
Merci aux participants de cette dépêche collective, c.-à-d. ack, Adrien Dorsaz, alendroi, Anthony Jaguenaud, BAud, baud123, Bruce Le Nain, deor, etbim, fabienwang, Florent Zara, frayd, gUI, HLFH, j, jcr83, jeberger, Jiehong, Laurent Pointecouteau, lenod, M5oul, Mildred, Nicolive, nullard3d, Nÿco, olivierweb, palm123, SidStyler, SKy, tetraf, Thom, titiii, tux-tn, ver2terre, Viish, Vincent Gay, vlamy, Xinfe et Yves Bourguignon
Aujourd'hui, le net est occupé en grande partie par les services de grosses entreprises privées. Ceci pose de nombreux problèmes : logiciels privateurs, centralisation des données, pistage permanent, censure, exploration de données, dépendance à des tiers, etc.
Cette série décrit (et critique) des alternatives soit utilisables en auto-hébergement, soit via des services basés sur des logiciels libres. Dans cette première dépêche, nous allons nous intéresser aux moteurs de recherche. Les commentaires sont là pour préciser des oublis ou corriger les éventuelles erreurs.

Sommaire
- Recherche
- Vocabulaire
- Légende
- Moteurs
- Héberger son propre moteur de recherche
- Répertoires
- Conclusion
Recherche
Points d'entrée principaux sur le web, les moteurs de recherche ont un rôle stratégique majeur qui a fait la fortune de Google (*) et qui pose d'énormes problèmes de vie privée.
Malheureusement, les alternatives ont du mal à voir le jour, particulièrement les alternatives libres. Certaines alternatives non libres ont le vent en poupe en ce moment, mais il est impossible de vérifier leur prétendu meilleur respect de la vie privée.
(*) On notera que Google n'est pas dominant dans tous les pays :
- en Corée Naver a 70% de parts de marché
- en Chine Baidu a 73% de parts de marché
- en Russie Yandex a 62% de parts de marché
Vocabulaire
méta-moteur
Un méta-moteur est un moteur de recherche qui agrège le contenu de plusieurs autres moteurs.
Légende
| libre | propriétaire/privateur | décentralisé | centralisé | |||
|---|---|---|---|---|---|---|
 |
 |
 |
 |
Note : les images viennent d'Open Clipart et sont hébergées grâce à LUTIm
Moteurs
Seeks

Seeks est un moteur qui a une feuille de route1 ambitieuse. Il est à la fois un méta-moteur de recherche et un moteur pair à pair. Seeks est en effet capable de partager les résultats de la recherche dans un réseau de nœuds, pour faire de la recherche collaborative. Cette fonctionnalité est cependant en cours de développement et incomplète à l'heure qu'il est.
Seeks est aussi capable d'adapter la recherche en fonction de l'utilisateur : il affinera les réponses selon vos requêtes, sélection de résultats et navigation. Ce profil d'utilisation est stocké localement, sur votre machine.
À noter que le développeur principal n'a plus de temps à y consacrer, le projet était donc en attente de fork. C'est pourquoi @taziden avait lancé un appel sur Twitter au développement d'un successeur Python à Seeks. Asciimoo l'a finalement concrétisé ici : https://github.com/asciimoo/searx

YaCy, le moteur de recherche décentralisé, libre et sans pistage
YaCy est un moteur de recherche libre fonctionnant selon le principe de réseau pair à pair.
Contrairement à Seeks qui a commencé son développement par sa fonctionnalité de méta-moteur, Yacy est développé depuis le début comme un indexeur du web et rentre donc directement en concurrence avec Google, Bing, Yahoo!, etc. Yacy a comme avantage non seulement d'être un logiciel libre, mais également de pouvoir fonctionner soit de manière autonome (pour un Intranet, par exemple), soit en collaboration paire à paire (pour en améliorer les résultats puisque plus de ressources sont disponibles grâce à leur partage).
On notera également que Yacy est exécuté par OpenJDK7 (l'implémentation libre de Java 7) et ne dépend d'aucun serveur web ou système de base de données.
Il est possible d'utiliser Seeks/Searx et Yacy en même temps, c'est expliqué sur la wiki de Yacy.

