
Je forme de longue date des utilisateurs à Dolibarr et j’ai été amené à côtoyer toutes sortes d’entreprises, pris conscience de leurs besoins et mode de fonctionnement. Quand Philippe Scoffoni d’Open-DSI, m’a présenté Metabase, un outil d’analyse de données, j’ai tout de suite été emballé, c’était clairement l’outil idéal pour tout un tas de structures.
C’est aussi ce qui m’a poussé ensuite à écrire un livre et maintenant à vous présenter l’outil. Bien sûr, il a aussi ses limites, mais sa simplicité de mise en place au regard de tout ce qu’il permet de faire mérite le détour. Et surtout ce serait dommage de ne pas en profiter.
Metabase, de la BI1 open-source ?
Initialement, Metabase a été développé par un incubateur américain pour suivre les performances des start-ups qu’il finançait. Aujourd’hui, l’application est distribuée sous deux licences : une licence libre (AGPL) et une licence non-libre (Metabase Commercial License).
La version open-source est téléchargeable sur GitHub ou sur le site de Metabase sous différents paquets (docker ou archive jar) et le développement est assuré par l’équipe de Metabase, mais les contributions sur GitHub sont les bienvenues !
Le principe
Le fonctionnement est simple : on connecte Metabase à une base de données et on en contrôle le modèle. On peut alors interroger les données via un assistant, sans connaissance du langage SQL. On peut enfin choisir les options d’affichage (histogramme, tableau, courbes…) et enregistrer ces interrogations pour en afficher les résultats à la demande. Les interrogations de données peuvent faire l’objet d’un partage public ou privé, être téléchargées ou ajoutées à des tableaux de bord.
Installation et bases de données supportées
Metabase fournit des packages .jar ou docker.
Les bases de données dont Metabase sait lire les données sont nombreuses :
- BigQuery
- Druid
- Google Analytics
- H2
- MongoDB
- MySQL
- Oracle
- PostgreSQL
- Presto
- Redshift
- Snowflake
- SparkSQL
- SQL Server
- SQLite
- Vertica
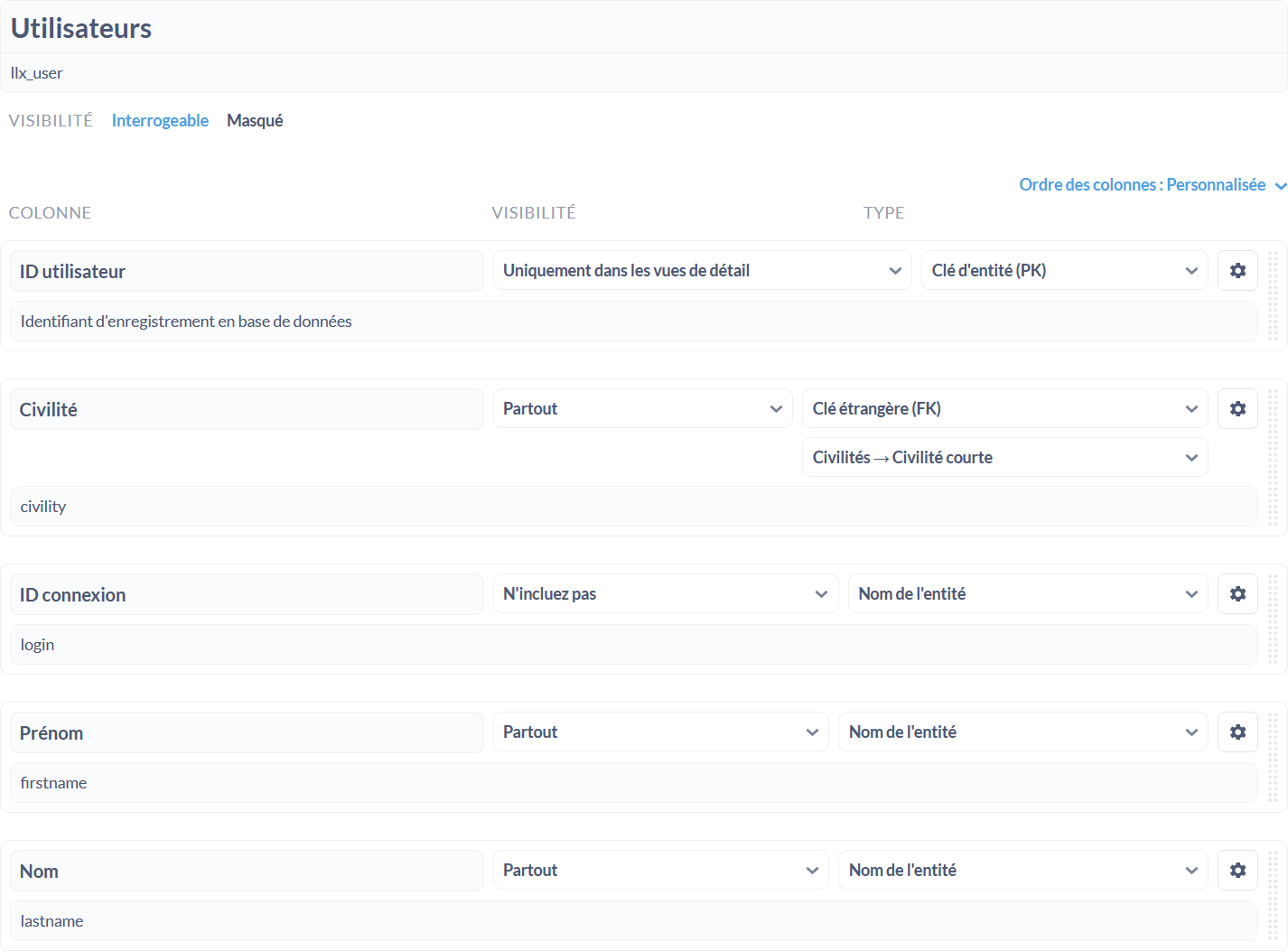
