
À l'occasion de la sortie toute récente de la version 1.6.2.0 de G'MIC (GREYC's Magic for Image Computing), framework libre pour le traitement d'image, je vous propose de poursuivre ma petite série d'articles de résumés sur les avancées de ce logiciel libre sympathique, voire indispensable aux traiteurs d'images.
Cette dépêche présente un ensemble significatif des nouveautés ajoutées à G'MIC depuis la version 1.5.9.3 présentée il y a environ 10 mois, à savoir l'apparition de nouveaux traitements liés à la couleur, l'aide au détourage avant-plan / arrière-plan, de nouveaux filtres artistiques et d'autres faits notables.
Sommaire
- 1. Le projet G'MIC : contexte et présentation.
- 2. Nouveaux traitements liés à la couleur.
- 3. Aide à la décomposition avant-plan / arrière-plan.
- 4. Nouveaux filtres artistiques.
- 5. Autres faits notables.
- 6. Perspectives et conclusions.
1. Le projet G'MIC : contexte et présentation.
![]()
Fig.1. Mascotte et logo du projet G'MIC, framework libre pour le traitement d'image.
Le projet G'MIC a vu le jour en Août 2008, dans l'équipe IMAGE du laboratoire GREYC (Unité Mixte de Recherche du CNRS, située à Caen) et évolue depuis à un rythme soutenu. Il est distribué sous licence libre CeCILL.
Il propose plusieurs interfaces utilisateurs pour la manipulation d'images génériques (images ou séquences d'images 2D ou 3D, multi-canaux, à valeurs flottantes, incluant donc les images couleurs classiques).
Son interface la plus populaire aujourd'hui est un greffon disponible pour le logiciel GIMP.

Fig.1.1. Aperçu du greffon G'MIC pour GIMP.
Mais G'MIC peut aussi s'utiliser en ligne de commande, de façon similaire à ImageMagick (pour des fonctionnalités optimales), ou directement via la page web G'MIC Online. D'autres interfaces existent (ZArt, un greffon pour Krita, des greffons pour Photoflow…) mais celles-ci restent pour le moment plus confidentielles.
Toutes ces interfaces se basent sur la bibliothèque libgmic, écrite en C++, portable, thread-safe et multi-threadée (via l'utilisation d'OpenMP notamment), qui implémente toutes les fonctions de calculs proprement dites, et qui embarque son propre langage de script permettant aux utilisateurs avancés d'y ajouter leurs fonctions personnalisées de traitement d'image. Aujourd'hui, G'MIC comprend plus de 900 commandes de traitement différentes, toutes paramètrables, pour une bibliothèque d'un peu moins de 5 Mo. Les commandes que propose G'MIC couvrent un large spectre du traitement d'image, avec des algorithmes pour la manipulation géométrique, les changements colorimétriques, le filtrage (débruitage, rehaussement de détails par méthodes spectrales, variationnelles, non-locales…), l'estimation de mouvement / le recalage, l'affichage de primitives, la détection de contours/la segmentation, le rendu d'objets 3d, le rendu artistique, etc.
C'est un ensemble d'outils très utiles, d'une part pour convertir, visualiser et explorer des données images, et d'autre part pour la construction de pipelines élaborés de traitements.
Il est entendu qu'étant le programmeur principal de ce logiciel, les avis que je vais exprimer ci-dessous sont totalement partiaux et mon enthousiasme forcément débordant.
2. Nouveaux traitements liés à la couleur.
Voici quelques unes des nouvelles commandes et filtres qui ont été ajoutés dans G'MIC récemment, et qui concernent la création ou la modification de couleurs dans des images.
Application de courbes dans des espaces couleurs quelconques.
Le concept de courbes de couleurs est bien connu des artistes et photographes désirant retoucher les couleurs de leurs images. Basiquement, un outil de courbes de couleur permet d'appliquer à chaque composante R,G,B d'une image, une fonction 1d continue f:[0,255] -> [0,255] qui va transformer chaque valeur rouge, verte ou bleue x de chaque pixel (supposée initialement comprise entre 0 et 255) en la valeur f(x) donnée par la courbe (fonction) définie par l'utilisateur (et dont les valeurs sont également comprises entre 0 et 255). Très souvent, ces fonctions sont construites par l'utilisateur, par la donnée de quelques points clés interpolés par des splines.
Mais que se passe-t-il si l'on veut appliquer une fonction de transformation des composantes couleurs dans un espace colorimétrique autre que RGB ? Et bien, on se brosse… Parce que la plupart des logiciels de retouche d'image ne permettent que l'application de courbes couleurs dans l'espace RGB.
Depuis peu, j'ai donc intégré dans G'MIC un outil de réglage de courbes couleurs dans des espaces colorimétriques autres que RGB, à savoir : CMY, CMYK, HSI, HSL, HSV, Lab, LCh ou YCbCr. C'est la commande -x_color_curves qui s'occupe de cette tâche (en ligne de commande), ou le filtre Colors / Curves [interactive] dans le greffon G'MIC pour GIMP. Un exemple d'utilisation est visible dans la figure ci-dessous (ici avec des courbes définies dans l'espace Lab). Un tutoriel vidéo d'utilisation de ce filtre dans le greffon est également disponible. L'utilisation du filtre dans le greffon permet, par ailleurs, de sauver ses courbes favorites pour une application ultérieure sur un lot d'images par exemple.

Fig.2.1. Définition interactive de courbes de couleurs dans l'espace colorimétrique Lab et application sur une image couleur. À gauche, les courbes définies par l'utilisateur pour les 3 composantes L (clarté), a et b (chrominances). À droite, le résultat de la transformation colorimétrique correspondante.
Colorisation de BD / Comics.
C'est en discutant avec David Revoy, illustrateur français de talent, et auteur entre autres du webcomics Pepper & Carrot (dont les moules de LinuxFr.org ont parlé dans ce journal, ou encore celui-ci), qu'a germé l'idée d'un filtre qui pourrait aider les dessinateurs de BD à coloriser leurs images. Le travail de colorisation d'une BD est en effet quelque chose de long et de contraignant, même sur ordinateur, comme l'explique David Revoy sur son blog.
Il existe déjà des outils d'aide à la colorisation, mais ceux-ci sont fermés, et il y avait donc un manque de ce côté-là pour les utilisateurs de logiciels libres.
J'ai donc pris mon courage (plutôt mon clavier) à deux mains, et j'ai implémenté dans G'MIC un filtre d'interpolation de couleurs « intelligent » (toute mesure gardée) qui essaye de générer un calque complet de couleurs, à partir seulement d'un nuage de points colorés. L'idée est de demander à l'illustrateur de positionner seulement quelques points-clés colorés sur son image (par exemple à l'intérieur des différentes zones), et de laisser l'algorithme en déduire une colorisation probable de tout le dessin (en analysant les contours et les objets qu'il contient). Avec David Revoy et Timothée Giet nous avons échangé via irc sur la façon d'avoir une interface de colorisation la plus intuitive possible, et le résultat, c'est une nouvelle commande G'MIC -x_colorize (utilisable en ligne de commande) et le filtre correspondant Black & White / Colorize [interactive] pour le greffon G'MIC de GIMP . Et apparemment, ça ne marche pas trop mal !
Il semblerait même que cet unique algorithme ait suffisamment intéressé les utilisateurs de Krita pour qu'il motive les développeurs à retravailler sur leur propre greffon G'MIC pour Krita pour inclure cet algorithme dedans.
Depuis, David Revoy a utilisé cet algorithme régulièrement pour ses créations (notamment pour Pepper & Carrot). Ci-dessous, vous pouvez voir un exemple d'une phase de colorisation d'une case de BD de Pepper & Carrot initialement en niveau de gris, avec l'ajout des points-clés colorés et le résultat de la colorisation réalisée par l'algorithme de G'MIC (tout ceci réalisé avec le greffon sous Krita).
Sur son site, David a posté des vidéos détaillant tout le processus de colorisation qu'il utilise, et dont G'MIC fait maintenant partie.

Fig.2.2. Utilisation de G'MIC pour la colorisation de BD : Étape 1, ouverture du dessin à coloriser, ici sous Krita.
(Cette image provient du site web de David Revoy : http://www.davidrevoy.com/article240/gmic-line-art-colorization)

Fig.2.3. Utilisation de G'MIC pour la colorisation de BD. Étape 2, mise en place de quelques points-clés couleurs et colorisation automatique obtenue par G'MIC.
(Cette image provient du site web de David Revoy : http://www.davidrevoy.com/article240/gmic-line-art-colorization)
Après cette première étape de colorisation automatique, l'artiste peut ajouter à sa guise ombres et lumières sur les aplats couleurs générés, pour finaliser son œuvre. À noter que cette dernière étape est facilitée car chaque couleur est, de fait, facilement sélectionnable de manière séparée sur le calque couleur généré par l'algorithme. Et, pour ceux qui préfèrent travailler sur des calques de couleurs séparés plutôt que sur des sélections, le filtre de colorisation propose aussi la possibilité de générer N calques couleurs de sortie, chacun contenant une couleur unique.
Encore un grand merci donc à David Revoy et Timothée Giet pour leurs retours enthousiastes et pédagogiques, nous disposons donc maintenant d'un outil de colorisation de BDs libre que mon dentier nous envie :)
Voilà un exemple de collaboration entre recherche académique et artistes "libres" qui a porté ses fruits.
Colorisation de photographies Noir & Blanc.
Mais ce qu'on peut faire avec des BDs, peut-on le faire avec de vieilles photographies en noir et blanc, me demanderez-vous ? Hé bien oui ! En modifiant légèrement l'algorithme, nous pouvons de la même manière reconstruire la chrominance d'une photographie initialement en niveaux de gris, pour la coloriser à partir de points-clés couleurs définis par l'utilisateur. C'est ce qu'illustre l'exemple ci-dessous, avec la colorisation d'une vieille photo d'indien. À noter que le contenu de l'image étant sensiblement plus complexe qu'une case de BD, il est souvent nécessaire de placer beaucoup plus de points-clés pour coloriser une photographie. C'est le même filtre que précédemment, à savoir Black & white / Colorize [interactive] dans le greffon G'MIC pour GIMP, qui permet cela.

