à 1.
Voici ce qu'on m'a dit sur le Prolog:
En programmation logique, le programme sera capable de tirer des conclusions logiques d'après les données présentes dans sa base de règles et sa base de faits. Contrairement à la programmation classique il ne se contente pas de suivre les instructions pas à pas.
Prenons par exemple le cas d'un programme permettant de conjuguer tous les verbes de la langue française. En Prolog, il suffira de lui décrire comment se forme la conjugaison d'un verbe (radical + terminaison, selon personne et selon groupe, avec quelques exceptions), et grâce à ces règles et au moteur d'inférences il sera possible de lui demander :
Ceci sans écrire plusieurs fonctions, ni de fonction de parsage. Le code est plus compact.
Autre possibilité (encore utopique) : le cyber-médecin. Le médecin humain observe les symptômes pour essayer de déduire la maladie (fait 1: il tousse, fait 2: on est en novembre, fait 3 : on est en France dans une région où une épidémie de grippe a été annoncée = conclusion 1 : c'est sans doute la grippe), et à partir de là recommander le traitement le plus approprié (conclusion 2 : le médicament X à telle posologie sera le plus adapté selon son âge, son état physique, son dossier médical, etc).
Avec un programme logique, on entre toutes ces infos dans la base de faits (symptômes, maladies reliées, médicaments, posologie, diagnostics d'autres médecins, spécificités selon l'époque et la localisation, etc) et le programme sera capable de déduire la ou les maladies les plus probables selon les informations qu'on lui donne, ainsi qu'un traitement adapté. On fait appel ici réellement à des fonctions d'intelligence artificielle et de logique floue, pour lesquels la programmation "classique" est bien moins efficace.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par _seb_ . Évalué à 2.
Bienvenu dans le monde d'aujourd'hui: l'ordinateur et les bases de connaissance permettent aux médecins de déduire la maladie et les prescriptions adaptées au patient. C'est utilisé dans pas mal d'hôpitaux et ton médecin généraliste a sans doute lui aussi un logiciel qui lui permet d'élaborer l'ordonnance à partir d'une base de médicament (au passage, je crois que ce genre de logiciel vérifie aussi les incompatibilités médicamenteuses).
Je pense qu'il s'agit essentiellement de mathématiques statistiques et qu'au contraire c'est une programmation très procédurale qui est appliquée.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par thoasm . Évalué à 2.
Les maths et les stats n'ont rien de procédural en temps que tel ...
A mon avis tu confond une méthode de résolution d'un problème et son implémentation. Implémentation qui sera plus ou moins aisée dans différents paradigmes, mais la plupart du temps on peut tout implémenter dans n'importe quel paradigme (Turing completude tout ça). La difficulté de le faire sera pas forcément la même, par contre.
Tu peux calculer une moyenne en écrivant "crée une nouvelle variable, pour chaque indice de 1 à N ajoute tableau[indice] à variable, divise par N et renvoie moi le résultat", c'est du procédural.
Ou tu peux faire du déclaratif, donner la formule mathématique de la moyenne et laisser la machine faire le calcul comme elle veut/peut.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Philippe F (site web personnel) . Évalué à 1.
Sur cet exemple précis de la moyenne d'ailleurs, le programmeur C sera contant de son programme "plus proche du hardware" et donc plus rapide. Mais il se fera ramasser par la gestion pourrie des floats en C.
Un programme dans un langage de haut-niveau, notamment des langages orientés maths, seront suremement moins proche du CPU (et encore, le JIT, c'est bien à ça que ça sert) mais donneront un résultat correct avec un nombre de décimal beaucoup plus élevé.
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par Gniarf . Évalué à 3.
déjà il prendra des doubles, et s'il a besoin de plus de précision il a déjà 42 bibliothèques de code qui n'attendent que lui.
maintenant s'il fait n'importe quoi comme garder des valeurs extrèmes tout en voulant une moyenne ultra-précise, c'est un autre problème.
comme les gus qui voudront des millions de décimales alors qu'ils ont n valeurs à d décimales, ce qui rendra idiot une précision de plus de d+log(n) ou un truc comme ca
[^] # Re: De l'intérêt de ces paradigmes ?
Posté par oao . Évalué à 1.
d+log(n)/2 selon la loi des grands nombres non ?
# La programmation quantique
Posté par ecyrbe . Évalué à 3.
Il y a aussi la programmation quantique qui permet d'exploiter les potentiels ordinateurs quantiques...
# Paradigme SMA
Posté par Victor . Évalué à 10.