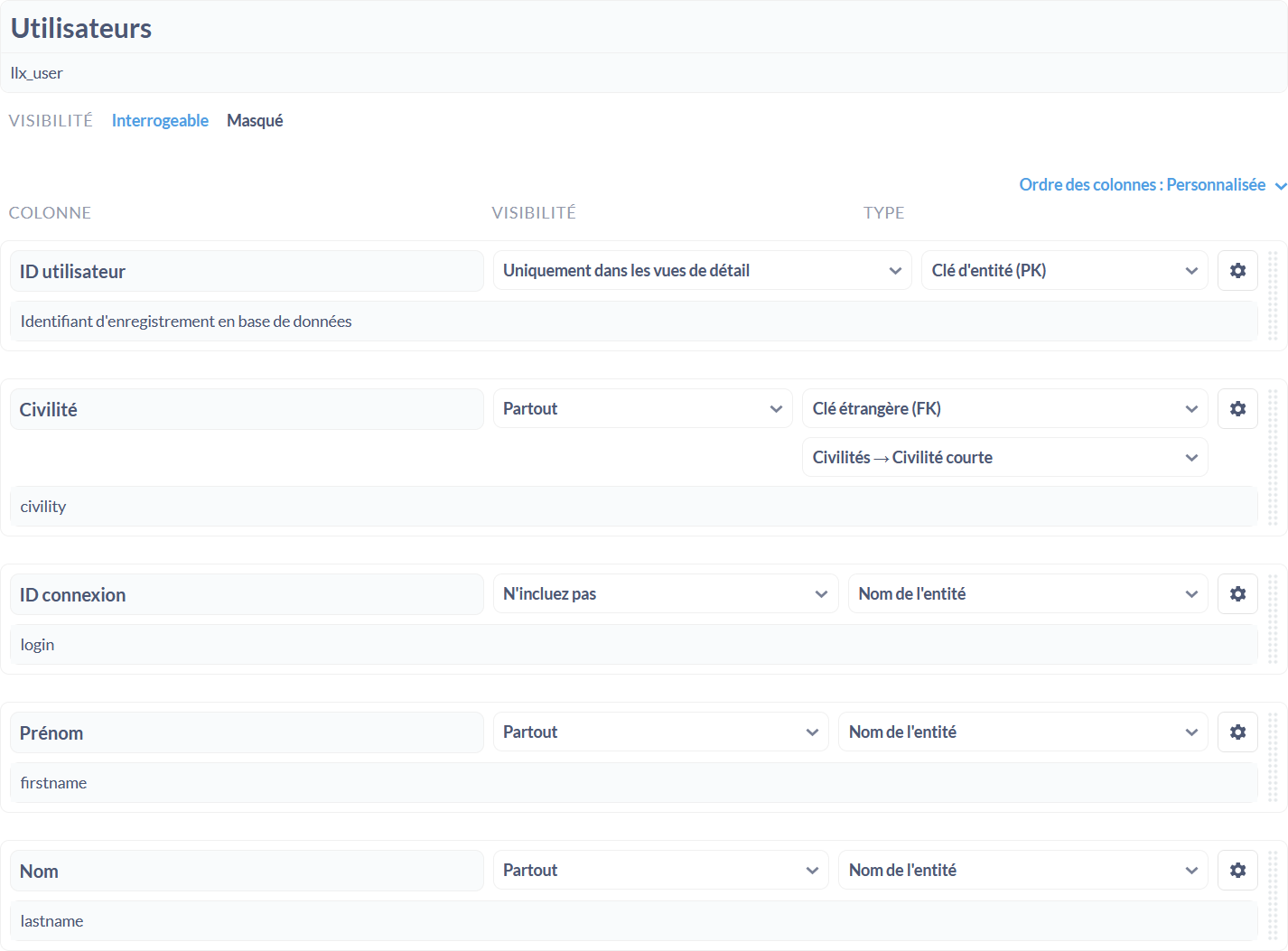
Préparation des données
Une fois l’installation et la connexion à une base de données réalisées, on prépare ses données en indiquant les tables et leurs colonnes qu’on souhaite pouvoir consulter et on contrôle/ajuste le modèle de données. C’est une opération à ne faire qu’une fois, mais importante : il s’agit de vérifier le type des données contenues dans les champs à interroger (date, quantité, montant, etc.), que les clés primaires sont bien définies, tout comme la cible des clés étrangères.
 (source)
(source)
{kind=link}
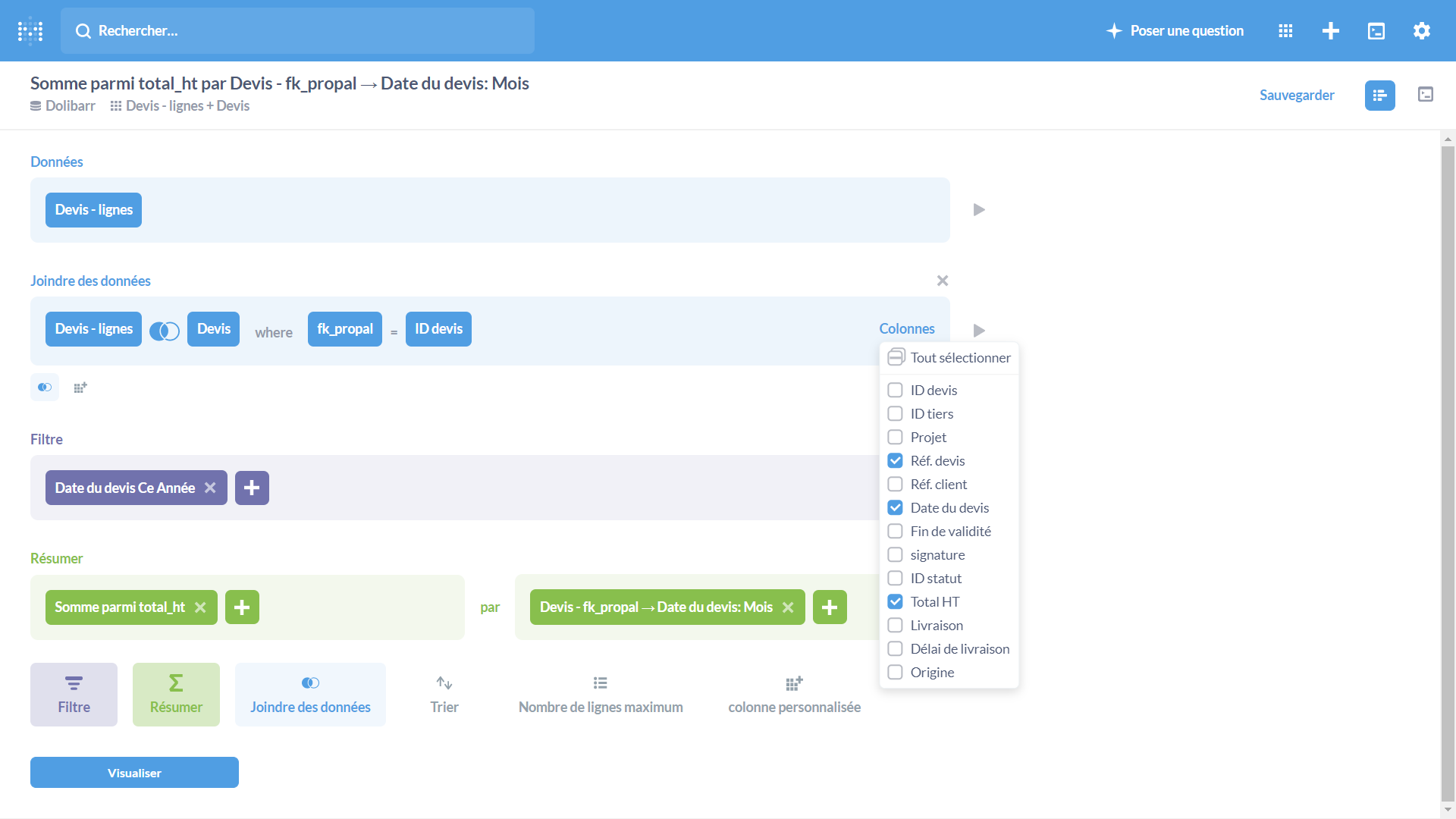
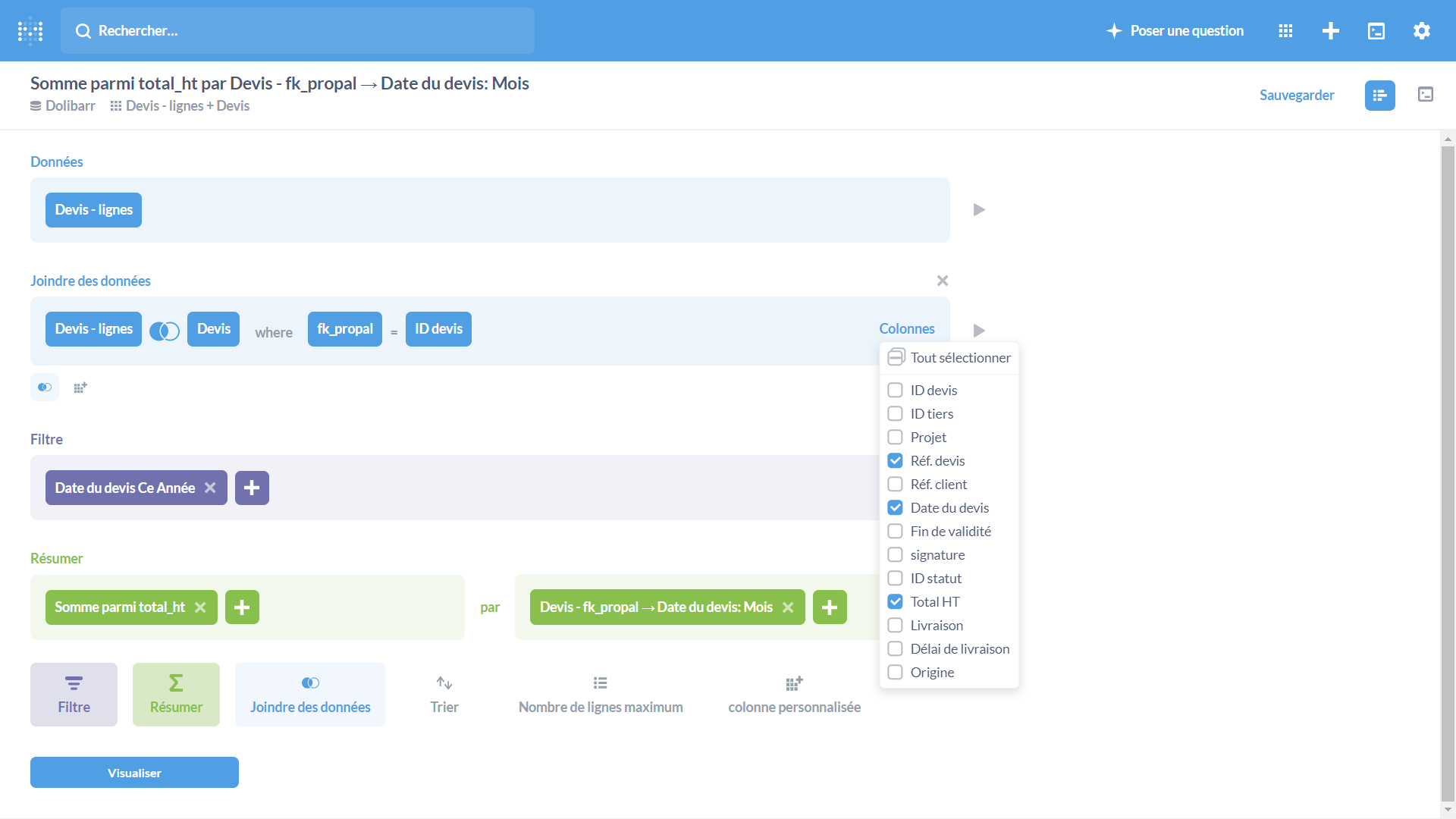
Interrogation de ses données
Metabase est un requêteur SQL dont l’assistant ergonomique et intuitif permet de se passer de la connaissance du langage SQL.
Pour des interrogations complexes, on peut créer des vues sur la base de données et les interroger. Pour les connaisseurs du SQL, Metabase inclut un éditeur dans lequel saisir les requêtes SQL.