Fig.2.4. Colorisation d'une vieille photo Noir & Blanc avec l'algorithme de colorisation de G'MIC. (Ugh, vieil indien, excuse-moi pour la couleur improbable de tes cheveux, qui te fait ressembler à Kim Kardashian…)
{kind=link}
Transfert de couleurs.
Ici, le concept de « transfert de couleurs » correspond au fait de vouloir modifier les couleurs d'une image A en les remplaçant par les couleurs présentes dans une autre image B (l'image de référence), de telle sorte que l'image modifiée A' ait la même « ambiance colorimétrique » que l'image référence B, et ceci bien évidemment, de manière complètement automatique.
C'est un problème mal posé, complexe à résoudre, et il y a déjà pas mal d'articles de recherche parus à ce sujet (ce papier par exemple). La difficulté c'est d'arriver à générer une image A' en gardant un aspect « naturel », sans création d'aplats de couleurs ou au contraire sans apparition de discontinuités qui ne seraient pas présents initialement dans l'image A originale. Bref, ce n'est pas trivial.
Récemment, un algorithme de transfert de couleurs a été implémenté et intégré dans G'MIC, et il fonctionne de façon plutôt satisfaisante. Ce n'est pas parfait, certes, mais c'est un bon début. Le filtre Colors / Transfer colors [advanced] du greffon G'MIC pour GIMP permet d'appliquer facilement cet algorithme de transfert. C'est un filtre qui nécessite plusieurs calques d'entrée, dont un calque contenant l'image avec les couleurs de référence à transférer sur les images des autres calques. Voici comment cela se présente dans le greffon. On y voit l'image originale (à gauche dans la fenêtre de prévisualisation), l'image contenant les couleurs de référence (en bas à gauche), et l'image résultat (à droite).

Fig.2.5. Aperçu du filtre de transfert de couleurs dans le greffon G'MIC pour GIMP.
Ce filtre réalise parfois des merveilles avec certaines paires d'images ! Deux exemples de transfert sont illustrés sur la figure ci-dessous. Bien sûr n'espérez pas de résultats miraculeux avec des cas pathologiques (transfert d'une image avec plein de couleurs sur une image monochrome par exemple) ! Mais globalement, ça fonctionne pas mal.


Fig.2.6. Deux exemples de résultats de transfert de couleurs d'une photo de référence (image du milieu) vers une photo source (image de gauche). Les images de droite sont les résultats générés par l'algorithme de transfert de G'MIC.
Il existe également un tutoriel vidéo qui illustre comment faire fonctionner ce filtre dans le greffon G'MIC pour GIMP.
On peut également penser à d'autres applications plus « subtiles » de ce filtre, par exemple pour l'homogénéisation de couleurs entre les frames ou les plans successifs d'une même vidéo, ou d'une paire d'images stéréoscopiques, par exemple.
Simulation de films argentiques.
Pat David est un photographe amateur américain très actif dans la communauté du logiciel libre orienté photographie, de par ses tutoriels et son expérience qu'il partage sur son blog. J'ai eu la chance d'interagir avec lui à de nombreuses occasions (dont une rencontre en live à LGM'2014 à Leipzig), et cela a donné naissance à pas mal de filtres différents implémentés dans G'MIC. En particulier, nous avons proposé des filtres de simulation de films argentiques, comme ceux présentés ci-dessous. C'est seulement un petit échantillon des plus de 300 transformations couleurs qui ont été concoctées par Patrick et que nous avons rendu facilement accessibles.

Fig.2.7. Aperçu de quelques résultats de simulation de films argentiques, disponibles dans G'MIC.
(Cette image provient du site web de Pat David : http://blog.patdavid.net/2013/08/film-emulation-presets-in-gmic-gimp.html)
Ces filtres ont assez vite suscité un certain intérêt dans la communauté libre de retouche photo, et ont par la suite été repris et ré-implémentés dans le logiciel RawTherapee.
Pour rendre ces filtres encore plus visibles, une page web dédiée a été mise au point, qui recense l'ensemble des transformations couleurs proposées et propose de télécharger les CLUTs (fonctions de transfert) utilisées pour chaque transformation. À noter que vous pouvez retrouver ces filtres également sur G'MIC Online pour les tester directement sur vos propres images, directement via votre navigateur web.
Là encore, c'est une fonctionalité qui manquait dans le logiciel libre (une sorte d'équivalent du logiciel propriétaire DXO FilmPack), et qui a pu être comblée assez rapidement via l'infrastructure proposée par G'MIC.
3. Aide à la décomposition avant-plan / arrière-plan.
Quand on fait de la retouche photo, il est assez courant que l'on veuille traiter de manière séparée les objets présents à l'avant-plan et dans le fond. Pour cela, on a souvent besoin de faire une décomposition d'image en avant-plan/arrière plan, en effectuant un détourage (avec l'outil de sélection "lasso" par exemple). Pour des objets un peu complexes, réaliser cette sélection est quelque chose de fastidieux. G'MIC incorpore maintenant un filtre permettant d'accélérer ce travail de découpe des objets. C'est la commande -x_segment (en ligne de commande) ou le filtre Contours / Extract foreground [interactive] du greffon G'MIC pour GIMP qui permet de réaliser cette tâche.
Le principe est exactement le même que pour le filtre de colorisation présenté précédemment : L'utilisateur place des points-clés, ayant pour label soit « avant-plan », soit « arrière-plan », et l'algorithme interpole ces labels en prenant en compte les contours présents dans l'image, et en déduit ainsi une carte binaire de détourage. Le filtre décompose ensuite l'image en deux calques distincts, un calque contenant les points d'avant-plan uniquement, et un autre avec les points d'arrière-plan. La figure ci-dessous présente un exemple de détourage effectué en utilisant ce filtre : L'utilisateur place quelques points-clés sur une image originale d'une fleur (image en haut à gauche). Les points verts correspondent aux objets d'avant-plan, tandis que les rouges sont placés dans le fond (image en haut à droite). À partir de ces données très éparses, et de l'analyse des contours de l'image, le filtre détermine automatiquement pour chaque pixel son appartenance au calque d'arrière-plan (image en bas à gauche) ou d'avant-plan (image en bas à droite).
Effectuer ce détourage ne prend ici que quelques secondes, alors que la même opération effectuée manuellement serait beaucoup plus longue (le contour de la fleur n'ayant pas une forme simple). Un tutoriel vidéo illustrant l'utilisation de ce filtre dans le greffon G'MIC pour GIMP est disponible.

Fig.3.1. Décomposition avant-plan / arrière plan avec le filtre « Contours / Extract foreground » de G'MIC.
Cette décomposition de l'image d'origine permet par la suite d'appliquer des traitements différenciés sur l'avant-plan et sur l'arrière-plan. Par exemple ci-dessous nous modifions la teinte et la saturation du calque d'avant-plan uniquement, pour jouer sur la couleur de la fleur, sans modifier la couleur de l'arrière-plan. Le détourage d'objet étant un besoin très fréquent en retouche photo, je vous laisse imaginer le nombre d'utilisations possibles de ce filtre.

Fig.3.2. Après modification de la teinte et de la saturation des couleurs de l'avant-plan uniquement.
4. Nouveaux filtres artistiques.
G'MIC, c'est aussi tout une floppée de filtres amusants pour créer des effets artistiques sur vos images. En voici quelques-uns notables qui ont été ajoutés dernièrement.
Effet gravure.
Le filtre Black & White / Engrave tente de transformer une image en gravure. Le nombre relativement élevé de paramètres permet d'obtenir beaucoup de contrôle sur le type de rendu obtenu.

Fig.4.1. Aperçu du filtre « Gravure » dans le greffon G'MIC pour GIMP.
Là où ce filtre est particulièrement intéressant, c'est qu'il permet (en choisissant des paramètres adaptés) de transformer une image en version Comics, comme illustré avec les deux exemples ci-dessous. Un tutoriel vidéo existe également pour montrer les différentes étapes nécessaires à l'obtention de ce type de résultats, qui ne prend au final que quelques secondes (minutes pour les plus lents).

Fig.4.2. Conversion de photo (en haut à gauche) sous forme de dessin façon Comics, avec le filtre "Engrave" de G'MIC.

Fig.4.3. Conversion d'une photo de chimpanzé (à gauche) sous forme de dessin façon Comics (à droite), avec le filtre "Engrave" de G'MIC.
Triangulation de Delaunay.
Un algorithme de calcul de la triangulation de Delaunay 2D/3D a été ajoutée à G'MIC (commande -delaunay3d), et le filtre Artistic / Polygonize [delaunay] du greffon GIMP l'utilise pour transformer une image sous la forme d'ensemble de triangles de Delaunay, qui s'adaptent plus ou moins aux contours de l'image. Chaque triangle généré peut prendre une couleur, soit aléatoire, soit constante, soit liée aux pixels de l'image qui appartiennent au triangle.
C'est un filtre permettant de créer des abstractions géométriques intéressantes.

Fig.4.4. Aperçu du filtre "Polygone [delaunay]" et application sur une image pour un rendu de type "vitrail".
C'est un filtre qui donne également des choses sympathiques sur des séquences d'images. Je me demande si l'importation de ces images triangulées sous Blender n'aurait pas un intérêt (et même plus loin, carrément un greffon G'MIC pour Blender ?).

Fig.4.5. Application de la triangulation de Delaunay sur une séquence d'images.
Autres filtres artistiques, en vrac.
Comme vous le voyez, G'MIC est un projet assez actif et le nombre de filtres disponibles (notamment artistiques) augmente de manière assez régulière. On ne peut donc pas décrire en détails tous les ajouts de ces dix derniers mois, et comme quelques images valent mieux qu'un long discours, voici un aperçu rapide de quelques-uns de ces filtres, présenté dans les figures ci-dessous.

Fig.4.6. Aperçu du filtre "Arrays & Tiles / Grid [hexagonal]", potentiellement utile pour les créateurs de cartes des jeux de type Wargames ?

Fig.4.7. Aperçu du filtre "Patterns / Crystal" qui transforme vos images en cristaux multicolores.

Fig.4.8. Aperçu du filtre "Rendering / Lightning" qui dessine un éclair dans une image.

Fig.4.9. Aperçu du filtre "Arrays & Tiles / Ministeck" qui transforme vos images en représentation de type Ministeck (jeu pour enfants).