Je trouve ça un peu dommage de parler de système multi-agents (car c'est ça l'approche derrière le jeu de la vie, et derrière Jason) en se limitant à la problématique du contrôle interne de l'agent.
En effet, et en particulier avec cet exemple, toute la difficulté dans la conception de ce programme ne s'est pas retrouvée dans la programmation de l'agent lui-même.
La difficulté c'est d'avoir trouvé le bon comportement de l'agent de telle sorte que le système ait un comportement donné (plus ou moins spécifié ici).
De manière plus générale, l'approche BDI est super pour décrire le comportement de l'agent, mais il faut déjà l'avoir trouvé avant ça !
Il y a pleins de travaux sur comment, à partir d'un problème, on peut identifier les agents et trouver le « bon » comportement de chacun d'eux pour que le système est la fonctionnalité voulue, avec pleins de propriétés dites sefl-* à la clé (self-adaptative, self-organising, self-lol, self-mdr…).
Donc pour retrouver la question de départ, en terme de paradigme de programmation alternatifs, je parlerais plutôt des systèmes multi-agents et de la difficulté de raconter une solution à un problème du point de vue d'un agent et ce de manière locale.
Par exemple quand on regarde l'exemple du jeu de la vie, on voit que le comportement a été défini de façon purement locale, l'agent n'a aucune « conscience » (ce mot est à prendre avec des pincettes :) de la globalité du système !
On connaît tous l'exemple des fourmis qui trouve un plus court chemin alors que leur comportement est raconté sous forme d'interaction locales (déposer de la phéromone quand on revient avec de la bouffe, et suivre la phéromone quand on a pas de bouffe).
Bien sûr ces principes sont appliqués dans pleins d'autres domaines et amènent très souvent à des systèmes très résilients aux défaillances.
Voilà, perso j'aime pas trop les BDI, pas à cause de l'approche elle-même, mais parce que à chaque fois c'est la même chose, on se focalise sur l'idée d'avoir un agent, qu'il est « intelligent », etc, mais on se pose jamais la question de savoir comment faire un système. Et en somme, c'est bien beau les BDI, mais c'est pas ça qui fera qu'on aura des systèmes super intelligents, adaptatifs, magiques, etc, … (à mon avis :)
Là où je bosse (je travaille sur l'aide au développement des systèmes multi-agents), on fait des systèmes multi-agent auto-organisateurs et le « guide » qui nous aide à les faire est basé sur la notion de coopération. Face à un problème, on a des moyens d'identifier des agents, et ensuite toute la difficulté est de trouver le comportement coopératif des agents. Et ça revient à trouver des situations (très locales, du point de vu de l'agent) dans lesquelles les agents peuvent se retrouver et que l'on définit en tant que concepteur comme étant non-coopératives (par rapport au problème à résoudre) et on donne à l'agent un comportement qui va « réparer » cette situation quand il la détecte !
Ça marche et ça déchire :D
Note : perso, j'en fais pas tant que ça de ces systèmes, mais en tant que « expert » (dans l'équipe de recherche où je suis) de la programmation, du génie du logiciel, et tout ces trucs qui sont souvent très formels, je suis complètement convaincu que c'est ce genre de systèmes qui va faire le futur :) (et on va tous se faire buter par Skynet, toussa).
[^] # Re: Paradigme SMA
Posté par barmic . Évalué à 9.
Alors là je t'arrête tout de suite ça fait un moi que nous serions en guerre si c'était vrai !
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Paradigme SMA
Posté par Ontologia (site web personnel) . Évalué à 5.
Tu pointes un problème fondamental.
Je n'ai pas étudié les autres paradigmes SMA parce que j'ai une certaine attirance pour le BDI qui est très intéressant pour modéliser un agent un peu con, genre le grunt de Warcraft III.
BDI représente assez bien le modèle de comportement d'un humanoïde qui applique bêtement des ordres et des règles. J'ai l'autre jour passé quelques dizaines de minutes à observer des intérimaires sur une chaîne logistique, et bien que ce soit très cynique de dire ça, tu te rends compte que le BDI est parfaitement adapté pour décrire leur comportement (pour continuer dans le cynisme, la personne qui a mis au point l'organisation de cette chaîne logistique m'expliquait que ces intérimaires avaient horreur de devoir réfléchir).
Alors effectivement, en partant d'un langage BDI, où on va naïvement décrire l'agent et son comportement on risque de tomber sur de gros problèmes d'effet SMA où on aura des comportement émergents non prévus.