DuckDuckGo, le moteur de recherche centralisé, non libre et sans pistage
Il s'agit d'un moteur de recherche qui a pour but de préserver la vie privée et de ne stocker aucune information personnelle concernant les utilisateurs (adresses IP et traces numériques comme la signature du navigateur). Ceci est expliqué sur le site don't track us.
Il ne répond pas aux requêtes en fonction du contexte, comme le font les moteurs de recherche les plus connus (comme expliqué sur le site don't bubble us).
Il permet aussi d'utiliser directement le moteur de recherche de son choix avec les recherches rapides (appelées recherches bang). Par exemple linuxfr !w recherche le terme LinuxFR dans le moteur de recherche de Wikipedia. LinuxFr a d'ailleurs son propre !bang : !linuxfr
Enfin, il fonctionne toujours en HTTPS et par redirection automatique, si vous venez en HTTP.
Il y a quelques polémiques autour de DDG, à titre de références voici quelques liens, les commentaires sont là pour discuter plus en profondeur :
- http://www.alexanderhanff.com/duckduckgone
- http://web.archive.org/web/20140214200727/http://173.21.64.166/photo_album/chron/desktop/opinion/2013_06_21-avoid_duck_duck_go/)
- http://etherrag.blogspot.jp/2013/07/duck-duck-go-illusion-of-privacy.html

Ixquick/Startpage, le moteur de recherche centralisé, non libre et sans pistage
Ixquick est un méta-moteur de recherche qui annonce ne pas pister les utilisateurs, ni enregistrer les adresses IP. Il utilise les moteurs de recherche de AOL, AlltheWeb, Altavista, Ask, Bing, EntireWeb, Gigablast, Google, Open Directory et Wikipédia.
La même société a créé en parallèle le moteur startpage. Il repose sur les mêmes principes mais n'utilise que Google pour donner ses réponses aux utilisateurs. C'est en quelque sorte le Google sans danger, mais ce n'est pas le moteur idéal, car il est centralisé et repose entièrement sur Google.
Comme Duckduckgo, ixquick et startpage fonctionnent toujours en HTTPS (redirection si vous venez en HTTP).

Qwant, moteur de recherche (ou agrégateur) non-libre et sans pistage
Qwant est un très récent moteur de recherche, lancé en 2013, par des Français.
Sa particularité réside dans l'affichage par catégories, lors d'une même recherche (web, actualités, media sociaux, etc.)
Il y a encore peu d'infos sur le fonctionnement de Qwant et certains le soupçonnent d'être essentiellement un méta-moteur d'autres services.
Voici un extrait de sa politique de confidentialité:
La philosophie de Qwant repose sur 2 piliers : Nous ne traçons pas nos utilisateurs, Nous ne filtrons pas le contenu d’Internet.
Nous faisons notre possible pour respecter la vie privée des internautes, tout en garantissant un environnement sécurisé et des résultats pertinents.
Il propose le HTTPS, mais ne l'active pas automatiquement. De plus, il propose un système de compte pour personnaliser ses paramètres et partager diverses choses (notes, etc.), ainsi que de se connecter à des comptes de media sociaux (ce qui soulève quelques questionnement sur la compatibilité avec la politique de confidentialité dans ce cas d'utilisation).

Héberger son propre moteur de recherche

Tuxicoman nous a parlé il y a quelques mois d'une méthode originale : réaliser son propre agrégateur de moteurs. L'intérêt ici est que vous avez une meilleure maîtrise de ce qui se passe, et vous pouvez anonymiser/supprimer les publicité/enlever les redirections de liens/etc vous même.
Le journal explique cela plus en détails. (voir également ce commentaire posté par Tuxicoman plus bas dans cette dépêche).
Répertoires
Un peu tombé en désuétude, les répertoires de recherche sont une autre façon de trouver un site, plus proche de l'annuaire : on cherche un thème et les sites correspondants sont répertoriés, souvent à la main.
dmoz (Open Directory Project)
DMOZ (pour Directory.MOZilla.org) est un projet ouvert de répertoire de sites web (Open Directory Project) qui a commencé en 1998. L'ancienne licence (Open Directory License) était considérée comme non-libre par la FSF, mais depuis 2011 dmoz a placé son contenu sous licence Creative Commons By.
Le projet qui a connu une certaine popularité au début des années 2000 fut exploité par Google jusqu'en 2011. D'autres sites continuent de l'utiliser, un des meilleurs exemples étant Alexa.
Quelques pannes techniques et la faible évolution de son interface semblent avoir découragé certains participants et utilisateurs qui se sont (re)tournés vers un moteur de recherche. Pourtant l'idée d'un répertoire de sites web classés par thèmes reste toujours valable et permet d'éviter les erreurs des moteurs. Le projet est néanmoins toujours ouvert.

