
Un des débats qui fait rage parmi les développeurs d'OpenStack réside dans le choix d'un framework commun pour le développement de leurs API. Pour information ou rappel, OpenStack est un moteur de cloud (informatique en nuage) de type IaaS (Infrastructure as a Service) issu de la fusion de la plateforme de cloud de la NASA (projet Nebula) et de Cloud Files de Rackspace (cloud storage), la société texane d'hébergement. Cette pile de logiciels libres est écrite en Python sous licence Apache et s'appuie sur la norme WSGI pour exposer ses APIs.
Pour reprendre une définition donnée par misc : « OpenStack, c'est beaucoup de choses, c'est un groupe de logiciels visant à gérer un nombre massif de machines virtuelles. En gros, tu rajoutes des serveurs, et OpenStack va faire tout seul le fait de rajouter des VM à la demande, via une API. API qu'on peut donc utiliser dans une interface web, ou via un script. » OpenStack se veut le concurrent open source de la plateforme propriétaire Amazon Web Services.

(source)
{kind=link}
La dernière version d'OpenStack (nom de code : Grizzly) a été publié le 4 avril 2013 et offrait les composants suivants :
- Nova : gestion d'instances de calculs
- Swift : stockage d'objets
- Cinder : gestion de volumes blocs
- Keystone : authentification
- Quantum : gestion de réseaux virtualisés
- Dashboard : framework fournissant une interface d'administration web extensible basé sur Django
- Ceilometer : collecte de métriques
- Heat : orchestration
Les API : un point clé
À l'heure actuelle, tous ces composants proposent une API REST native ainsi qu'une API offrant une compatibilité plus ou moins complète avec le leader du marché : Amazon Web Services.
Les API sont un point crucial pour le projet OpenStack, elles sont massivement utilisées à la fois en interne et par les utilisateurs finaux comme on peut le voir dans le diagramme ci-dessous.