C'est donc un peu le but des recherches du type sur lesquelles tu travailles de mettre au point des méthodes pour pouvoir gérer ce problème;
Pour le reste, je me met dans la perspective où un langage de type BDI serait candidat à devenir un langage pour écrire des logiciels de gestion, des sites webs, etc... Le but n'est plus de simuler des fourmilières, mais de se placer sur le domaine des "machine de Turing améliorées".
Dans ce contexte, il faut analyser la population potentiellement visée.
Je ne sais pas si tu as déjà travaillé en SSII, mais si tu y traînes un peu tes guettres, tu verras que le panurgisme des ingénieurs est inversement proportionnel à leur niveau de compréhension des concepts de base. Faut voir à quel point ils maîtrisent mal des notions de base tel que l'héritage. Faut les voir s'extasier devant l'AOP à la Spring, qui est surement une (très) légère amélioration sur le plan du génie logiciel, mais qu'ils conçoivent comme une révolution géniale dans leur monde conceptuel étriqués.
Dans une population comme celle là, il s'agit de leur faire avaler le saut conceptuel de l'agent à l'objet, et de préserver ce qui est la pierre angulaire de l'acceptation de cette technologie : le déterminisme.
L'indéterminisme est inacceptable dans l'industrie logicielle, et ils auront bien plus l'impression de gérer le risque de l'indéterminisme avec des agents dont le comportement est hyper cadré, qu'avec des SMA où on fait émerger le comportement recherché.
Je pense que les approches dont tu parles seront l'étape suivante, mais à cette époque, on approchera de l'age de la retraite (qu'on aura pas).. ;-)
« Il n’y a pas de choix démocratiques contre les Traités européens » - Jean-Claude Junker
[^] # Re: Paradigme SMA
Posté par Victor . Évalué à 4.
Je suis globalement en accord avec toi, mais juste pour la complétude de la discussion, je me permet de revenir sur quelques points :)
Le truc c'est que le BDI en soit n'est pas du SMA, c'est juste de l'agent. Je pointais que le SMA me semblait intéressant à présenter (ce que j'ai fait :).
Oui mais non, ça dépend, ça dépend exactement dans quel cadre tu te places, mais typiquement si tu veux un logiciel d'optimisation, tu t'en fous qu'il soit déterministe ou pas, ce que tu veux c'est une bonne (même pas la meilleur) solution qui soit adaptable vite et bien. Chose que tu ne peux pas avoir avec des approches d'IA déterministes comme la programmation par contrainte.
Tu peux aussi avoir un comportement du système globalement déterministe, même si ce n'est pas le cas localement…
Enfin bon, on en est pas si loin.
D'ailleurs, juste pour me rapporter à ma propre expérience, il y a une boite qui applique ces technos en pratique (même si une partie de ses travaux sont effectivement dans des projets avec des partenaires de recherche).
Sinon le BDI, oui comme tu le décris, pourquoi pas…
Sur ce point, c'est un peu le hello world du domaine :) mais là où je dirais que ça se démarque de façon mature c'est plutôt dans tout les problèmes d'optimisation, d'exploration d'espèces complexes, d'apprentissage…
Allez, si vous cherchez une boite qui propose ses services dans le domaine, un peu de pub : http://www.upetec.fr/
[^] # Re: Paradigme SMA
Posté par Ontologia (site web personnel) . Évalué à 2.
Le truc c'est que le BDI en soit n'est pas du SMA, c'est juste de l'agent. Je pointais que le SMA me semblait intéressant à présenter (ce que j'ai fait :).
Bah justement. Je suis tout à fait d'accord que le SMA, la vrai prog SMA est intéressante voire passionante, j'aurai pu la présenter, mais je connais mal.
BDI, c'est juste de l'agent, et ça me va très bien : Quand on a l'habitude de coder objet, l'agent est un tel saut conceptuel que c'est déjà suffisament
difficile à avaler. Déjà que la plupart ne connaissent pas l'objet à prototype (qui est une passerelle entre les deux)...
Mais imagine qu'un jour si un langage de type BDI devient mainstream (au sens ou Ruby l'est : pas majoritaire, mais relativement connu), c'est la voie royale
pour aller vers la programmation multi-agent.
L'indéterminisme est inacceptable dans l'industrie logicielle
>
>Oui mais non, ça dépend, ça dépend exactement dans quel cadre tu te places, mais typiquement si tu veux un logiciel d'optimisation, tu t'en fous qu'il soit déterministe ou pas, ce que tu veux c'est une bonne (même pas la meilleur) solution qui soit adaptable vite et bien. Chose que tu ne peux pas avoir avec des approches d'IA déterministes comme la programmation par contrainte.