Conclusion
Il est aujourd'hui possible de se passer de Google comme moteur de recherche principal, mais cela peut demander de sacrifier ses habitudes. Des moteurs alternatifs existent avec leur avantages/inconvénients respectifs, mais sans maîtrise sur les serveurs, on ne peut leur faire confiance aveuglément.
Des méta-moteurs donneront souvent de meilleurs résultats que des robots d'indexation (crawlers) maison, au prix (très élevé) d'une dépendance maintenue aux gros moteurs.
Des solutions libres existent, et fonctionnent, mais il y a encore du chemin avant d'arriver à des alternatives entièrement maîtrisées et largement utilisées.
La prochaine dépêche de la série parlera du courrier électronique. Vous êtes invités à venir participer à la rédaction collective pour partager vos connaissances sur le sujet.
-
la migration du site sur Github Pages n'a pas pris en compte tous les fichiers, il faut donc se tourner vers Archive.org. ↩
Aller plus loin
- Seeks (1074 clics)
- YaCy (2130 clics)
- Duck Duck Go (1284 clics)
- ixquick (627 clics)
- DMOZ (305 clics)
- Wikipédia : Liste de moteurs de recherche (437 clics)
- Startpage (426 clics)
- Searx, le nouveau Seeks (698 clics)
- Qwant (758 clics)
- Journal « Osez votre propre moteur de recherche ! » (699 clics)
- Sortir de facebook : enjeux et alternatives (774 clics)
# Méta-moteurs
Posté par arnaudus . Évalué à 10.
Les méta-moteurs ne sont à mon avis que des parasites. Évidemment, on peut très bien obtenir des résultats plus pertinents en croisant les données, mais 1) ça peut très bien être fait au niveau du client (la barre de recherche dans Firefox pourrait très bien interroger plusieurs moteurs et retourner une synthèse), et 2) la plupart des moteurs de recherche sont déja des méta-moteurs (cf l'histoire de Bing qui s'était fait chopper à pomper Google), et j'ai nettement l'impression qu'il n'existe qu'un seul vrai moteur de recherche autonome et performant actuellement. Du coup, en utilisant un méta-moteur officiel, on va interroger Google, plus d'autres méta-moteurs officieux, qui eux aussi recopient plus ou moins Google. Au final, on interroge Google, quoi.
Développer un nouveau moteur de recherche, c'est une perte de temps. Jamais personne n'aura les ressources pour le faire correctement, le web est trop gros, les moyens de Google sont trop importants—et surtout, Google est sacrément pertinent. On peut dire ce qu'on veut du respect de la vie privée, des pratiques commerciales, ou du don't be evil, mais Google a révolutionné le principe du moteur de recherche au début des années 2000, et personne n'a jamais réussi à lui faire de l'ombre (au moins dans le monde occidental).
L'avenir est plutôt aux moteurs de métadonnées, qui seront capables de fournir des réponses aux questions. J'ai d'ailleurs l'impression que Google s'est déja embarqué dans ce chemin, et l'interface qui intègre des éléments en provenance de Wikipédia dans la présentation des résultats d'une requête est un semblant de commencement du concept. Quand on tape "Roger Tartempion", on n'a plus seulement une collection de sites perso parlant de Roger, on a sa photo, sa date de naissance, son métier, et un résumé de ce qu'il est. Bref, si on met les considérations morales/éthiques à part, non seulement Google fournit le meilleur service actuellement, mais le moteur semble évoluer vers un web pseudo-sémantique alors que ses concurrents peinent à copier vaguement son contenu.
[^] # Re: Méta-moteurs
Posté par woprandi . Évalué à -9.
Tout à fait d'accord avec l'ensemble
[^] # Re: Méta-moteurs
Posté par arnaudus . Évalué à 10.
Peut-être n'ai-je pas insisté sur un point important : les histoires de vie privée et de pratiques commerciales hégémoniques sont un vrai problème. Mais l'argument "Adoptez un nouveau moteur ; bon, il est tout pourri, mais on est gentils" est bidon. À mon avis, il est même assez fallacieux. Si Linux est intéressant, c'est qu'il est, sur bien des aspects, supérieur à MS Windows. Si Firefox a envahi les bureaux, ce n'est pas parce qu'il est libre, c'est que c'était un logiciel de meilleure qualité qu'Internet Explorer. Jamais la liberté ou la transparence ne sera un argument convainquant aux yeux du plus grand nombre si le service rendu est médiocre.