 (source)
(source)
{kind=link}
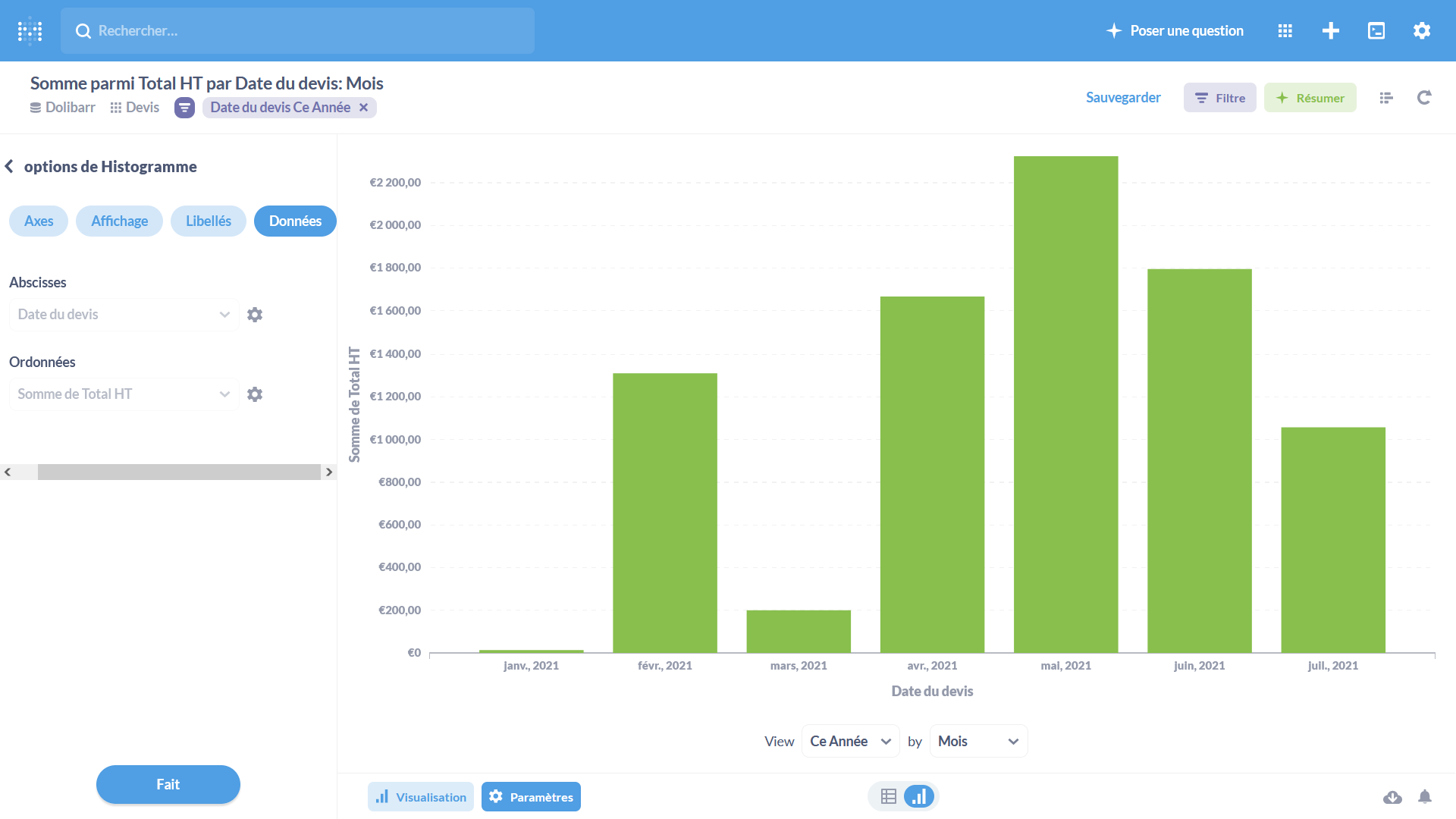
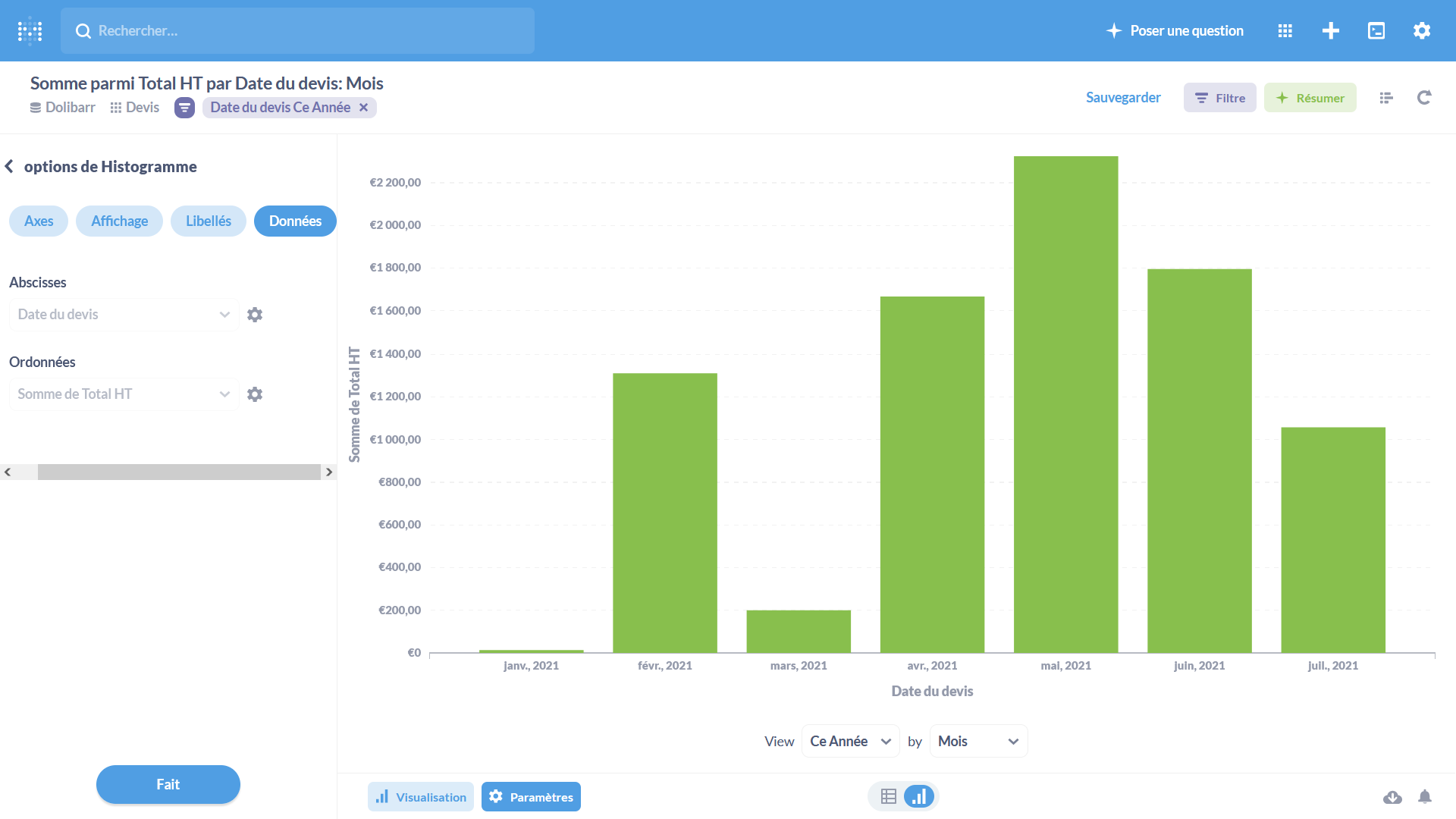
Une fois les résultats renvoyés, on leur applique la représentation graphique la plus adaptée parmi les seize disponibles.
 (source)
(source)
{kind=link}
Chacune dispose de ses propres paramétrages et personnalisations d’affichage et on peut les enregistrer pour les consulter à tout moment, les résultats étant mis à jour au moment de leur affichage.
 (source)
(source)
{kind=link}
On peut regrouper les interrogations de données dans des tableaux de bord thématiques sur lesquels ajouter divers filtres et options.