>Tu peux aussi avoir un comportement du système globalement déterministe, même si ce n'est pas le cas localement…
>Enfin bon, on en est pas si loin.
>D'ailleurs, juste pour me rapporter à ma propre expérience, il y a une boite qui applique ces technos en pratique (même si une partie de ses travaux sont effectivement dans des projets avec des partenaires de recherche).
Il est bien entendu que je me place dans le cadre de logiciel de gestions. C'est la seul chose que je connais à part la programmation de jeux.
Effectivement, il y a un tas de problème qu'une approche SMA résoud très bien, mais sur la distribution de type de logiciel qui existe dans le monde, c'est une
niche. Cela n'enlève rien que c'est très intéressant, et que c'est surement la meilleur réponse à ces problèmes !
« Il n’y a pas de choix démocratiques contre les Traités européens » - Jean-Claude Junker
# Intéressant
Posté par barmic . Évalué à 8.
Ton journal est très intéressant, je ne connaissais pas du tout le paradigme agent "BDI" et j'ai un mal fou à réellement le comprendre (c'est normal, il faut un peu de temps généralement pour ingurgiter un concept nouveau comme celui-là (comme pour les bases de données noSQL)).
Il y a un autre paradigme dont tu n'a pas parlé : la programmation orientée aspect.
La programmation orienté aspect se marie avec d'autres paradigmes comme l'objet ou l'impératif et a pour objectif de regrouper tout le code concernant des aspects transversaux de l'application au même endroit dans le code source.
Cela se traduit par un vocabulaire nouveau :
L'idée consiste à insérer des advices avant, après ou autour de pointcuts. Cela peut par exemple servir à créer un fichier de log en regroupant le code qui s'en occupe dans un aspect, servir a gérer un cache sans retouche les fonction qui génèrent les données, vérifier des invariants.
Quand c'est bien utilisé ça peut être très efficace, par contre lorsque c'est mal utilisé ça amène à du code particulièrement peu lisible car le moindre appel de méthode peut être détourné sans avoir aucune trace de se détournement dans le code autour de cet appel.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Intéressant
Posté par 🚲 Tanguy Ortolo (site web personnel) . Évalué à 1.
C'est marrant, je n'ai jamais pu trouver de description claire de la programmation orienté aspect. La tienne reste vague, comme la plupart de celles qu'on peut trouver. La plus précise qui m'en a été donnée m'a donné l'impression qu'il s'agissait simplement de monkey patching, c'est à dire de modification à l'exécution du code appelé, bref un truc bien sale et pas du tout pérenne…
[^] # Re: Intéressant
Posté par barmic . Évalué à 3.
Elle reste vague parce que je n'en ai pas beaucoup fait, que c'était il y a un an et que sortir du code pour montrer un exemple serait long (j'ai surtout vu AspectJ).
Ce dont tu parle c'est l'étape de tissage dont l'objectif et de positionner les greffons dans le code. Ça peut se faire a l’exécution, après la compilation ou avant celle-ci (ça dépend du langage d'aspect AspectJ fait ça avant l'étape de compilation ce qui est lourd mais permet d'obtenir au final un bytecode Java complètement conforme à la JVM).
Que cette étape de tissage soit sale, je comprends bien, ça viens du fait que c'est un paradigme qui s'est greffé à des langages existant (comme pour la programmation évènementielle), mais que ça ne soit pas pérenne je ne vois pas pourquoi (oui on peut faire des trucs moches avec mais c'est le cas de tout les paradigmes).
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Intéressant
Posté par ǝpɐןƃu∀ nǝıɥʇʇɐW-ǝɹɹǝıԀ (site web personnel) . Évalué à 8.
Et puis si les trucs moches étaient forcément destinés à disparaître à court terme, ça ferait longtemps que plus personne ne s’intéresserait à Picasso.
« IRAFURORBREVISESTANIMUMREGEQUINISIPARETIMPERAT » — Odes — Horace
[^] # Re: Intéressant
Posté par pasScott pasForstall . Évalué à 3.
Oula, non, rien a voir avec le monkey patching.
Le monkey patching c'est grosso modo remplacer une classe/methode de librairie bas niveau par la sienne generalement pour corriger un bug alakon.
C'est une pratique de grouik de tout dernier recours.