Fig.4.10. Aperçu du filtre "Sequences / Spatial transition", qui prend en entrée plusieurs calques et qui génère une séquence d'images de transition entre chaque calque consécutif, avec des motifs de transition réglables.
5. Autres faits notables.
Bien sûr, les quelques filtres présentés ci-dessus ne constituent qu'une toute petite partie (la plus visible) du travail effectué sur le code du projet G'MIC durant ces derniers mois. Voici en vrac, les autres aspects (plus techniques) du logiciel qui ont été améliorés.
Améliorations globales et bibliothèque libgmic.
Énormément d'efforts ont été faits pour le nettoyage et l'optimisation du code : la taille de la bibliothèque libgmic a pu être réduite drastiquement (moins de 5 Mo actuellement), avec une API améliorée. L'utilisation de quelques fonctionnalités du C++11 (rvalue-references) permet d'éviter les copies intempestives de buffers temporaires, ce qui est vraiment appréciable dans le cas du traitement d'image où la mémoire allouée devient vite importante. Avec l'aide de Lukas Tvrdy développeur de Krita, nous avons pu améliorer la compilation du projet sous Visual Studio (Windows), appliquer des analyseurs statiques de code (PVS Studio), empiler des sessions de valgrind / gprof / g++ avec l'option -fsanitize=address pour obtenir un code plus propre et plus efficace. Pas vraiment drôle pour les développeurs, mais au final très satisfaisant pour l'utilisateur ! La conséquence directe de ce processus est de pouvoir proposer des versions pre-release intermédiaires qui restent stables tout en incorporant les dernières nouveautés ajoutées. La méthode de distribution de G'MIC se rapproche ainsi d'une méthode rolling-release.
La compilation du projet sous Windows a été également améliorée, avec l'utilisation de g++-4.9.2 / MinGW comme compilateur par défaut pour la génération des binaires, et la création d'installeurs pour les architectures 32 bits et 64 bits.
G'MIC possède de nouvelles commandes pour compresser/décompresser des données quelconques à la volée (via l'utilisation de la zlib). De cette façon, nous avons pu réduire la taille des définitions de commandes, des exécutables, et accélérer le processus de mise à jour des filtres via Internet.
Le projet G'MIC possède maintenant son propre nom de domaine http://gmic.eu, indépendant de SourceForge, son ancien hébergeur. Nous avons enrichi le contenu des pages web, grâce notamment à de très bons tutoriels sur l'utilisation de l'outil gmic en ligne de commande (écrits par Garry Osgood, un grand merci à lui !). Une page à retenir pour tous ceux qui voudraient se mettre à G'MIC en douceur.
Quelques nouveautés pour le filtrage d’images.
Pas mal de nouvelles commandes dédiées au filtrage d'image, et leurs entrées associées dans le greffon G'MIC pour GIMP ont été ajoutées : en vrac, des algorithmes de sharpening ("Mighty Details"), de déconvolution par noyau arbitraire (algorithme de Richardson-Lucy), de filtrage guidé rapide, de Non-Local-Means rapide, de régularisation type Perona-Malik, de filtrage rapide à support fini, de DCT (et son inverse) sont maintenant disponibles.
G'MIC possède aujourd'hui une foultitude d'opérateurs pour le filtrage linéaire et non-linéare d'image, qui en fait un logiciel libre à posséder absolument pour les traiteurs d'image de tout poil (ne serait-ce pour les méthodes de débruitage qu'il propose). Pour les utilisateurs du greffon, cela signifie potentiellement des filtres encore plus riches dans le futur. Ci-dessous, un aperçu d'application du filtre Details / Mighty details sur une image de portrait, à partir du greffon pour GIMP, pour un effet de type Dragan.

Fig.5.1 Application du filtre « Mighty Details » sur un portrait pour le rehaussement de détails.
Amélioration du greffon G'MIC pour GIMP.
Le greffon G'MIC pour GIMP étant l'interface de G'MIC la plus utilisée à ce jour, il était important de lui apporter son lot d'améliorations :
Le greffon possède maintenant un système de mise à jour automatique qui permet d'avoir une liste de filtres avec toutes les dernières améliorations/nouveautés. Au jour de la sortie de la version 1.6.2.0, le greffon possède 430 filtres différents à appliquer sur vos images, auxquels s'ajoutent 209 filtres qui sont considérés comme étant en phase de test (Catégorie Testing/). Pour un greffon de 5,5 Mo, on peut considérer que ça fait un bon rapport nombre de filtres / mémoire occupée ! Une liste de l'ensemble des filtres disponibles dans le greffon est visible ici.
Lors de l'exécution d'un filtre un peu gourmand en temps de calcul, le greffon affiche maintenant quelques informations sur le temps écoulé et l'utilisation mémoire du filtre dans la barre de progression correspondante.

Fig.5.2. Affichage des ressources prises par un filtre dans le greffon G'MIC pour GIMP.
L'interface du greffon a été améliorée : la fenêtre de pré-visualisation est plus précise dans le cas des filtres prenant plusieurs calques en entrées. Les filtres peuvent être maintenant interactifs : ils peuvent ouvrir leur propre fenêtre de visualisation et gérer des évènements provenant de l'utilisateur. Un filtre peut également décider de modifier l'interface de ses paramètres. Tout ceci nous a permis de proposer de nouveaux filtres interactifs intéressants, comme celui pour la colorisation de BDs, pour le réglage des courbes couleurs, ou encore pour l'extraction d'objets (décrits plus haut), qu'il n'était pas possible de réaliser dans le greffon pour GIMP précédemment (ça n'était possible qu'avec l'outil gmic en ligne de commande).
Les filtres du greffon ont maintenant connaissance des informations de base des calques d'entrées (label, position, opacité, mode de mixage), et peuvent modifier ces informations sur les calques de sortie.
Un nouveau filtre About / User satisfaction survey a été ajouté, permettant aux utilisateurs de donner quelques informations sur leur utilisation de G'MIC. Le résultat de ce sondage est visible en temps réel ici. Bien sûr, cette image est elle-même générée par une commande G'MIC :).
{kind=link}
Débrider G'MIC : utilisation en ligne de commande.
gmic est l'interface « ligne de commande » de G'MIC, qui s'utilise à partir d'un shell. C'est l'interface la plus puissante de G'MIC, sans limitations inhérentes aux contraintes d'entrées-sorties des autres interfaces (par exemple, images 2D à 8bits/canal et 4 canaux maximum sous GIMP, une seule image d'entrée 2D avec G'MIC Online, etc.). Ici, on peut charger/sauver et manipuler des séquences d'images 3D multi-canaux à valeurs flottantes sans limites (autres que la mémoire disponible). L'interface ligne de commande a également connu son lot d'améliorations.
- OpenCV est maintenant utilisé par défaut pour charger/sauver des séquences d'images. On peut donc appliquer des traitements frame par frame sur des vidéos (commande -apply_video), des streamings de la webcam (command -apply_camera), ou générer des fichiers vidéos à partir d'images fixes par exemple. De nouvelles commandes -video2files et -files2video pour décomposer des fichiers vidéos en plusieurs frames ou les recomposer ont été ajoutées. Le traitement de fichiers vidéos devient maintenant (presque) un jeu d'enfant avec G'MIC en ligne de commande ! L'aide (commande -h) a également été améliorée, avec une sortie en couleur, des corrections proposées en cas d'erreur de frappe sur une commande, des liens éventuels vers des tutoriels, etc.

Fig.5.3. Aperçu du fonctionnement de l'aide en ligne de commande.
- L'appel à gmic sans arguments en ligne de commande active maintenant un mode démo où l'on peut sélectionner différentes petites animations interactives à partir d'un menu, pour voir ce que G'MIC a dans le ventre ! Une bonne occasion pour jouer à Pacman, Tetris ou au démineur en prétextant le fait de tester un logiciel de traitement d'images sérieux !

Fig.5.4. Aperçu de G'MIC, lancé en mode démo !
Autres interfaces G’MIC en cours de développement.
- ZArt est une interface de G'MIC initialement développée comme plateforme de démonstration pour le traitement des images provenant d'une webcam. Nous l'utilisons classiquement lors de la Fête de la Science, pour illustrer ce que peuvent réaliser des algorithmes de traitement, pour le grand public. ZArt s'est enrichi significativement, d'une part en permettant d'importer des fichiers vidéos quelconques, et d'autre part, en proposant quasiment l'ensemble des filtres du greffon G'MIC pour GIMP. Cette vidéo illustre ces nouvelles possibilités, avec par exemple la simulation de films photo argentiques sur une vidéo en temps réel. Il pourrait vraiment être très intéressant de disposer d'un greffon G'MIC pour des logiciels d'effets vidéos, comme le tout nouveau Natron par exemple. On a déjà des contacts avec eux, donc on peut espérer que ça puisse se faire dans un futur plus ou moins proche. À noter que ZArt est également passé sans douleur de Qt 4 à Qt 5.
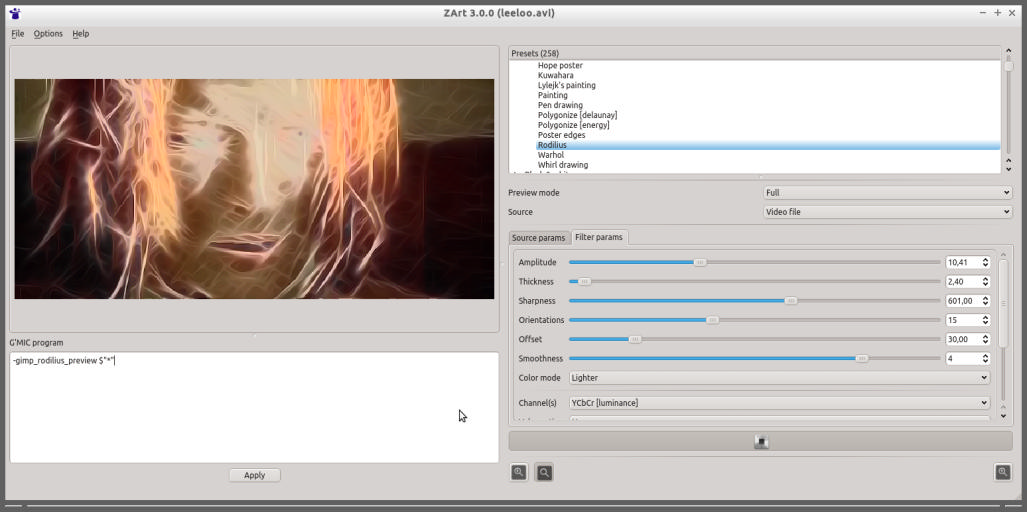{kind=link}

Fig.5.5. Aperçu du logiciel ZArt traitant une vidéo en temps réel.
- Depuis quelques temps, Lukas Tvrdy membre de l'équipe de développement du logiciel Krita a commencé à développer un greffon G'MIC pour Krita. Ce greffon est prometteur, il reprend l'ensemble des éléments du greffon déjà disponible pour GIMP, et il fonctionne déjà bien sous GNU/Linux. On travaille ensemble pour régler les quelques problèmes qui subsistent sous Windows. L'utilisation du greffon sous Krita est intéressante car il génère des résultats à 16 bits par composante, voire plus encore (flottants 32 bits), alors que le greffon pour GIMP est pour le moment limité à 8 bits par composante pour les entrées-sorties. C'est quelque chose qui pourrait changer dans le futur avec l'utilisation de GEGL, mais le manque de documentation actuel sur GEGL est un frein au support du 16 bits par composante dans le greffon G'MIC pour GIMP. Donc pour le moment, appliquer des traitements G'MIC sur des images en 16 bits par composantes ou plus nécessite l'utilisation de la ligne de commande ou du greffon Krita.