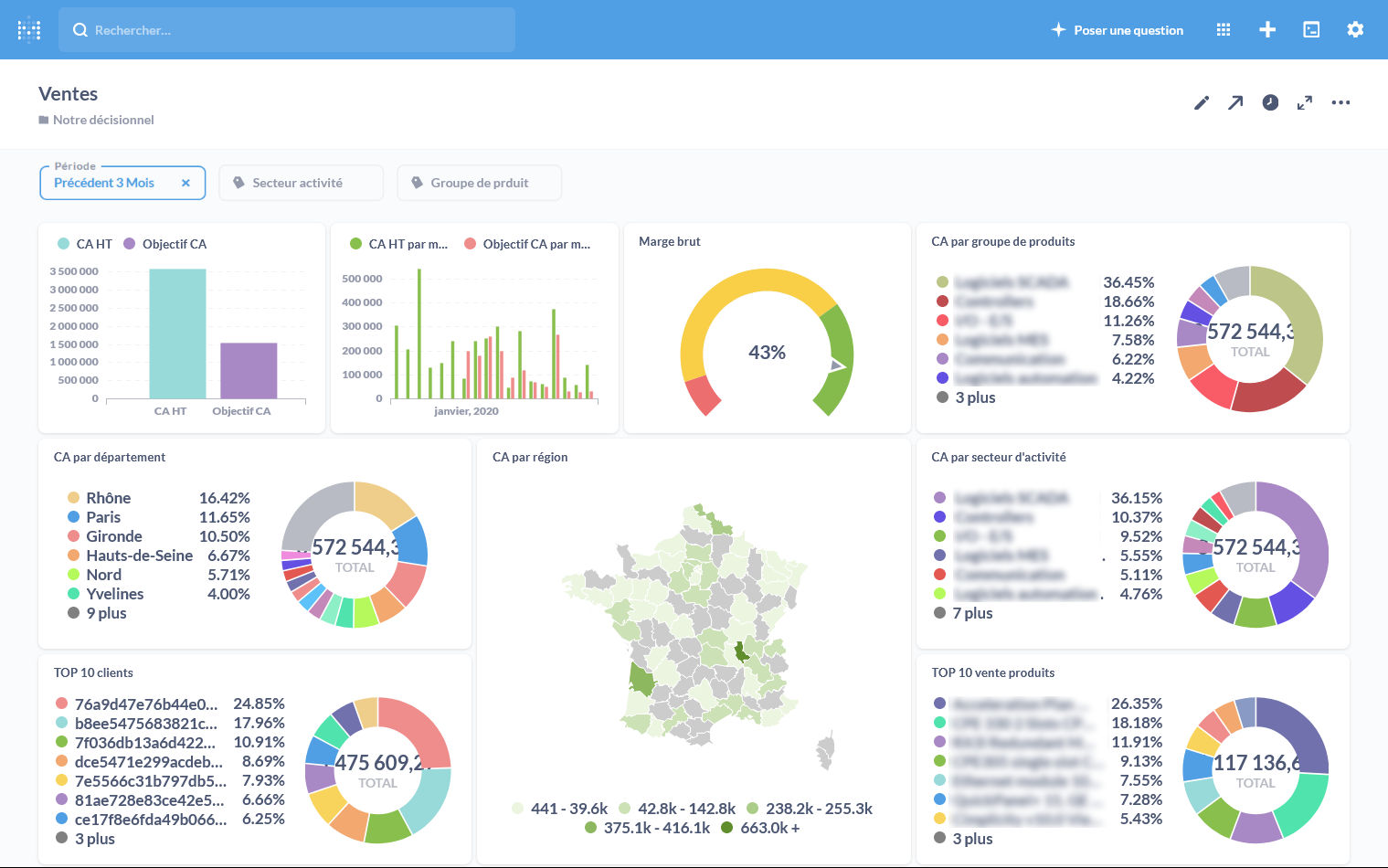 (source)
(source)
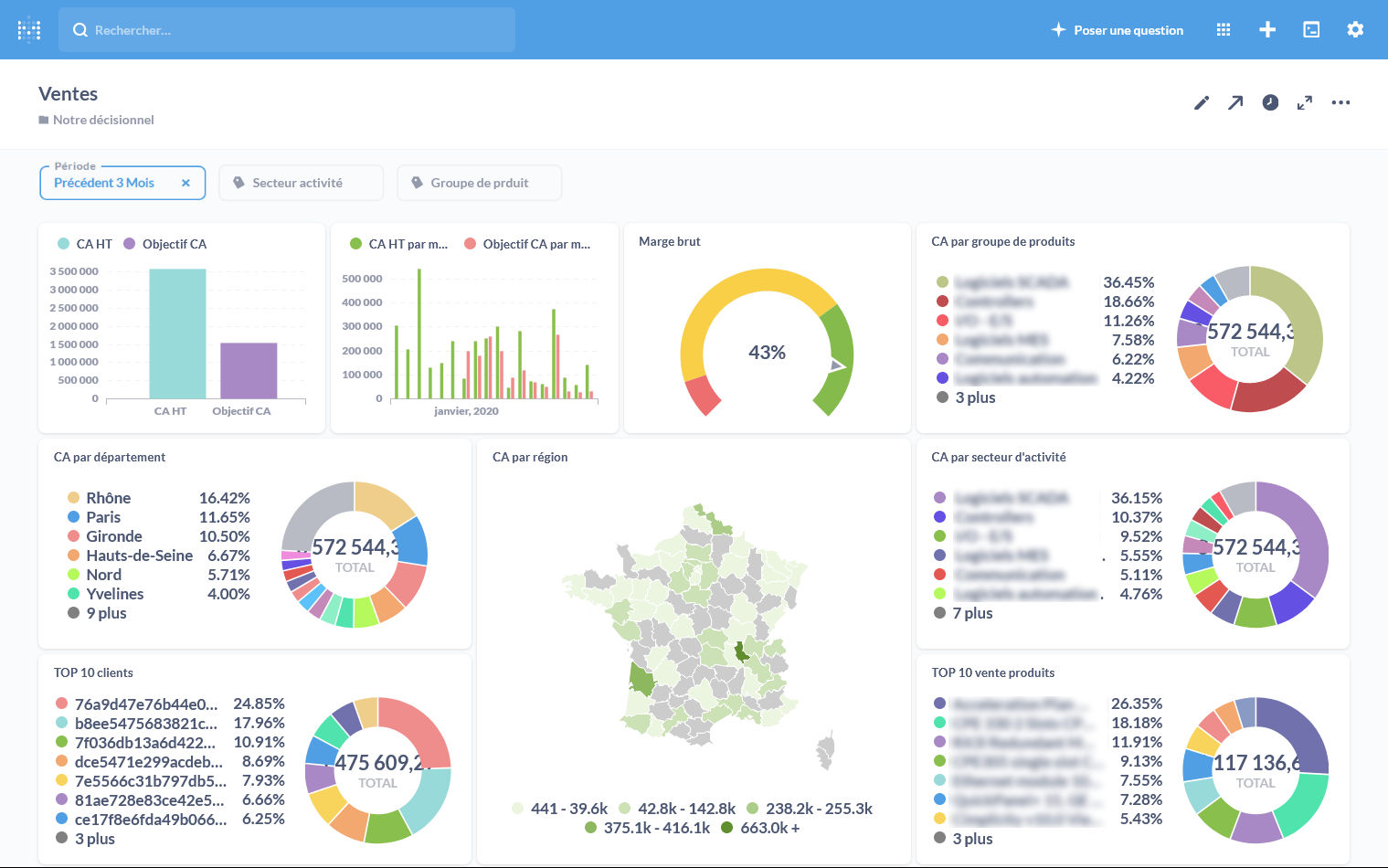{kind=link}
Perspectives
Pour une entreprise, la mise en place de Metabase est à la portée de n’importe quel prestataire.