Genre tu veux corriger un bug dans le runtime de flex qui est connu et qu'adobe refuse de corriger.
Ca marche pas partout, bon courage pour monkey patcher la class String de java par exemple.
L'aop, c'est grosso modo "avant chaque appel de methode qui s'appelle foo, tu feras tourner ce bout de code la".
En gros tu veux faire tourner du code avant ou apres, avec des conditions hautement dynamiques, basee sur le nom du methode, la classe de l'objet appelant, la valeur d'un des parametres ou l'age du capitaine.
Mais en aucun cas tu ne modifies le comportement de la methode appellee, contrairement au monkey patching dont c'est la raison d'etre.
En gros, c'est tres pratique pour la transactionalite, eventuellement pour du logging (encore que c'est franchement tire par les cheveux) et c'est a peu pres tout.
Faire quoi que ce soit d'autre avec te retomberas tres probablement sur la gueule un jour.
C'est un enfer a debugger, personne de sain ne l'envisagerais serieusement en tant que paradigme de programmation a part entiere. Et meme pour les transactions, un bon vieux proxy des familles fait bien mieux l'affaire.
Si vous me croyez pas, configurez une transactionalite dans spring avec proxy + @transactional, et tentez de faire pareil avec spring aop.
C'est moins souple, certes mais au moins ca te pete pas a la gueule sans raison et surtout, on voit ce qu'il se passe.
Rajoutez par dessus que certains framework aop requierent d'aller faire le con avec le bytecode ou de compiler specialement les classes aopiser, si rien que ca vous convainc pas que c'est une mauvaise idee...
If you can find a host for me that has a friendly parrot, I will be very very glad. If you can find someone who has a friendly parrot I can visit with, that will be nice too.
[^] # Re: Intéressant
Posté par barmic . Évalué à 2.
J'avais vu un exemple en python qui consiste à prendre une fonction, par exemple factoriel et sauvegarder ses résultats après chaque appel et à vérifier avant chaque appel que si le résultat n'a pas déjà était calculé. Le tout sans modifié la fonction initial (et on peu facilement passer d'un cache interne à l'application (une table de hashage) à une base de données noSQL de type clef valeur).
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Intéressant
Posté par pasScott pasForstall . Évalué à 3.
L'exemple est amusant, certes mais implementer un cache quel qu'il soit en aop, c'est de la pure folie.
Soit c'est un petit cache local sans importantce (ton exemple de factorielle), t'auras plus vite fait de cacher manuellement, ca sera clair pour tout le monde et tu risques pas de cacher quelque chose qui ne devrait pas l'etre ou inversement.
Un cache, ca vient avec des regles claires et visibles, pas en douce derriere ton dos, les repercutions et effets de bords sont trop importants pour etre glisse sous le tapis. Tu peux pas juste cacher tout en n'importe quoi au ptit bonheur la chance.
Que fais tu quand tes regles vont evoluer (et elles le feront), qu'il va falloir invalider le cache pour une raison x ou y? Tu vas commencer a rajouter des cutpoint a droite a gauche, t'etales toute ta logique de gestion du cache de partout, tout devient obscur et tu t'en sort plus.
Au lieu d'avoir un point central ou tout passes (ce qui est un peu le concept du cache), tu repartis tout ca dans le systeme, ce qui est generalement le contraire de ce que tu veux faire.
Mets moi tout cas dans une classe, injectes en une insance, ecrit un service locator ou un singleton si tu peux pas faire autrement. Plus simple, beaucoup plus robuse, infiniment plus clair et tu sais ou aller voir quand ca chie.
Aller faire un tour chez nosql (ou meme sql) derriere le dos de l'appelant sans qu'il ait aucun controle dessus ni meme le moindre moyen de savoir si ca va faire un appel reseau ou pas, c'est une tres mauvaise idee.
Ca me rappelle foutrement corba par exemple et ceux qui y sont alles en sont tous revenu en ayant mal aux fesses.
Tu fais un appel innoncent a une methode sur ton thread d'ui et paf, tu te manges 500ms de delai dans la gueule, mais pas toujours, ton interface freeze et tu passes deux jours a trouve le coupable.
Ou tu fais une utilisation en apparenence innocente de ton api et en profilant tu te rends compte que ta base mango tourne a fond les ballons et que tu passes la plupart de tes ressources dans des appels reseaux.
Tu changes ton nom de methode ou de classe, et paf 100% de cache miss en permanence.