[^] # Re: Méta-moteurs
Posté par barmic . Évalué à 10. Dernière modification le 03 juin 2014 à 16:15.
Ouai mais on s'en fou de ça. En 1991 linux c'était pas terrible alors que DOS proposait pleins de trucs, linux n'avait rien et ne tournait même pas correctement sur ta machine. De la même manière quand Wikipedia a était créé c'était un désert avec très peu de pages. Firefox c'est différent parce qu'il n'est pas développé from scratch, il vient netscape.
Bref tout ça pour dire qu'à mon avis viser directement à l'ensemble de la planète comme utilisateur ça n'a pas de sens ni d'intérêt. Rome ne s'est pas faite en un jour et aucun logiciel non plus. Il faut commencer par avoir quelque chose de pas terrible quitte à utiliser encore 70, 80 ou 95% du temps google pour pouvoir avoir un jour quelque chose qui soit utilisable.
Le problème ce n'est pas d'avoir quelque chose de parfait dès aujourd'hui, mais de résoudre des problèmes de monter en charge. Comme tu le dis cloner google demande une infrastructure totalement démesurée, mais on peut imaginer des alternatives comme l'human computing et l'utilisation de réseau paire à paire, l'infrastructure est alors répartie sur la taille de ton réseau. C'est des domaines de recherche encore peu exploré il me semble, mais tout à fait prometteur.
Au lieu d'être dans la contemplation certains essaient de construire quelque chose avec pas mal d'ingéniosité et AMHA ça peut donner des résultats intéressants, mais encore une fois personne n'imagine que jeudi google search va mettre la clef sous la porte parce que le moteur de recherche qu'il viendra de sortir est trop bien, réduire les parts de marchés de google (et ainsi réduire son hégémonie sur le segment de la recherche web) c'est déjà pas mal. Les utilisateurs n'ont pas à choisir entre un moteur et un autre, ils peuvent en changer quand ils veulent et même en utiliser différents en parallèle de manière agréable, c'est une situation idéale pour qu'une alternative puisse se positionner.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Méta-moteurs
Posté par berumuron . Évalué à 5.
Il est bidon pour ceux qui se fichent de leur vie privée ou si c'est le seul argument.
Gnu/Linux est intéressant entre autre parce qu'il est Libre.
Si Firefox a envahi les bureaux, ce n'est pas parce qu'il est Libre, mais le fait qu'il soit Libre est clairement un argument valable (principale raison pour laquelle je ne suis pas passé à Chrome ou Opera).
Mais je te rejoins sur l'idée de base : on ne conquiert pas un marché sur le seul argument "mon logiciel est Libre / mon service ne vous traque pas". L'éthique seule ne paye pas et ne sert même pas à grand chose.
[^] # Re: Méta-moteurs
Posté par PiT (site web personnel) . Évalué à 5.
Lorsque j'ai installé linux, ce n'était pas facile mais il m'apportait beaucoup de choses par rapport à Windows (3.11 for workgroups).
Aujourd'hui, j'essaie d'utiliser DDG par rapport à Google pour la seule raison de la vie privée (qui n'intéresse que les moules d'ici, le peuple s'en bat la queue). Chaque fois que je fais une recherche avec DDG et ensuite avec Google … et bien la différence entre les deux est impressionnante. Je suis de bonne volonté, j'essaie mais les résultats sont plus pertinents que DDG.
Le problème avec Google, c'est que ça marche !
L'idée de YaCy pourrait faire son chemin. Quid en terme de ressources et de pertinence ? Certains ont des retours.
[^] # Re: Méta-moteurs
Posté par Framasky (site web personnel) . Évalué à 5.
C'est marrant, moi je préfère de loin les résultats de recherche de ddg.
Being a sysadmin is easy. As easy as riding a bicycle. Except the bicycle is on fire, you’re on fire and you’re in Hell.
[^] # Re: Méta-moteurs