Fig.5.6. Aperçu du greffon G'MIC pour Krita en action.
(Cette image provient du site web de Krita : https://krita.org/wp-content/uploads/2014/11/gmic-preview.png)
{kind=link}
- L'intégration de certains traitements de G'MIC dans Photoflow est également en cours. PhotoFlow est un logiciel libre très récent et prometteur qui se focalise sur le développement d'images RAW en JPEG, ainsi que sur la retouche photo.

Fig.5.7. Aperçu du filtre "Dream Smoothing" de G'MIC inclus dans PhotoFlow.
(Cette image provient du site web de PhotoFlow : http://photoflowblog.blogspot.fr/2014/12/news-gmic-dream-smoothing-filter-added.html)
6. Perspectives et conclusions.
Voilà ! Le tour des nouveautés notables de ces dix derniers mois est terminé. À noter que tout ceci a été rendu possible grâce aux différents contributeurs (programmeurs, artistes, et utilisateurs en général) de plus en plus nombreux, donc merci à eux.
Dans le futur, on rêve de toujours plus d'intégration de la libgmic dans d'autres logiciels libres. Un greffon pour Natron serait idéal pour qu'on explore un peu plus les possibilités de traitement de vidéos avec G'MIC. Un greffon pour Blender serait pas mal aussi d'ailleurs ! Un noeud pour GEGL serait intéressant également, pour le prochain GIMP 3.0 (mais bon, on a encore probablement une bonne dizaine d'années pour se décider avant que ça sorte :)).
Bref, on cherche toujours des contributeurs compétents et intéressés pour explorer ces différentes pistes (et les autres qu'on ne connait pas encore), et on risque de pas s'ennuyer avec G'MIC dans les prochaines années.
Sur ce, j'y retourne, et je vous donne rendez-vous dans quelques mois pour des nouvelles fraîches du projet GMIC !
Aller plus loin
- Le projet G'MIC (708 clics)
- Le greffon G'MIC pour GIMP (443 clics)
- Documentation de 'gmic', l'outil en ligne de commande de G'MIC (103 clics)
- Simulation de films argentiques avec G'MIC (158 clics)
- Tutoriels illustrés sur l'utilisation de l'outil en ligne de commande (142 clics)
- Changelog complet pour la version 1.6.2.0 (331 clics)
# Magnifique !
Posté par Pierre Jarillon (site web personnel) . Évalué à 10.
G'MIC avec un G comme Géant ! C'est l'impression que me donne ce logiciel. Il fait partie des grands comme ffmpeg pour le traitement de la vidéo.
Associé à ImageMagick ou inclus dans Gimp et Krita, le logiciel libre offre des possibilités fabuleuses. La seule limite est maintenant l'imagination des utilisateurs.
Un grand bravo à David Tschumperlé pour son travail et les magnifiques articles qu'il publie sur Linuxfr.
[^] # Re: Magnifique !
Posté par Vroum . Évalué à 7.
Merci pour tout !
Pour ce logiciel qui sera bientôt incontournable, c'est sûr!
Pour ton enthousiasme et ta motivation dédiés au libre
Pour ce billet très bien rédigé et passionnant
Longue vie à G'MIC !
# Bravo !
Posté par KvelerKhan . Évalué à 2.
Un grand bravo pour ce logiciel qui me sera très utile :D !
[^] # Re: Bravo !
Posté par zurvan . Évalué à 5.
oui, bravo, « comme d'habitude » je serais tenté de dire, parce qu'à chaque nouvelle version de G'MIC on a de nouvelles fonctionnalités épatantes, ainsi qu'une dépêche bien détaillée.
J'utilise souvent ces excellents filtres dans gimp, le seul petit reproche que je pourrais faire à cette version, c'est qu'il n'y a pas de recherche possible dans les noms de filtres, ce qui pourrait aider à les retrouver (un peu comme pour les extensions de firefox par exemple)
"Ce n'est pas à l'état de tout savoir sur ses citoyens, mais au citoyen de tout savoir sur l'état."
[^] # Re: Bravo !
Posté par David Tschumperlé (site web personnel) . Évalué à 8.
A noter que cette fonction de recherche est disponible dans le greffon G'MIC pour Krita par contre.
Quand on confie ça à des gens qui savent mieux coder des interfaces graphiques, ça aide :)
# Deuxième essai.
Posté par Tanouky . Évalué à 3.
J'avais déjà essayé G'MIC et j'en avais été moyennement satisfait. Utile, certes, mais je l'avais oublié lors d'une nouvelle installation, pour tout dire. L'interface et quelques frustrations techniques m'avaient refroidi, voilà 2 ans et demi.
Ce journal est très bien et les fonctionnalités ont l'air très intéressantes. Le travail accompli a l'air de mériter tous les compliments et c'est avec plaisir que je vais m'y pencher, voire même y trouver quelques pistes intéressantes à conjuguer avec Blender. Merci à vous et bravo !
# color2gray et organisation du code
Posté par StreakyCobra . Évalué à 5.
Tout d'abord merci pour ce magnifique outil. J'ai déjà eu l'occasion de l'utiliser à bien des reprises, et certaines fonctionnalités telles que le patch-based inpainting lui sont uniques dans le monde du libre!
Récemment je cherchais un outil pour transformer une image couleur en niveau de gris, d'une manière à préserver le contraste. C'était pour insérer cette image dans un document à imprimer en niveau de gris, de manière à ce que les graphiques restent lisibles. En gros une implémentation de color2gray telle que présentée dans ce paper. Je n'ai pas trouvé de fonctionnalité s'y rapprochant dans GMIC, l'aurais-je loupée? Et si non est-t'il déjà prévu d'implémenter une fonctionnalité du style dans le futur?
Une question que je me pose en toute modestie et la raison l'organisation du code en 3 gigantesques fichiers? Je me la suis posée en cherchant si il y avait des occurrences de "decolorization" ou de "color2gray" (en rapport avec ma question précédente). Ne venant pas du monde du C/C++ je ne sais pas si il y a des raisons de performances ou autres à ce choix? J'y vois surtout des inconvénients, tels que la taille du repository git qui doit enregistrer un nouveau blob de 1.12M à chaque commit modifiant le fichiers gmic_def.h, ou encore la difficulté à entrer dans le code avec des fichiers de plus de 27'00 et 50'000 lignes. N'y a t'il pas moyen d'organiser la librairie dans différents dossiers/fichiers tout en les compilant en une seule entité? Ou est-ce devenu trop compliqué de le faire à ce point?
[^] # Re: color2gray et organisation du code
Posté par jihele . Évalué à -2.
git n'enregistre que des diff, pas des versions de fichier
[^] # Re: color2gray et organisation du code
Posté par StreakyCobra . Évalué à 4.
C'est l'inverse, git n'enregistre pas des diffs, il enregistre les différentes versions successives des fichiers modifiés. Pour donner cette taille de 1.2M j'ai d'ailleurs ajouté un mot dans le fichier, fait un commit, et regardé la taille du blob :-)
Git book:
La page en question est d'ailleurs une bonne ressource pour comprendre comment marche git en général!
[^] # Re: color2gray et organisation du code
Posté par jihele . Évalué à 2.
Merde alors, j'en étais convaincu. Merci pour le lien, c'est clair.
[^] # Re: color2gray et organisation du code
Posté par Matthieu Moy (site web personnel) . Évalué à 3.
Ca, c'est vrai jusqu'au jour où tu fais un git gc (ou bien que Git décide tout seul de faire un gc --auto). Les packs sont delta compressées comme les autres SCM (même si conceptuellement ça reste un snapshot).
[^] # Re: color2gray et organisation du code
Posté par StreakyCobra . Évalué à 3.
Merci pour l'info, je n'avais pas été jusque là dans le fonctionnement de git. Par contre ce repository me surprend quand même un peu:
Linux fait ~600M (1.7G - 1.1G), gmic fait ~130M (659M - 528M), linux a un repository de 1.1G pour 515454 commits, GMIC a un repository qui fait la moitié (528M) pour seulement 1518 commits. La différence me semble énorme non? Est-ce que cela viendrait quand-même la taille des fichiers?
[^] # Re: color2gray et organisation du code
Posté par David Tschumperlé (site web personnel) . Évalué à 5. Dernière modification le 24 avril 2015 à 09:58.
J'ai résolu le problème du git, effectivement ça prenait un peu trop de place.
Les sources seules (sans les fichiers resources, binaires, qui prenaient bcp de place) sont disponibles sur un repo 'minimal' :
qui fait 4Mo en tout et pour tout.
[^] # Re: color2gray et organisation du code
Posté par StreakyCobra . Évalué à 6.
Effectivement, 11 secondes pour cloner
gmic-fullà la place des 20 minutes précédemment. Toute cette discussion aura au moins été utile sur un point ;-) C'est top merci![^] # Re: color2gray et organisation du code
Posté par robin . Évalué à 2.
<disclaimer>
Je ne suis pas allé regarder comment tu as organisé le repo gmic-minimal, et je n'ai jamais utilisé en pratique les submodules. Corrigez-moi si je me trompe.
</disclaimer>
Tu peux avoir un sous-repo gmic-asset géré avec git submodule. Comme ça, tu as tout les assets dans gmic-asset, et tout le reste du code dans gmic-minimal. Ça te permet de garder les dépendances entre le code et les assets (par exemple le comit 87af23 de gmic-minimal utilise les assets du commit 213e34), et donc de pouvoir continuer à utiliser l'historique.
bépo powered
[^] # Re: color2gray et organisation du code
Posté par David Tschumperlé (site web personnel) . Évalué à 10. Dernière modification le 17 avril 2015 à 11:58.
Je ne connaissais pas l'algorithme color2gray, donc je ne l'ai pas implémenté, mais ça ne me semble pas trop compliqué. Eventuellement, j'y jeterai un oeil, d'autant qu'ils proposent un pseudo-code Matlab sur leur page qui peut être éventuellement converti en nouvelle commande G'MIC. D'après les résultats que je vois, on peut avoir un type de résultats un peu équivalent en appliquant un algorithme de contraste local après le calcul de la luminance. Donc en G'MIC, tu peux essayer ceci (en ligne de commande) :
Ce n'est pas exactement pareil que color2gray (ça ne marchera pas sur les cas pathologiques présentés dans le papier, comme l'image du 45 pour les daltoniens par exemple), mais pour rehausser le contraste pour les images à mettre dans une publi, c'est pas mal.