T'ecris une autre methode qui appelle un autre objet qui en appelle un autre et tu te retrouves avec une file monstrueuse d'aspect qui s'executent et le pire c'est que t'es meme pas au courant qu'ils pourraient simplement exister, toi t'as juste vu la pointe de l'iceberg.
C'est exactement le genre de cas ou il ne faut PAS utiliser l'aop, parce que ca va te peter a la gueule dans des cas subtils et tu vas passe un temps monstrueux a trouver le probleme pour potentielleme te rendre compte que t'es baise et que tu peux pas t'en sortir sans peter qq chose.
Le concept reste interressant et bon a connaitre, mais a n'utiliser qu'avec tres grande parcimonie.
If you can find a host for me that has a friendly parrot, I will be very very glad. If you can find someone who has a friendly parrot I can visit with, that will be nice too.
[^] # Re: Intéressant
Posté par barmic . Évalué à 3.
Ce que tu dis c'est simplement qu'il faudrait pouvoir voir dans le code initial qu'un greffon a était placé (un peu comme python avec les décorations).
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Intéressant
Posté par pasScott pasForstall . Évalué à 2.
Ben ouais, mais c'est un peu a l'oppose de la philosophie aop justement :)
Le but de l'aop c'est precisement que l'appelant n'ai pas la moindre idee de ce qu'il va se passer avant, pendant ou apres, et c'est precisement pour ca que c'est le plus souvent une mauvaise idee.
Et ca change pas le probleme quand tu imbriques tes appels, t'es pas au courant que a va appeler b. C'est impossible a documenter sans devenir chevre.
Je connais pas les decorators pythons, c'est une implem du pattern eponyme?
If you can find a host for me that has a friendly parrot, I will be very very glad. If you can find someone who has a friendly parrot I can visit with, that will be nice too.
[^] # Re: Intéressant
Posté par barmic . Évalué à 4.
En quelque sorte sauf que ça s'applique à des méthode et pas à des objets et que ce n'est pas dynamique (c'est à la déclaration de la méthode que tu la décore).
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Intéressant
Posté par pasScott pasForstall . Évalué à 0.
ok, mais ca reste toujours a l'oppose de l'aop.
La decoration implique une volonte de la part du designer (tu peux pas la rajouter apres coup, faut que ta classe ait ete pensee decoration), ca se voit dans les constructeurs (un constructeur qui prend une instance de son interface, c'est dur de rater), et surtout, surtout, tu recuperes des instance d'une classe donnee.
Tu fais un step into et paf, tu vois ce qui est rajoute avant ou apres.
Bref, ca revient a ce que je disais plus haut, l'aop ne resoud pas grand chose que d'autres patterns explicite ne peuvent resoudre, et apporte son lot de pb qui vont rendre tes developeurs malheureux.
If you can find a host for me that has a friendly parrot, I will be very very glad. If you can find someone who has a friendly parrot I can visit with, that will be nice too.
# Subjectivité malvenue
Posté par reno . Évalué à 3.
Appeler la programmation évènementielle un hack franchement c'est osé!
Pour moi ce terme inclue aussi Estérel, FRP et bien d'autre chose intéressante.
[^] # Re: Subjectivité malvenue
Posté par Ontologia (site web personnel) . Évalué à 2.
J'appelle ça de la programmation réactive justement. Et ça n'a rien à voir. Esterel c'est la machine à état hiérarchique réactive..
« Il n’y a pas de choix démocratiques contre les Traités européens » - Jean-Claude Junker
[^] # Re: Subjectivité malvenue
Posté par reno . Évalué à 3.
Dans la page de Wikipedia sur la programmation réactive,
il y a "Reactive programming has principal similarities with the Observer pattern" le pattern de l'observer étant justement celui du signal/slot de Qt..
Alors dire que ça n'a rien à voir..
[^] # Re: Subjectivité malvenue
Posté par Ontologia (site web personnel) . Évalué à 2.
Effectivement, tu as raison, c'est chipoter sur les termes..
J'ai un ego moi ! Faut bien que je me raccroche aux branches !
La prochaine fois, si j'en fais un je parlerai d'Esterel, promis. Surtout qu'il m'avait été présenté, et c'est vrai que la capacité de cet outil de te sortir un contre exemple qui respecte pas tes contrats et donc te prouve que ton algo est faux, c'est assez impressionnant..
« Il n’y a pas de choix démocratiques contre les Traités européens » - Jean-Claude Junker
Suivre le flux des commentaires
Note : les commentaires appartiennent à celles et ceux qui les ont postés. Nous n’en sommes pas responsables.