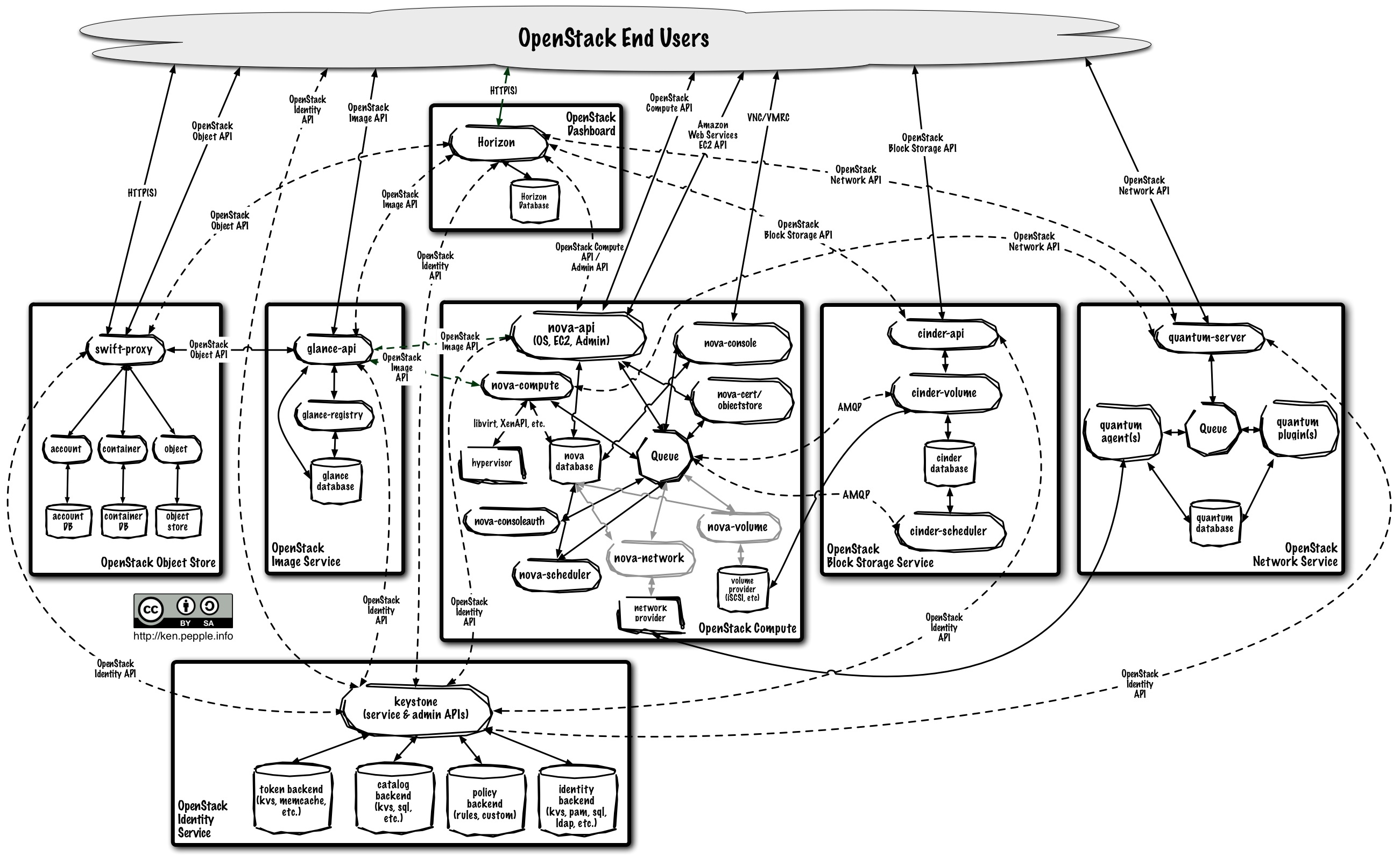
(source)
{kind=link}
Les frameworks actuellement en compétition
Deux compétiteurs sont actuellement en cours de discussions sur la liste.
Falcon
Falcon développé par Kurt Griffiths de Rackspace et annoncé comme étant un micro-framework pour développer des API supersonique pour le cloud (rien de moins que ça !). Il est utilisé dans le projet Marconi qui vise à fournir un service de messages queueing dans OpenStack.

Pecan et WSME
Pecan & WSME proposé par Doug Hellman, mainteneur du projet Ceilometer.

État des lieux
Actuellement, Nova utilise eventlet pour la partie réseau et Webob pour gérer les objets requêtes/réponses HTTP.
code middleware WSGI dans Nova
Swift quant à lui redéfinit ses propres objets requêtes/réponses HTTP.
code middleware WSGI dans Swift
code Requêtes/Réponses WSGI: SWOB
Ceilometer utilisait Flask pour la version 1 de son API puis Pecan/WSME pour la version 2
code de l'API v1
code l'API v2
On notera que pour des raisons de stabilité, quelque soit la solution choisie au final, les API existantes ne seront pas réécrites. Par exemple, dans le cas de Ceilometer, si Falcon était choisi, la v1 continuerait à utiliser Flask, la v2 Pecan/WSME, la v3 utiliserait Falcon. Les versions 1 & 2 continueraient à être distribuées pendant un certain temps.
OpenStack, Bazar et retours d'expériences
Bref, OpenStack est un vrai projet Bazar. La publication par Rackspace de Falcon a relancé le débat. Un point extrêmement intéressant est le retour d'expérience sur les différents frameworks WSGI dans des configurations massivement parallèles.
Éléments requis
Pour OpenStack, plusieurs critères comptent :
- performance ;
- listes de dépendances maitrisable;
- prise en charge de Python 3 ;
- possibilité de configurer les API sans trop de difficultés.