En ce qui concerne l'organisation du code, c'est une question réccurente je peux te l'assurer :) Donc j'ai quand même bien réfléchi à la question. Pour ma part, je n'y vois que des avantages (sinon, je pense que j'aurais quand même pensé à le changer depuis le temps), notamment la facilité de maintenance du projet (dans ce contexte précis, où je suis quasiment seul développeur dessus). Toutes les fonctionnalités sont regroupées thématiquement au même endroit (1 fichier pour l'interpréteur, 1 fichier pour les algos de traitement, 1 fichier pour la définition des commandes et des filtres), et j'utilise facilement la recherche de texte sous emacs pour me déplacer à l'intérieur d'un gros fichier. Donc, au contraire, ça serait très pénible pour moi d'avoir 50 fichiers différents. Le fichier gmic_def.h est généré automatiquement, donc à la limite, ne pas le mettre dans le dépôt git serait une meilleure idée. Pour la bibliothèque CImg sous-jacente, la décomposer en plusieurs fichiers n'aurait à priori aucun intérêt "technique", autre que faire plaisir aux gens qui aiment avoir pleins de fichiers :). Ca peut être un peu long à expliquer, et j'ai déjà discuté de ça avec pas mal de personnes en essayant de donner des arguments étayés allant dans ce sens. Mais bon avec le temps, ce que j'ai aussi remarqué, c'est qu'en matière de code, chacun a souvent un avis bien tranché sur la question, et pense toujours connaître les "bonnes pratiques", même en ignorant totalement le contexte du projet et la structure du code. Comme l'auteur d'un logiciel est à priori le mieux renseigné sur la structure de son code, il me semble qu'il faut venir avec des arguments plus que solides pour le convaincre de changer. Je n'ai personnellement rien contre le changement (en tant que chargé de recherche, ça serait un comble), mais personne n'a encore réussi à me convaincre sur ce point là.
Le code de G'MIC est assez court (moins de 100kloc), en regard de ses fonctionnalités, donc refactoriser ce code ne serait pas forcément très long, ni très fastidieux. C'est juste que je ne vois pas de raisons valables de le faire pour ma part, et même pire, je pense que ça deviendrait plus long et plus difficile à maintenir. Si quelqu'un veut se lancer pour prouver le contraire, je l'encourage vivement bien entendu.
[^] # Re: color2gray et organisation du code
Posté par rewind (Mastodon) . Évalué à 2.
Il y a même des gens qui font plusieurs fichiers et qui compilent tout en une seule fois, en incluant tous les .cc/.cpp dans un seul fichier ! http://en.wikipedia.org/wiki/Single_Compilation_Unit
Les avantages de ce type de compilation sont les mêmes que pour un seul fichier et se défendent assez facilement dans certains cas (et je pense que G'MIC/CImg fait partie de ces cas).
[^] # Re: color2gray et organisation du code
Posté par StreakyCobra . Évalué à 7.
Merci pour la commande. Juste pour le fun j'ai essayé avec une des images en exemple dans le paper, une qui correspond aux diagrammes que j'ai à imprimer de temps en temps.
Malheureusement les couleurs sont dures à différencier en comparaison de ce que l'algorithme en question dit offrir:
Toutefois merci pour l'aide, et si un jour cet algorithme est porté dans GMIC je me réjouirai de l'utiliser!
Oui j'ai bien imaginé que la question avait déjà du être posée ;-) Il y a effectivement autant de façons de voir les choses que de développeurs. En étant le développeur principal, c'est sûrement ce qui te conviens le mieux et qui te permet de travailler le plus vite, et c'est très bien ainsi.
Je disais ça plutôt d'un point de vue d'un personne externe, telle que le verrai un éventuel développeur intéressé à contribuer. Voilà quelques réflexions en vrac (en pensant bien que je ne connais pas du tout le code), à utiliser si cela peut-être utile:
ctrl+cau milieu.srcaprès cela, on se retrouve avec 4 énormes fichiers contenant entre 10'000 et 50'000 lignes. Ça ne donne pas beaucoup envie d'entrer dans le code.io/avec tous les code gérant la lecture/écriture des images. Cela permettrait de savoir que si on veut ajouter du support pour un nouveau type d'image, c'est là-dedans que cela se passe. En entrant dans ce dossier, il y aurait le support d'un format d'image par fichier. Du coup le développeur n'aurait qu'à copier/coller un de ces fichiers et peut directement commencer à l'adapter au nouveau format de fichier. À l'inverse avec 4 gros fichiers, on ne sait pas ou chercher, comment s'appellent les méthodes, quelles méthodes doivent être fournies pour gérer un nouveau format d'image, etc. Par exemple dans un projet qui a une structure comme ceci:On peut tout de suite voir quelle partie est dédiée à l'affichage, ou se trouve la configuration, quelles sont les différentes commandes, quel est le point d'entrée du programme, etc. Si a la place il y avait 2 ou 3 gros fichiers cela aurait été beaucoup plus difficile à comprendre qu'est ce qui se passe et où.
Pour résumer: le découpage du code ralenti un peu les gens qui connaissent le code, mais permet aux gens qui ne le connaissent pas d'y entrer plus facilement. Au final c'est le choix du développeur principal que de préférer la rapidité de développement ou l'accessibilité du code.
CImg.hpour un commit rajoute actuellement 472K au repository. Le découpage en plusieurs fichiers réduirait ce problème, qui est d'ailleurs la cause de la lenteur pour cloner le projet.Voilà mes 2 centimes, en espérant que cela puisse être utile. Mais je tiens à noter que malgré ces quelques remarques, je suis impressionné par le rythme de développement de GMIC, comme quoi tout ça n'est pas si important!
[^] # Re: color2gray et organisation du code
Posté par David Tschumperlé (site web personnel) . Évalué à 7. Dernière modification le 17 avril 2015 à 15:11.
Pour le genre d'images (synthétiques) que tu utilises, tu peux en général facilement trouver une façon de calculer le passage couleur -> scalaire avec une fonction plus adaptée à la visualisation que tu recherches. Sur l'image que tu donnes par exemple, au lieu de prendre la luminance, tu prends la Value de l'espace HSV (correspondant au max des valeurs sur RGB), et ça donne quelque chose qui m'a l'air correct, peut-être même plus naturel que ce que propose l'algo color2gray :
Pour le code, encore une fois tout est question de personnalité de celui qui relit. J'ai moi-même lu pas mal de codes d'autres projets (des bibliothèques de traitement d'image principalement), et je préfère toujours aborder un projet avec peu de fichiers, à priori, je me dis que ça va être plus simple de s'y retrouver et je vais moins devoir chercher dans pleins de fichiers. Si je cherche une fonctionnalité précise, de toute façon, j'ai au moins un mot-clé que je peux utiliser pour chercher dans le fichier (au mieux, le nom de l'algorithme qui va apparaitre dans les commentaires associé au code, ou au pire, un nom de fonction d'une dépendence qui va être forcément utilisé à l'endroit où je cherche, genre appel X11).
Et dans un monde idéal, tes dizaines / centaines de fichiers devraient tous avoir un nom cohérent et une localisation cohérente, mais en vrai, comme tous les projets évoluent en dehors de l'imagination initiale de l'auteur, ça peut souvent finir rangé n'importe comment. Dire que beaucoup de fichiers facilite la lecture du code est pas quelque chose de généralisable (en tout cas, pour moi ça marche pas, je dois pas être le seul). Il m'est arrivé assez souvent de revenir à un bon vieux
grep -Rpour chercher une fonctionnalité précise dans des projets avec des foultitudes de fichiers. J'aurais honnêtement préféré faire un CTRL+S sous Emacs dans un seul gros fichier :)[^] # Re: color2gray et organisation du code
Posté par StreakyCobra . Évalué à 2.
Oui en traitant image par image je sais qu'il y a moyen d'améliorer la décoloration. Simplement je souhaitais automatiser cela pour mes documents en latex afin de proposer une version en niveau de gris optimisée pour l'impression. Je souhaitais en faire l'outil le plus généraliste possible afin qu'il marche avec tout type d'image. Cette conversion là marche bien sur certaines images, mais en supposant que j'aie d'autres couleurs, comme dans l'image suivante, il faut de nouveau changer de méthode.
C'est pourquoi je cherche une méthode telle que
color2grayqui semble répondre à ce cas d'utilisation de manière générale.Effectivement nous n'avons pas la même méthode de travail. En fait je n'ai aucun intérêt à voir la méthode de travail changer, vu que 1) mon niveau de C/C++ ne me permet pas de contribuer, et que 2) le projet fonctionne bien comme ça. Il faut plutôt voir mes remarques comme un retour utilisateur sur l'expérience que peut avoir une personne externe qui souhaite s'intéresser au projet. Si cela peut apporter quelque chose au projet tant mieux, sinon il n'y a qu'à les ignorer!
[^] # Re: color2gray et organisation du code
Posté par David Tschumperlé (site web personnel) . Évalué à 8.
Ok pour ta problématique. A mon avis, un truc qui pourrait marcher pas mal serait simplement de faire une fonction qui génére plusieurs images noir et blanc à partir d'une image couleur, en choisissant différentes formules 'classiques' de conversion (luminance, lightness, value, average,…) et de sélectionner parmi celles-ci celle qui maximise un critère de variance des gradients de valeurs obtenues par exemple.
C'est une idée amusante qui risque de bien marcher, je vais probablement essayer ça un de ces quatres.
[^] # Re: color2gray et organisation du code
Posté par alex666 . Évalué à -1.