Pour un prestataire informatique : il peut y voir la possibilité d’élargir simplement son offre en intégrant des outils de reporting très aussi simples d’utilisation.
-
N. D. M. : BI ou business intelligence, le terme anglais pour informatique décisionnelle ↩
Aller plus loin
- Site de Metabase (580 clics)
- Dossier sur d-booker.fr (174 clics)
- Et pour la prise en main utilisateur, mon livre :-) (220 clics)
# Attention quand même au RGPD :D
Posté par Aeris (site web personnel) . Évalué à -4. Dernière modification le 28 novembre 2021 à 12:24.
Si Metabase est un outil extrêmement puissant, c’est aussi typiquement le genre d’outil qui sera très rapidement bordeline niveau conformité RGPD.
Le fait de pouvoir dynamiquement faire tout plein de requêtes, de recroiser les données dans tous les sens voire mettre à dispo les données brutes non agrégées est la porte ouverte à tous les détournements de finalité.
La conformité RGPD limite souvent la puissance de Metabase, puisque les données brutes doivent nécessairement (article 5.c) être déjà agrégées et leur format interdire (article 5.b) le détournement de finalité, donc de limiter les possibilités de requêtes ou de création de dashboard « à la volée ».
Et Metabase se transforme du coup en « simple » visualiseur avancé permettant de filtrer par date/catégorie des tables pré-définies, perdant beaucoup de sa flexibilité.
[^] # Re: Attention quand même au RGPD :D
Posté par Jérôme FIX (site web personnel) . Évalué à 8. Dernière modification le 28 novembre 2021 à 13:03.
Il dit qu'il voit pas le rapport ?
Cela n'a rien à voir avec l'outil, mais avec les données que l'on manipule.
Tout ne se rapporte pas à des données personnelles !
[^] # Re: Attention quand même au RGPD :D
Posté par Aeris (site web personnel) . Évalué à -3.
Tu manipules très souvent des données personnelles hein… Ou dit autrement des stats sans données personnelles à l’origine ou à la fin sont généralement assez peu intéressantes.
Et bien penser aussi qu’un traitement de données personnelles, c’est aussi la collecte de la donnée, et pas uniquement l’extraction ou affichage ultérieur. Si l’origine même de ta donnée contient une donnée perso (facture, paiement, etc), alors sa réutilisation pour des finalités autres que initiale est encadrée voire proscrite.
Typiquement des stats sur ta compta sont aussi touchées par le RGPD parce que ta facture initiale contient de la donnée perso, même si la stat finale, elle, ne contient pas de données perso.
Et la base légale (« intérêt légitime ») et finalité (« suivre mon commerce ») de tes stats seraient plutôt en contradiction avec la finalité initiale de la facture (« encaisser un paiement ») et sa base légale (« obligation légale »). Tu n’as donc pas le droit de partir de ton stock de facture pour établir tes stats de commerce (détournement de finalité et utilisation d’une base légale incompatible).
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 7.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Re: Attention quand même au RGPD :D
Posté par Aeris (site web personnel) . Évalué à -2. Dernière modification le 28 novembre 2021 à 14:39.
C’est un peu plus compliqué que ça. 2 traitements différents portant sur la même donnée peuvent effectivement avoir des bases légales différentes, mais la donnée initiale elle-même a déjà fait l’objet d’un traitement (sa collecte) avec une certaine base légale et tous les traitements derrière ne peuvent du coup qu’avoir une base légale compatible avec la base légale initiale.
Il est impossible de faire un traitement ultérieur d’une données sous la base légale « intérêt légitime » si la base légale initiale de la collecte de cette donnée ne contenait que « consentement ». Ton point de collecte définit le périmètre maximal qu’il ne sera jamais possible de dépasser sur l’ensemble des traitements ultérieurs présents ou futurs qui sera fait sur ces données.
Et mon point est justement là : Metabase est la porte ouverte à toutes les fenêtres, les utilisateurs envisageant difficilement quelles requêtes vont être toujours dans le scope légale de la collecte initiale. Ce n’est pas parce que la donnée est à dispo et que tu peux en sortir un joli dashboard sous Metabase que ce que tu fais est autorisé.
Et ce n’est pas parce que tu renseignes ton registre de traitement avec le nouveau traitement et sa base légale qu’il devient magiquement légal s’il reste incompatible avec la finalité et base légale de la collecte initiale.
Voir par exemple les condamnations pour finalités incompatibles avec la collecte initiale de la donnée.
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 4.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Re: Attention quand même au RGPD :D
Posté par Aeris (site web personnel) . Évalué à 2.
Les 2 sont importants. J’ai peut-être donné l’impression de ne parler que de l’un, mais ce n’est pas le cas. Et à mon sens les 2 sont assez liés, une nouvelle finalité risque fort de réclamer une nouvelle base légale.
C’est particulièrement vrai dans le cas de la BI, les données à dispo sont souvent sous une base légale de collecte (obligation légale ou nécessaire au contrat) incompatible avec des finalités statistiques qui elles nécessitent obligatoirement de l’intérêt légitime voire du consentement d’après EDPB.
Et les produits de BI sont souvent marketés comme « vous avez des données dont vous ne faites rien, sortez-en des stats utiles ». Typiquement chez Metabase, « Meet the easy, open source way for everyone in your company to ask questions and learn from data ».
De plus, le RGPD interdit l’ajout préventif de finalité/base légale « pour des besoins ultérieurs » selon les mots de EDPB. Les besoins doivent être factuels, présents et justifiés. Les finalités de collectes sont du coup nécessairement incompatibles avec l’ajout ultérieur à la volée de filtres/recroisement dans des outils comme Metabase.
C’est uniquement mon point soulevé : la facilité d’ajout de dashboard/filtre/graphe, de recroisement ou d’accès à la donnée est en décalage comparée à la rigidité et la difficulté d’ajout de telles nouvelles finalités dans le cadre d’une conformité RGPD correcte.