Possibilités
Falcon a été développé dans cette optique-là, la suite de benchmarks publiée montre qu'il bat à plate couture l'ensemble des frameworks existants (et ce, sans extensions natives). Il ne requiert que l'interpréteur Python et le package six permettant la prise en charge de Python 2.7 & 3.3+ à l'aide d'une même base de code. Néanmoins, il a pour inconvénient d'être justement trop léger au niveau des fonctionnalités pour développer une API REST de manière confortable.
Pecan est quant à lui un micro-framework WSGI encore peu connu, mais qui évolue très rapidement. Il a été créé pour faciliter le développement d'application RESTful sans fioritures. Il s'inspire ouvertement de CherryPy/TurboGears 1 et a le bon goût de s'appuyer sur WebOb qui pour le moment semble faire l'unanimité autour de lui (même l'exception SWOB s'en inspire ouvertement).
Quant à WSME c'est une réimplémentation des contrôleurs REST de TurboGears 1 (un des points forts de ce vénérable framework) destinée à être intégrée à d'autres frameworks (Pecan, Flask, Bottle, Pyramid via l'excellente extension Cornice, etc.). Le combo est relativement jeune mais tire profit de plusieurs années de retour d'expérience. L'inconvénient est que c'est une solution relativement intrusive qui, de l'aveu de Doug Hellman, peut difficilement être réalisée de manière incrémentale, elle influencera également la manière dont sont conçues les API.
L'apparition de Falcon a été également l'occasion de redonner un coup de fouet à la quête de performances pour Pecan. Ryan Petrello (DreamHost) a pu améliorer de 30% les résultats de Pecan par rapport aux benchmarks publiés par Falcon en quelques heures de travail.
Tempête de cerveaux
Pour le moment rien n'est décidé, le débat continue encore sur la liste openstack-dev à propos de l'implémentation de la nouvelle API de Nova.
Doug Hellman s'appuie sur les acquis du projet Ceilometer pour promouvoir l'utilisation de Pecan/WSME, et Kurt Griffiths a pour lui l'appui de Rackspace, fondateur du projet.
Une affaire à suivre…
Aller plus loin
- Projet OpenStack (259 clics)
# Un peu de hauteur... et de pub :)
Posté par Jean Parpaillon . Évalué à 6.
Il me semble important de noter ici l'existence du projet CompatibleOne, qui est un broker open source. Concrètement, un utilisateur peut décrire l'application et ses besoins dans un format indépendant de la plateforme IaaS finale (CORDS) et le runtime (ACCORDS) va provisionner l'infrastructure adéquate, en notifiant éventuellement l'utilisateur si des contraintes ne peuvent être remplies.
Bien que le projet soit jeune (environ 1 an), il peut déjà se connecter sur du openstack, opennebula, azure, ec2 (et j'en oublie).
Le projet est sous license Apache et les sources sont hébergées ici. Il manque encore pas mal de doc et de "polish" mais ce type de projet peut participer à laisser les APIs Openstack faire le ménage pendant que les utilisateurs ne se soucient que de leurs applications :)
"Liberté, Sécurité et Responsabilité sont les trois pointes d'un impossible triangle" Isabelle Autissier
# [HS] Désolé
Posté par Laurent Cligny . Évalué à 3.
Tu bluffes Marconi !
[^] # Re: [HS] Désolé
Posté par GeneralZod . Évalué à 1.
Marconi c'est le mieux meilleur projet d'OpenStack, faut faire des demandes de pulls dessus !
[^] # Re: [HS] Désolé
Posté par lendemain . Évalué à 1.
Des pue l'ovaire?
# Pourquoi faire simple quand on peut faire compliqué
Posté par 0xfg . Évalué à 6.
En regardant le schéma, la première chose que je suis me suis dite est "Wahoo, c'est une usine à gaz ce truc"…
Il y a vraiment des gens qui utilise ça en production ?
Moi qui croyais que les systèmes les plus fiables étaient les plus simples.