"de sélectionner parmi celles-ci celle qui maximise un critère de variance des gradients de valeurs obtenues par exemple"
Ça existe déjà dans ufraw par exemple, non?
Quant à sélectionner une image qui maximise, je fais plutôt confiance à mon oeil!
Toutes ces variantes de transfo d'images vers du NB sont très profondément différentes du "color2gray" de Gimp, qui en effet mériterait d'être amélioré!
[^] # Re: color2gray et organisation du code
Posté par Anthony Jaguenaud . Évalué à 5.
Pour l’organisation du code, le seul argument que je donnerai, c’est la simplicité de merge lors de la collaboration avec plusieurs personnes. En effet, si plusieurs développeurs travaillent sur des parties différentes, il y a de grandes chances qu’ils ne touchent pas les mêmes fichiers, donc, que le merge soit trivial. Pour un gros fichier, ça peut être plus problématique.
Je vois un autre avantage, ça oblige a structurer le code… je n’ai pas vu le code, je n’ai donc aucun commentaire dessus, je parle en général. Un seul gros fichiers, tu ajoutes juste une fonction, avec pleins de fichiers, il faut réfléchir dans quel composant le mettre. En cas d’erreur, il faut déplacer le code d’un fichier à l’autre, ce qui n’est pas le cas pour G'mic.
[^] # Re: color2gray et organisation du code
Posté par David Tschumperlé (site web personnel) . Évalué à 6.
On pourrait dire aussi que si plusieurs personnes travaillent un même gros fichier, la probabilité qu'ils touchent à la même portion de code est plus réduite, donc à priori ça ne posera pas de problème pour le merge non plus (pas de conflits). Quand on y pense, le fait que des données de code source soit dans un même fichier ou séparés en plusieurs fichiers est finalement assez anecdotique, c'est un point purement technique qui ne change rien au fait qu'un code soit bien structuré ou non. Enfin c'est mon avis.
[^] # Re: color2gray et organisation du code
Posté par barmic . Évalué à 10.
Désolé je vais faire mon chieur, mais promis je ne le fais qu'une seule fois.
Non ça n'a rien d'anecdotique.
Déjà pour ton argument. Si 2 développeurs touchent un même fichiers ils touchent les même lignes c'est un fait, tu as des parties communes (les includes, les créations de macro,…). Mais même sans ça l'historique est bien plus compliqué à suivre.
Le plus grave, c'est le risque important d'effets de bord que tu peux avoir, il faut être très précautionneux sur l'utilisation des namespaces pour pouvoir s'en sortir et quand tu commence à faire du code qui marche que quand tu as de très bons développeurs c'est que ton code va être cassé à un moment ou à un autre (j'ai des tas d'exemple d’excellents développeurs qui ont fait des erreurs - qui sont parties en prod - incroyables).
D'un point de vu du travail, c'est bien plus compliqué de segmenter sa réflexion avec un
grosénorme document, on est parasité par tout le reste, quand on découvre, on a tendance à craindre les effets de bord qu'on va créer donc on va se perdre à essayer de comprendre des parties inutiles…Pour ce qui est de ton repérage dans emacs : tu es obligé d'utilisé une manière de te repérer en une seule dimension (les lignes de ton fichier) alors que tu pourrais avoir un repérage en 2 dimensions (les numéros de lignes et les noms de fichiers). Tu ne peux pas te dire que les lignes autour de 3000 s'occupe de tel algo, parce que le refacto des lignes entre 1000 et 1200 ont complètement déplacé tes lignes.
Au niveau test c'est aussi vachement moins sympa d'avoir un énorme fichier.
Sincèrement ça marche probablement très bien parce que tu as pris l'habitude, mais je ne doute pas que c'est un frein énorme à la contribution extérieur et le fait que la question soit revienne régulièrement sur le tapis me semble être un indicateur de cet état de fait (tu as des gens qui se sont suffisamment intéressé à ton travail pour plongé dans ton code, mais ils ont rencontré des difficultés).
Je vais le dire autrement, il me semble que G'Mic est un super terrain de jeu pour les algorithme en tout genre sur le traitement d'image (c'est ce qui ressort des tes journaux, dépêches et commentaires), ce serait AMHA génial d'avoir quelque chose de suffisamment modulaire pour qu'ajouter un algo consiste à créer un fichier qui va bien puis à ajouter ce fichier dans la liste des autres fichiers. Ça permettrait :
#ifdefSincèrement si les gens découpes leur fichier, ce n'est pas une question de mode, de tique bizarre, ça n'est pas arrivé avec la dernière techno que tu n'aime pas, c'est pas lié à un buzzword qui n'aurait pas de sens, etc
Tiens au fait, ça ne te donne pas des temps de compilation à crever de vieillesse devant son écran de redevoir compiler le tiers de ton logiciel à chaque modification ? Même quand tu expérimente ton algo ?
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: color2gray et organisation du code
Posté par nigaiden . Évalué à 3.
Je n'ai pas vu le code, donc je me sens apte à répondre.
Effectivement, les outils du système fonctionnent mieux avec des petits fichiers.
Par contre, l'organisation du code en fichiers relève davantage du style de codage que de la structuration du code. Si le code ressemble à :
que les classes se retrouvent chacune dans leur fichier ou toutes dans le même ne change pas grand chose. Pour l'auteur, ce qui fait une différence c'est que si on veut naviguer dans le code en retrouvant un filtre d'après sa description, dans un cas il suffit de faire une recherche de texte, dans l'autre cas il faut "sortir" de l'éditeur de texte pour lancer une commande externe. C'est juste une histoire de préférence personnelle que d'accepter les avantages et inconvénients d'une organisation plutôt que de l'autre - pour la logique du code j'entends, pour moi la meilleure cohabitation avec le système justifie quand même l'éclatement en fichiers.
[^] # Re: color2gray et organisation du code
Posté par David Tschumperlé (site web personnel) . Évalué à 9.
Voilà, ton commentaire est intéressant, parce qu'il illustre parfaitement ce que je disais précédemment, à savoir que tu donnes un avis assez tranché, mais "général", sur la façon de structurer un code (avis d'ailleurs que je peux partager pour du code "classique"), alors même que tu ne connais pas suffisamment les spécificités techniques des projets G'MIC (et CImg surtout) pour comprendre pourquoi j'ai fait comme ça (et c'est parfaitement normal également). Et dans le cas du projet G'MIC en particulier, il s'avère que cette structuration classique ne serait pas forcément la meilleure. Note qu'elle ne serait pas tellement plus mauvaise non plus, mais qu'à mon avis, elle propose légèrement moins d'avantages (et mon point de vue a quand même un poid important sur le résultat final). Ca se joue pas à grand chose, mais c'est comme ça. Et comme ça se joue quand même vraiment sur des détails (purement techniques en plus), ça m'étonne toujours que ça fasse tant parler. Surtout que la plupart des gens qui émettent un avis n'en savent probablement pas suffisamment pour que leur avis soit constructif.
Mais de fait, je maintiens qu'avoir plusieurs fichiers plutôt qu'un seul est un point purement technique, au fond assez anecdotique. La quantité de donnée stockée est quasiment la même dans les deux cas (avec même moins de redondance dans le cas d'un gros fichier). Le point qui te dérange sans doute, c'est de te dire que le compilateur est plus efficace à compiler plusieurs fichiers qu'un seul gros. Et que séparer en plusieurs fichiers, c'est l'assurance de ne pas recompiler des bouts de code déjà compilés.
Tu as raison "en général", mais d'une part, je dirais que ça pourrait presque être vu comme une limitation du compilo. On peut très bien imaginer dans le futur qu'un compilateur puisse déterminer quelles parties d'un gros fichier il doit recompiler, sans recompiler le reste du fichier. Mais bon, Ok c'est pas encore le cas. Par contre, ceci est vrai en général, sauf quand on utilise des bibliothèques de fonctions templates où le type des paramètres template est inconnu à la compilation. Est c'est exactement le cas de CImg, la bibliothèque d'opérateurs de traitement d'images que j'utilise (et que je distribue à part). Ici de toute façon, le compilo va devoir "tout" recompiler (en fait, non pas tout, il est assez malin pour recompiler juste les méthodes utilisées dans le code, avantage No 1 : tu auras pas dans ton code final des blobs binaires de code que tu n'utilises pas) pour les types template instanciés dans par l'utilisateur. C'est du template, c'est le principe.
Dans le cas de G'MIC, le gros du travail de compilation, c'est de compiler les méthodes de CImg qui sont utilisées, donc une fois que ça c'est fait, quasiment tout est fait. Après, dire que CImg est pas modulaire, c'est archi-faux, tout est bien structuré, dans des beaux namespaces, des belles classes, c'est juste que tout ça est défini dans un seul fichier. Pourquoi par plusieurs ? Parce que comme toutes ces belles classes dépendent fortement les une des autres, il faudrait de toute façon inclure tous ces beaux fichiers séparés en même temps, donc d'un point de vue performance de compilation, ça reviendrait exactement au même. A noter que de toute façon, la phase de parsing des fichiers par le compilo dans le temps global de compilation est réellement négligeable par rapport au reste (phase d'optimisation en particulier) donc que le fichier soit gros ou pas, le compilo s'en tape un peu.