[^] # Re: Attention quand même au RGPD :D
Posté par L33thium . Évalué à -1. Dernière modification le 28 novembre 2021 à 13:39.
Le RGPD exige de recueillir le consentement éclairé sur l'usage qui en sera fait avant la collecte de données et que la collecte de toute donnée non essentielle soit considérée comme refusée par défaut.
(ce n'est qu'une clarification et uniformisation européenne de la loi informatique et liberté)
Donc traiter des données en interne à usage statistique sans transmission a des tiers ne viole pas le règlement si les clients ont été informés et ont consentis.
Et je ne vois pas en quoi ce type de logiciel traitant essentiellement des données comptable et de facturation peut violer le RGPD.
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 10.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Re: Attention quand même au RGPD :D
Posté par Singman . Évalué à 3.
Je ne peux pas laisser passer ce commentaire qui, a priori, vient de quelqu'un qui n'a jamais utilisé B.I.
En effet, c'est un outil très populaire dans la gestion de production notamment, et qui donc manipule des données sans aucun lien avec le RGPD. Je pense qu'il n'existe pas une seule usine au monde qui fonctionne sans sa gestion des données de production, sans ses rapports, ses projections, toutes les aides à la décision que B.I. apporte.
[^] # Re: Attention quand même au RGPD :D
Posté par Watchwolf . Évalué à 2.
Lorsque tu receuille les données de ton client pour le facturer tu es soumis au RGPD.
Ensuite lorsque tu extrait de cette facture toute les données qui ne sont pas personnelle (date / montant / pays) tu anonymise ces données, tu n'es plus soumis au RGPD ensuite.
Tu peux alors faire des traitements pour savoir où sont tes clients, comment tels pays comporte, quel pays achète tel produit à quelle période …
Je veux bien que quelqu'un confirme (ou non) ce raisonnement svp.
[^] # Commentaire supprimé
Posté par Anonyme . Évalué à 6.
Ce commentaire a été supprimé par l’équipe de modération.
[^] # Re: Attention quand même au RGPD :D
Posté par Aeris (site web personnel) . Évalué à 1. Dernière modification le 29 novembre 2021 à 10:43.
C’est exactement le point. La BI telle qu’on la faisait avant est mise pas mal à mal avec l’entrée en vigueur du RGPD en 2016.
Beaucoup des traitements effectués avant sont dorénavant très touchy niveau RGPD, avec des bases légales frileuses.
EDPB est assez clair sur le sujet : ces stats ne sont pas une obligation légale et n’ont généralement pas un intérêt légitime suffisant devant les dérives possibles (oui, le RGPD adore raisonner selon les possibilités théoriques et non selon les réalités pratiques), la seule base légale a priori recevable sauf justification très forte est le consentement.
Et la plupart des utilités supposées de la BI disparaissent encore plus avec du consentement, parce que ça veut dire que tes chiffres deviennent imprécis (fort probabilité de refus du consentement = données non fiables = pertes d’intérêts = encore moins de légalité du traitement) et que le process de détention des données devient trop chronophage et coûteux par rapport à la plus-value qui en ressort (gestion de la rétractation du consentement nécessitant la suppression des données et des traitements ultérieurs, droits d’accès et rectifications, DPIA avant intégration au registre de traitement, etc)
Ça donne par exemple :
https://www.linkedin.com/pulse/gdpr-has-big-implications-business-intelligence-nick-ringle?articleId=6408376440735301632
https://wiiisdom.com/white-paper/business-objects-gdpr-compliance/
https://tdwi.org/articles/2018/06/04/biz-all-gdpr-impact-on-bi-1.aspx
et tant d’autres sujets qui sont actuellement complètement passés sous silence devant la facilité de ces outils de sortir du cadre réglementaire.
Voir aussi par exemple cette condamnation à 50.000€ d’amende, pour avoir eu un outil de BI trop ouvert.
# Redash like ?
Posté par xandercagexxx . Évalué à 5.
Metabase est-il de près ou de loin un concurrent de Redash ?
Metabase propose-t-il un stockage des select sql effectué pour par exemple avoir une courbe représentant une valeur en fonction du temps tout en étant déconnecté de la base de données de production ?
Je pose la question car redash ne le propose pas et c'est très consommateur de ressources d'afficher un graphique en partant a chaque fois de la bdd de prod pour afficher un historique sur plusieurs années (le but ici étant d'avoir un historique même si les valeurs ne sont pas horodaté dans la bdd source.
Est-il possible "facilement" de créer des graphiques personnalisé et d'y afficher des données venant de plusieurs type de bdd ? (Genre dans le même graphique recouper des infos venant de mysql et postgres ?).
Merci
[^] # Re: Redash like ?
Posté par Bruno (Mastodon) . Évalué à 2.
Je ne connais pas Redash mais on peut comparer Metabase avec Apache Superset, à part la licence ;-)
Si je comprends bien ce dont tu as besoin c'est d'une table historique , ce n'est pas l'outil qui le fait tout seul. En fait c'est la base d'un Système d'Information Décisionnel qui est là pour historiser,agréger,préparer etc sans attaquer la base de Prod dans son ensemble.
[^] # Re: Redash like ?
Posté par LeBouquetin (site web personnel, Mastodon) . Évalué à 2.
Pour reformuler la question de xandercage, on a des tableaux de bord qui permettent de voir l'état du système à un instant donné. Mais si on veut voir l'évolution temporelle on n'a pas l'information :
Mais il manque une couche intermédiaire qui stockerait le résultat de la requête SQL exécutée toutes les x secondes/minutes/heures/jours, etc pour voir l'évolution.
On pourrait mettre en place des outils de monitoring, mais ça sera pas plug&play et ça ne m'a pas l'air "fait pour" (dans l'usage).
Je suis preneur de noms d'outils si vous avez des idées
#tracim pour la collaboration d'équipe __ #galae pour la messagerie email __ dirigeant @ algoo
[^] # Re: Redash like ?
Posté par Philippe M (site web personnel) . Évalué à 4. Dernière modification le 29 novembre 2021 à 14:12.
Nous sommes actuellement en phase de mise en prod de metabase. Lors des tests je l'ai connecté directement à la base Oracle de notre ERP… Pas une bonne idée car comme tout requêteur graphique il a tendance à taper large et du coups à générer de grosse requête.
La solution est de monter un datawarehouse qui sera synchronisé avec une ou x bases. L'avantage est choisir la périodicité de synchro et pouvoir croiser des données provenant des différentes bases, voir même d'import Office injecté par les utilisateurs dans des tables spécifiques.
Born to Kill EndUser !
[^] # Re: Redash like ?
Posté par Philippe M (site web personnel) . Évalué à 5.
A priori, la grosse différence est que Metabase propose un requêteur graphique qui ne nécessite aucunes connaissances en SQL alors que pour Redash il faut tapoter soit même ses requêtes.