[^] # Re: Pourquoi faire simple quand on peut faire compliqué
Posté par Zenitram (site web personnel) . Évalué à 5.
Des fois on n'a pas le choix, on n'est plus en 1970 à faire quelques calculs simples.
La demande est différente, les solutions plus complexes car les simples ont déjà été faites.
Ca peut se simplifier un peu, mais ça restera quelque chose de complexe.
[^] # Re: Pourquoi faire simple quand on peut faire compliqué
Posté par GeneralZod . Évalué à 6.
L'ensemble parait complexe mais de fait, l'architecture d'OpenStack est relativement simple par rapport aux problématiques adressés.
OpenStack est conçu autour d'une architecture SOA autour d'un bus de messagerie (par défaut RabbitMQ, mais également QPid ou bien zeromq en brokerless), la plupart des services sont utilisables indépendamment.
Sur le diagramme, chaque rectangle correspond à un service, Nova mis à part, ils sont relativement simples, en gros, t'as un frontend API et un backend pour faire le boulot. Dans le cas de Nova, c'est le composant central et il doit s'interfacer à plusieurs services pour fournir des fonctionnalités (gestion des autorisations, images, réseaux, stockage etc.)
En comparaison, Eucalyptus semble avoir une architecture plus simple mais chaque composant est nettement plus complexe que dans le cas d'OpenStack. Malgré un leadership distribué (Cf. l'implémentation), je trouve fascinant qu'OpenStack ait une conception aussi bien définie et une implémentation qui reste compréhensible et avec des snippets de code très élégants (et instructifs)
Par exemple, Doug Hellmann a extrait/développé des paquetages Python pour les besoins d'OpenStack qui utilisent de manières très astucieuses setuptools/distribute:
stevedore: architecture de plugin
Cliff: gestion CLI
[^] # Re: Pourquoi faire simple quand on peut faire compliqué
Posté par bubar🦥 . Évalué à 1. Dernière modification le 08 mai 2013 à 13:34.
La simplicité se trouve t elle toujours dans l'unicité ? Une autre solution, mettons solutionX, propose un seul produit permettant les mêmes services. Est ce plus simple ? Sachant, ou même entrevoyant, la complexité nécessaire à l'objectif ? Complexité apparente, puisqu'il s'agit d'une complexité de nombre de briques et services, on peut dire que c'est permet une simplicité dans la gestion des projets, à contrario d'une grosse usine à gaz uniforme. Une meilleure atomicité des développements, mais aussi de la maintenance et des ajustements aux besoins. Non ?
Côté vision client, tu as la vision "on te prends pour un con" aka "c'est le cloud", ou bien la vision "on te montre les couches, chacune des briques" aka "c'est le cloud".
Pour faire un parallèle capillotracté et une touche d'humour, c'est la vision des dépendances par un néophyte "ouha c'est compliqué, quelle usine à gaz", alors qu'en réalité c'est une simplicité pour la maintenance.
mes deux cents
# Juste une question, là comme ça, ça me pète
Posté par homer242 (site web personnel) . Évalué à 1.
Et dit dont, faut lire combien de tomes de 300 pages pour utiliser un cloud ?
moi même étant développeur, en voyant ça le cloud me parait tout de suite moins sexy…
[^] # Re: Juste une question, là comme ça, ça me pète
Posté par tyoup . Évalué à 3.
Eh c'est pas évident de mettre un cloud en place. Il faut des bons outils et une certaine dextérité. En fonction de l'architecture que tu souhaites réaliser, ça se fait effectivement à coups de tomes de 300 pages. Et des fois même en s'y prenant bien le cloud se retrouve quand même tout tordu et là bonjour pour redresser la situation. Et, attention, c'est dangereux de mettre le doigt dedans.
Suivre le flux des commentaires
Note : les commentaires appartiennent à celles et ceux qui les ont postés. Nous n’en sommes pas responsables.