Revenons en au temps de compilation. Hé bien non, ça prend pas longtemps, désolé (avec un compilo décent). Peut-être un peu plus longtemps que si j'avais utilisé des fonctions non-template (mais j'aurais perdu en généricité, ce qui serait perdre beaucoup pour gagner peu), mais ça reste très acceptable pour développeur. Actuellement, sans les optimisations, G'MIC complet, avec toutes les dépendances se compile en 1 minute (sur mon portable, avec g++ 4.8). C'est long 1 minute pour un projet comme G'MIC ? Non, carrément pas !
(avec clang++ c'est kif-kif). Alors OK, avec les optims c'est plus long, mais ça c'est quelque chose qu'on fait seulement de temps en temps, pas pour le développement de tous les jours (et au boulot, pareil ça prend 15mn avec make -j… oulala j'ai à peine le temps d'aller prendre un chocolat chaud à la machine avant que ma release soit prête. Pourquoi penses-tu que je peux proposer des pre-releases quasiment journalières sans que ça soit une torture ?).
Après, tu sous-entends que ça favorise pas les contributions extérieures. Mais c'est là encore archi-faux ! Des contributions j'en recois raisonablement, autant pour CImg que pour G'MIC. Et quelle facilité pour maintenir le code ! Une contribution sur un tel code, ça sera forçément très local dans un fichier, ça sera pas du code nouveaux disséminé dans 4 ou 5 fichiers différents, et bien ça c'est très appréciable pour la relecture des patchs, et la mise en adéquation au style de codage du projet. Je conseille à tout le monde d'essayer au moins une fois dans sa vie de maintenir un projet avec 3-4 fichiers maxi. Vous allez voir comme c'est simple !
Découper un projet en pleins de fichiers, c'est pas juste une question de mode ou pas de mode. Il faut le faire quand c'est nécessaire, mais il faut surtout ne pas se forcer à le faire quand ça sert à rien. Dans le cas de G'MIC / CImg, ça sert à rien. Que quelqu'un me prouve le contraire (mais pas juste avec des arguments bateaux), comme je le dis je suis pas fermé. Mais depuis 1999 (année ou j'ai commencé CImg), jamais personne ne m'a convaincu. Je commence quand même à me dire que c'est parce que j'ai choisi une façon de faire qui se défend carrément.
[^] # Re: color2gray et organisation du code
Posté par Nicolas Boulay (site web personnel) . Évalué à 8.
Que le code de gestion des fenêtres Windows, ou les tables des fonts se retrouvent dans le même fichiers que les algos d'image, cela fait bizarre.
J'ai l'impression que la vrai limite c'est Emacs qui ne gère pas la recherche simple entre plusieurs fichiers.
"La première sécurité est la liberté"
[^] # Re: color2gray et organisation du code
Posté par whity . Évalué à 3.
Je plussoie totalement ce commentaire, ainsi que celui de Michel.
Sérieusement, l’impression donnée, c’est que « avec les outils que j’utilise, c’est plus simple avec un seul (très peu de) fichier » ce qui fait sérieusement douter de l’efficacité de l’outil utilisé (parce que bon, rechercher parmi tous les fichiers du projet, c’est quand même une fonction de base de n’importe quel ide…).
Découper en plusieurs fichiers, ce n’est pas que cosmétique. Le découpage en fichier correspond aussi en général au découpage fonctionnel. Et cela permet d’avoir plein de métriques intéressantes sur la taille des fichiers : un fichier cpp qui commence à faire plus de 1000 lignes, c’est probablement une classe qui a trop de responsabilités, et donc un découpage fonctionnel à affiner. Chose qui est beaucoup plus complexe à faire avec le « tout dans un fichier ». L’argument de l’usage de template n’en est pas un : cf boost pour un contre exemple.
Après, reste l’argument du « je suis le mainteneur du projet, et c’est comme ça que je trouve que c’est le plus simple et le plus adapté à mon cas d’utilisation ». Et là, il n’y a rien à redire.
Mes commentaires sont en wtfpl. Une licence sur les commentaires, sérieux ? o_0
[^] # Re: color2gray et organisation du code
Posté par Nicolas Boulay (site web personnel) . Évalué à 2.
En même temps, il y a plein de trucs sous emacs qui manque sous d'autre IDE (selection carré, killing ring, recherche à la volé (qui existe maintenant sous firefox), autocomplétion (mais moins bien que eclipse)…)
"Après, reste l’argument du « je suis le mainteneur du projet, et c’est comme ça que je trouve que c’est le plus simple et le plus adapté à mon cas d’utilisation ». Et là, il n’y a rien à redire."
La discussion a lieu à chaque release. Donc, je n’insiste pas plus que ça.
"La première sécurité est la liberté"
[^] # Re: color2gray et organisation du code
Posté par pepp . Évalué à 4.
Ça n'implique pas qu'un découpage fonctionnel nécessite un découpage en fichiers.
Comment ça marche si tu as 2 classes dans le même fichier ? ou 10 ?
Bref, chercher à appliquer les mêmes règles à tous les projets me parait absurde au plus haut point. Si l'auteur préfére 1 fichier, tant mieux pour lui.
Accessoirement, avoir 1 seul fichier a un énorme avantage : ça rend l'intégration dans d'autres projets triviale.
[^] # Re: color2gray et organisation du code
Posté par David Tschumperlé (site web personnel) . Évalué à 9. Dernière modification le 23 avril 2015 à 08:43.
Tu as mal compris mon commentaire.
Ce n'est pas une question de mauvais outils, ni de "j'ai pas le temps ou c'est trop tard", ni d'incompétence en programmation. C'est juste que c'est de mon point de vue la meilleure façon de faire. Si toi, tu penses que ce n'est pas la bonne façon de faire, aucun problème, c'est ton droit.
Il faut croire qu'on est pas d'accord. Donc maintenant, de deux choses l'une :
Si tu veux me convaincre que ce n'est pas la bonne façon de faire, aucun problème, ça m'intéresse même.
Par contre, j'attend un peu plus, il faut prouver ce que tu dis de manière un peu rigoureuse et scientifique. Balancer des grosses généralités sur la "bonne" façon de programmer, ça n'avance à rien. Dire que les template n'empêchent pas d'avoir plusieurs fichiers parce que Boost ou la STL ont plusieurs fichiers c'est une évidence. J'ai jamais dis le contraire. Dire qu'une classe avec +1000 lignes c'est absurde, ça commence à ressembler à un gros troll velu. Le mieux serait encore que tu proposes une alternative plus belle et plus fonctionnelle à partir des sources que je fournis gracieusement. Y a pas beaucoup de fichiers C++, donc ça ne devrait pas être un travail énorme :)
Si au contraire, tu ne cherches pas à me convaincre, essaye au moins de respecter mes choix, peut-être même tenter de les comprendre, sans me faire passer pour un neuneu de la programmation (bref, soit un peu ouvert). Je suis loin d'être aussi fermé que ton commentaire le sous-entend, et je n'accepte pas qu'on descende ce projet sous des prétextes fallacieux et des mauvaises interprétations de ta part.
Je ne vais pas changer la structure complète du code, parce que deux ou trois personnes sur Linuxfr m'ont fait remarqué que c'était mal fait. Je suis prêt à écouter tout bon conseil et toute bonne suggestion, mais à un moment donné, il faut prouver ce qu'on dit, et arrêter le déballage d'opinions sans arguments étayés. J'essaye de construire un projet libre qui marche le plus efficacement possible (tu doutes de l'efficacité de l'outil, mais l'as-tu au moins essayé?). Efficacité, à la fois dans l'exécution en elle-même, la généricité du code, la facilité de maintenance, etc.. Et pour le moment, je ne me plains pas de l'efficacité. Je me plains pas de grand chose en l'occurence, j'essaye juste d'avancer.
Prouve moi que tu peux rendre ce projet encore plus efficace et je te suivrais dans tes choix avec plaisir.
Mais sans occulter non plus tous les avantages que procurent la structure actuelle!
(Ce message est aussi valable pour N. Boulay, qui depuis quelques années, à chaque news Linuxfr sur G'MIC en profite sur donner son avis sur la bonne façon de programmer. Depuis le temps, il aurait donc eu le temps de contribuer d'une manière ou d'un autre au projet pour nous remettre dans le "droit chemin", mais on a jamais eu de nouvelles, on attend toujours).
[^] # Re: color2gray et organisation du code
Posté par Nicolas Boulay (site web personnel) . Évalué à 3.
Cela fait longtemps que je n'essayes plus de te convaincre. C'est ton projet, tu fais ce que tu veux. J'avais juste trouver génial la façon d'utiliser la lib pour faire du traitement d'image, et parfaitement horrible le code de la lib. D'ailleurs, je t'avais filé un mini patch qui a augmenté les perfs de 5 à 10% si je me rappelle bien.
Par exemple, la structure mémoire de l'image n'était pas un objet à part des traitements, il était ainsi impossible de changer le layout mémoire sans devoir réécrire tous les traitements. Je voulais tenter une organisation en "tile", voir rendre possible l’auto-vectorisation. Mais cela a été impossible à faire.
"La première sécurité est la liberté"
[^] # Re: color2gray et organisation du code
Posté par David Tschumperlé (site web personnel) . Évalué à 5.
En l'occurence, c'est pas du tout l'état d'esprit dans lequel je développe. Je suis prêt à beaucoup me remettre en cause pour améliorer un projet, et je l'ai déjà fait souvent d'ailleurs depuis le début dans G'MIC et CImg. J'accepte bien sûr des patchs quand ils apportent quelque chose de valable.
Quand quelqu'un me soumets un patch, il me détaille : 1. Quel est le problème, 2. Comment résoudre le problème. C'est cartésien, c'est sain. Peut-être que j'attends un peu plus (trop?) de ça aussi dans les commentaires d'une dépêche Linuxfr ? Ceux qui donnent un avis juste pour donner un avis, ça fait avancer personne, surtout quand le ton est désagréable et/ou pédant.
[^] # Re: color2gray et organisation du code
Posté par Nicolas Boulay (site web personnel) . Évalué à 8.
Dans un projet libre, le plus important est le courage et l’obstination du mainteneur, il n'y a que ça pour maintenir le projet en vie. On le voit bien avec le mainteneur de GPG par exemple. A coté de ça, la structure téchnique d'un projet est secondaire.