Born to Kill EndUser !
# Un petit peu HS
Posté par Cyprien (site web personnel) . Évalué à 1.
Question un petit peu HS, mais pas complètement. Y aurait-il un outil un peu dans le genre de metabase qui permettrait de faire des calculs en se basant sur des évènements d'agendas ical ?
Merci !
[^] # Re: Un petit peu HS
Posté par Aeris (site web personnel) . Évalué à 5.
Si tu as une bibliothèque à disposition pour analyser les iCal et sortir les données souhaitées dans une base de données supportée par Metabase, ça fera le travail sans problème !
Avec 2 bouts de python ou de ruby, ça doit être rapide à faire.
[^] # Re: Un petit peu HS
Posté par Romain Deschamps . Évalué à 1.
C'est une question à poser directement sur le forum de Metabase (en anglais), une réponse est apportée par un membre de l'équipe de Metabase à quasiment tous les posts .
# de la balle
Posté par steph1978 . Évalué à 6.
J'avais commencé un commentaire sur les limitations du produit (il y en a) basé sur un précédente expérience. Et puis je l'ai dl et plugué sur une base PG.
Y a quand même un vrai effet waouh. Avec une vrai facilité pour découvrir la données, la filtrer, la mettre en forme, mettre ça dans un dashboard. Franchement en cinq minutes on a un rendu pro.
Les limitations donc :
pas de jointures, et si ! avec PG, ça marche, il découvre les FK.Un cas sur lequel j'ai buté : si tu veux faire un rendu entonnoir (nombre de lignes dans tel état, genre, "nouveau, en analyse, en implem, en test, à valider, fait), t'as pas le choix de l'ordre des états :(
Un outil à découvrir en tout cas, ça sera pas une perte de temps
[^] # Re: de la balle
Posté par Philippe M (site web personnel) . Évalué à 2. Dernière modification le 30 novembre 2021 à 09:37.
L'intérêt du datawarehouse est de pouvoir stocker les données comme tu souhaite les exploiter. Par exemple, depuis peu de temps Metabase propose les tableaux croisés dynamiques, pour pouvoir les exploiter correctement nous avons été obligé d'éclater la date YYYY-MM-DD par groupe. Dans le datawarehouse tous les champs date sont éclatés :
Avec cette méthode je peux faire un filtre sur credat et utiliser les credat_* pour présenter mes données par les TCD. Le tout sans aucune modification de la prod.
Born to Kill EndUser !
[^] # Re: de la balle
Posté par steph1978 . Évalué à 3.
C'est le mot que je voulais pas prononcer :)
Le pari de Metabase, c'est de permettre au quidam de tirer parti des données de son entreprise.
Si il faut mettre en place des ETL et des DWH, ça complique pas mal le sujet.
Mais j'imagine que le produit doit faire des choix entre facilité d'usage et puissance fonctionnelle. Et clairement permettre de décrire des transformations de manière "user friendly" n'est pas évident.
[^] # Re: de la balle
Posté par Philippe M (site web personnel) . Évalué à 3. Dernière modification le 30 novembre 2021 à 16:10.
J'ai tenté d'attaquer directement une base de données en prod (ERP) et même si il y a un cache, cela fait ramer la base source. J'ai rencontré ce problème avec l'utilisation de champ personnalisé et des dates. J'ai ouvert un ticket (https://github.com/metabase/metabase/issues/16533) sur ce sujet mais je pense que c'est un problème que l'on retrouvera sur tout les outils proposant des interfaces graphiques. Un peu comme à la grand époque de Dreamweaver pour la construction de site en HTML. C'était simple pour le commun de mortel mais une vrai boucherie pour le codeur qui passe derrière.
Il faut prendre en compte la volumétrie, si c'est pour faire une requête par soir sur un nombre limité d'enreg cela peut suffire ou accepter que cette requête tourne pendant 10mn alors pas de problème. Mais si c'est pour monter un tableau de bord commercial qui se rafraîchit toute les 5mn, cela devient difficilement tenable en prod.
Born to Kill EndUser !
[^] # Re: de la balle
Posté par Romain Deschamps . Évalué à 2.
Par l'intermédiaire de DB Browser for SQLite peut-être ?
[^] # Re: de la balle
Posté par steph1978 . Évalué à 3.
Peut être.
Y'a sqlite-utils aussi qui le fait.
Dans tous les cas je trouve dommage que ce soit pas natif dans le produit.
[^] # Re: de la balle
Posté par BAud (site web personnel) . Évalué à 2.
oui, l'idée de base c'est d'accéder à un fichier CSV / TSV
mais ça passe par un import au préalable, pas si compliqué d'après :
mieux vaudrait soumettre la demande upstream, ya déjà des API, pourquoi ne se connecter qu'à une base et pas un fichier tabulaire/organisé ? (rhétorique bien sûr :p)
(pour autant, ça pourrait fonctionner : créer une base tampon, lancer l'import en automatique puis la requête et zou ya la réponse). Trouver le code sur gitlab voire github est laissé à titre d'exercice. Le soumettre upstream montrerait de l'implication pour cette demande :-) (légitime àmha, je puis aider au besoin). Bon, sur la conception, yaura moyen d'améliorer, même si ça répond au besoin de base (jeu de mot, maître Capello, humour des années 80 :p)
mais bon oui, bonne demande, à faire remonter à qui de droit (et de la bonne manière)
https://www.postgresql.org/docs/current/bug-reporting.html (moui ils utilisent une ML comme en ce début de siècle o_O) et non, je n'ai pas trouvé de version en français :/
[^] # Re: de la balle
Posté par steph1978 . Évalué à 2.
La demande existe déjà.
Faîte en 2017, je suis pas pionnier :)
Et toujours ouverte, c'est pas gagné.
Mais je comprends leur difficulté : leur interface, c'est SQL (et probablement JDBC dans le monde java). Il faudrait donc mettre un moteur SQL au dessus. Et ça existe.
# Opensource as a demo
Posté par devnewton 🍺 (site web personnel) . Évalué à 4.
https://www.metabase.com/pricing/ snif :(
Ce post est offensant ? Prévenez moi sur https://linuxfr.org/board
[^] # Re: Opensource as a demo
Posté par pmdbr . Évalué à 2.
ça c'est le prix en saas (Cloud), mais si on l'héberge soi-même (On-Prem) il y a une version gratuite, qui permet déjà de faire pas mal de choses.
[^] # Re: Opensource as a demo
Posté par Romain Deschamps . Évalué à 1.
Exact !
Et la page d'accès au téléchargement des paquets open-source est celle-ci : https://www.metabase.com/start/oss/
Suivre le flux des commentaires
Note : les commentaires appartiennent à celles et ceux qui les ont postés. Nous n’en sommes pas responsables.