Concernant les patchs, changer de structure de base nécessitait de tout reprendre, on ne commence pas une contribution en cassant tout. Je suis passé à autre chose. Et concernant les critiques, tu n'en as pas eu le dixième de ce que l'on a pu prendre sur le tête pour Lisaac. Le mainteneur en a eu marre et a coupé tout contact, et le projet est mort.
Ton projet est très utile, tu arrives à secouer Gimp, qui le méritait bien, et maintenant tu va au-delà. C'est bien plus important que les querelles techniques.
"La première sécurité est la liberté"
[^] # Re: color2gray et organisation du code
Posté par xcomcmdr . Évalué à -3.
Un code de 10 000 lignes, qu'il soit bien écrit ou pas, dans un seul et même fiohier, j'y touche même pas. L'effort à fournir est trop grand pour ne serait-ce démêler le bordel.
9 fois sur 10 autant de lignes dans un seul fichier ça dénote un code mal fichu et à reprendre à zéro. Je veux bien croire qu'il y ait des exceptions, mais j'en ai pas encore vu.
"Quand certains râlent contre systemd, d'autres s'attaquent aux vrais problèmes." (merci Sinma !)
[^] # Re: color2gray et organisation du code
Posté par whity . Évalué à 4.
Pourtant, pour justifier le choix d’un seul fichier, tu utilises des arguments comme « ça m’évite de lancer un grep ». À minima, évite cet argument car c’est forcément le genre de réponses qu’il amène.
Je te renvoie au message de Michel. Honnêtement, il a exprimé mon point de vue mieux que je ne le ferais probablement. Comme tu n’es pas d’accord avec ses arguments, je crois qu’on ne sera effectivement jamais d’accord.
Désolé si tu as mal pris la fin de mon commentaire (le fait que « c’est ton choix, il n’y a rien a redire »). En fait, c’est vraiment ce que je pense : c’est ton boulot, tu le fais bien comme tu veux, et tant mieux si tu y trouves ton compte.
Par contre, quand on dit « ça te coupe de contributeurs potentiels », oui, je pense sérieusement que c’est le cas. J’ai parcouru rapidement le source de CImg, c’est typiquement le genre de code dans lequel je n’ai pas spécialement envie de mettre les mains (bon, après, le fait que le traitement d’image ne soit pas du tout mon domaine n’aide pas non plus). Sans parler des commentaires de commit vides. Après, la réponse à cette interrogation se trouve vraisemblablement en grande partie dans le nombre de contributeurs externes à CImg.
Je crois que si cette architecture de code te convient, c’est que tu n’es pas un être humain normal (et vu les résultats extraordinaires que tu produis, ça me conforte dans cette idée :) ).
Mes commentaires sont en wtfpl. Une licence sur les commentaires, sérieux ? o_0
[^] # Re: color2gray et organisation du code
Posté par David Tschumperlé (site web personnel) . Évalué à 2.
Ce n'est pas un argument que j'ai utilisé pour justifier ce choix. C'est un argument que j'ai utilisé pour contredire Michel: S'y retrouver dans le code d'un gros fichier n'est pas plus difficile que dans pleins de petits, puisqu'au final on peut fait une recherche plutôt qu'un grep. Donc, l'argument "pleins de petits fichiers c'est mieux pour s'y retrouver dans l'organisation d'un code" avancé par Michel, est faux. Au final, ça revient au même. Voilà ce que j'ai dit.
Ca, je dirais, c'est ton problème. Est-ce que je me suis plaint de pas avoir assez de contributeurs ? Jamais. Faut croire que pas mal de gens sont pas apeurés par la première originalité venue (ou ont assez d'expérience pour se rendre compte que ça n'a aucune incidence sur la qualité du code). Franchement, lire des commentaires du niveau de celui de xcomcmdr (plus haut), c'est à pleurer. A croire qu'il n'a jamais rencontré autre chose qu'un "Hello World" de toute sa vie.
Je suis tout à fait normal, et en tant qu'être humain normal, j'essaye de me contrôler et pas crier au loup dès que je vois quelque chose d'un peu différent de ce que j'ai l'habitude de faire par moi-même. Surtout si ça touche un point de vue seulement "technique". J'essaye d'abord de comprendre avant de me faire une opinion. Et ça prend tu temps, oui, mais c'est nécessaire. L'empathie est ce qui nous différencie de pas mal d'animaux (dont certaines moules apparemment).
Je n'interviendrais plus sur ce sujet stérile, mais j'attends bien sûr avec impatience toutes vos contributions pour améliorer le projet G'MIC (la soumission de patchs se fait ici).
[^] # Re: color2gray et organisation du code
Posté par xcomcmdr . Évalué à 3. Dernière modification le 23 avril 2015 à 16:43.
Excuse moi, mais j'ai vu suffisamment de code pour voir de suite que ça pue potentiellement.
Encore une fois, s'il y a des exceptions, je veux bien y croire, mais j'en ai pas vu. Et j'ai vu pourtant beaucoup de code.
Et qu'il y ait une exception ou non je dirais que je m'en fiche un peu. Humainement, modifier un fichier de plus de 10 000 lignes ce n'est pas pour moi. Déjà à 3000 lignes je sature vraiment la molette pour changer au final 1% du bordel, alors 10 000… Ouais, il y a grep, à condition de connaître le code et d'être sûr de ne pas se tromper. Dur. Je préfère structurer en petites unités logiques (que ce soit au niveau fichier ou classe), c'est beaucoup plus gérable, et ça m'empêche moins de me concentrer. Et en prime, je risque beaucoup moins de me retrouver avec un objet omniscient qui fait tout, même le café (respecter SOLID, c'est pas que pour la beauté du geste).
Tu peux gérer un fichier de plusieurs milliers de lignes, tant mieux pour toi. Chez moi, c'est un code smell qui s'est toujours vérifié et une source de perte de temps (scrolling/grep) et de déconcentration (lire des milliers de lignes qui n'ont rien à voir, même en passant, avant de trouver ce que je recherche : non merci).
"Quand certains râlent contre systemd, d'autres s'attaquent aux vrais problèmes." (merci Sinma !)
# Passionnant. Pas la doc du site :/
Posté par dzecniv . Évalué à 3.
Cet article est passionnant. Mais j'ai vraiment du mal à me retrouver sur le site officiel.
# Gmic, encore un effort!!
Posté par alex666 . Évalué à 4.
Pas très versé dans les algo, je n'utilise que le greffon Gimp pour la retouche de photos (et non de selfie, lolcat & Co…).
Génial !!!
Mais à condition de s'y retrouver !!
- tout est in american in the text
- l'intérêt des (nombreux, on n'est ici dieu merci pas dans une démarche marketingue) paramètres souvent abscons est laissé aux essais et erreurs de l' utilisateur. Lequel est parfois plus proche du rat de labo que du chimpanzé évolué.
- il serait judicieux de séparer les "filtres" "fun"(??) des "filtres" un peu plus sérieux utiles à la retouche photo, ça ferait gagner du temps. Ceci dans les listes de filtres, mais aussi dans la doc qui reste à faire… 400 filtres x 6 ou 10 paramètres en moyenne, bonjour les essais!
Bref, je rêve d'une doc utilisateur qui me dirait: pour faire ceci (en langage d'image, même évolué, mais pas en termes d'algorithmes),
il faut utiliser tel(s) filtres, l'influence (en matière d'image résultante) de leurs paramètres portant sur cela…
[^] # Re: Gmic, encore un effort!!
Posté par Nicolas Boulay (site web personnel) . Évalué à 1.
C'est plus qu'une doc qu'il faudrait. C'est plus un wizard bien fait qui est nécessaire : tri par arborescence plutôt qu'une liste; Wizard type page web avec les instructions nécessaires pour comprendre le filtre (avec pourquoi pas un schéma à cliquer dessus).
"La première sécurité est la liberté"
# Une belle découverte
Posté par Nairwolf . Évalué à 3.
Bonsoir,
Je m'intéresse depuis quelques semaines à la retouche d'images, et je suis donc en phase d'apprentissage pour le logiciel Gimp. C'est donc avec un véritable bonheur que je découvre votre logiciel. A en lire la dépêche, il a l'air vraimnent incroyable, il m'a donné envie de l'utiliser, et d'apprendre à faire encore plus de choses sur les images.
Merci beaucoup pour vos travaux ;)
# Accéléré
Posté par teoB . Évalué à 3.
De temps en temps, j'aime bien faire un time-lapse. En général, j'utilise ImageMagick pour faire le traitement des photo par lots & ensuite FFmpeg pour les assembler en une vidéo. Si je comprends bien, je pourrais faire tout cela en une seule commande avec G'MIC ?
En tout cas merci pour le travail accompli, ainsi que de m'avoir fait découvrir Natron.
# Gmic pour la vidéo
Posté par TML . Évalué à 2. Dernière modification le 23 avril 2015 à 09:17.
Bonjour et premièrement, félicitations pour ce remarquable travail.
Je me demande dans quel mesure G'mic pourrait traiter de la vidéo en temps réel dans la ligné de filtres vidéo type frei0r : http://frei0r.dyne.org/ , que j'utilise par a travers le très cool veejay - http://veejayhq.net (sur lequel je vais faire un article un de ces quatres…)
Salutations….
[^] # Re: Gmic pour la vidéo
Posté par David Tschumperlé (site web personnel) . Évalué à 5.
G'MIC peut traiter de la vidéo plus ou moins en temps réel, ça dépend bien sûr de la complexité du filtre à appliquer. Un bon exemple pour voir ça, c'est à travers le logiciel ZArt, une interface qt pour G'MIC dont le but est justement de traiter de la vidéo. Une petite vidéo de démonstration de ZArt qui tourne en temps réel est disponible sur youtube :
https://www.youtube.com/watch?v=k1l3RdvwHeM
On voit tourner quelques fitres sur la vidéo provenant d'une webcam dans un premier temps, puis d'un fichier vidéo dans un deuxième temps.
[^] # Re: Gmic pour la vidéo
Posté par TML . Évalué à 1.
Merci …. je viens de poster cela sur la liste de discussion de veejay
Salutations et bonne continuation
Suivre le flux des commentaires
Note : les commentaires appartiennent à celles et ceux qui les ont postés. Nous n’en sommes pas responsables.