Posté par woprandi . Évalué à 1.
T'as des exemples pertinents ?
[^] # Re: Méta-moteurs
Posté par Framasky (site web personnel) . Évalué à 5.
Pas d'exemple précis, mais pour tout ce qui est recherche de doc de programmation (l'essentiel de mes recherches), je ai rarement besoin d'aller plus loin que le 3ème lien, sachant que c'est 50% de bonne réponses dans l'encart "réponse intelligente", 25% premier lien, 10% pour le 2ème, 10% pour le 3ème et 5% où je vais plus loin / sur google.
Being a sysadmin is easy. As easy as riding a bicycle. Except the bicycle is on fire, you’re on fire and you’re in Hell.
[^] # Re: Méta-moteurs
Posté par robin . Évalué à 2.
ddg est très fort pour les suite des caractères aléatoires tels que les messages d'erreurs ou les références de composants, je trouve. Donc dans le cas d'un problème précis en info, il lui arrive souvent d'être plus pertinent que google.
bépo powered
[^] # Re: Méta-moteurs
Posté par d_the_duke . Évalué à 3.
Ce qui a démarqué google des autres moteurs il y a 15 ans c'est le chargement rapide de la page principale, l'aspect instantané de leurs réponses (tout ceux qui surfaient avec un modem 56k et pas d'abonnement illimité me comprendront) couplé à une qualité des réponses au niveau des meilleurs concurrents.
Aujourd'hui après une phase de croissance exponentielle des contenus il serait sans doute impossible de rivaliser avec google sur la rapidité (surtout avec un moteur décentralisé), mais dans l'autre direction il y a encore beaucoup de progrès à espérer. Lorsque suffisamment d'internautes seront près à laisser tomber l'instantané pour avoir un "meilleur" service (incluant la liberté de ne pas être pisté), google n'aura plus de raison d'être ;)
[^] # Re: Méta-moteurs
Posté par SwordArMor . Évalué à 3.
Seulement, lorsque l’on voit le peu de réactions qu’ont suscitées les révélations sur PRISM, que tout le monde continue d’utiliser Google, facebook et autres, on est pas rendus avant d’avoir un public près à changer leurs habitudes.
[^] # Re: Méta-moteurs
Posté par Ovo . Évalué à 3.
"On n'est pas rendus" ne veut pas dire "c'est impossible". Par contre avec une attitude fataliste comme ça, tu freines le processus.
Les choses peuvent changer, les gens peuvent changer. C'est long, difficile et ingrât mais ça se fait. Ça se fait en étant optimiste, en agissant et en en parlant aux autres avec les bons mots (ce que je ne fais peut-être pas ici, c'est la partie la plus ardue).
[^] # Re: Méta-moteurs
Posté par Argon . Évalué à -3.
Non les gens ne changent pas et surement pas avec le dialogue.
de même que nous profitons des avantages que nous apportent les inventions d'autres, nous devrions être heureux d'avoir l'opportunité de servir les autres au moyen de nos propres inventions ;et nous devrions faire cela gratuitement et avec générosité
[^] # Re: Méta-moteurs
Posté par thoasm . Évalué à 4.
J'ai pourtant l'impression qu'on est plus à l'age de Pierre et que certaines idées ont fait leur chemin. Il y a même des gens célèbres pour avoir influencé le monde entier avec des mots !
Faut croire qu'il faut savoir s'y prendre. Ou ne pas s'attendre que des dialogues du genre "tu dois renoncer à Google, ça va rien changer à ta vie sauf qu'Internet va devenir moins pratique et peut être que la NSA n'interceptera pas le mail ou tu dis à ta soeur que tu viendras en vacances chez elle !" sont d'un quelconque intérêt.
[^] # Re: Méta-moteurs
Posté par Argon . Évalué à 1.
Oui mais ça c'était avant maintenant il y a la publicité et le mass' media et là c'est beaucoup plus difficile de lutter face à un lavage de cerveau.
de même que nous profitons des avantages que nous apportent les inventions d'autres, nous devrions être heureux d'avoir l'opportunité de servir les autres au moyen de nos propres inventions ;et nous devrions faire cela gratuitement et avec générosité
[^] # Re: Méta-moteurs
Posté par thoasm . Évalué à 10.
Avant il y avait la Tradition, l'inquisition, la propagande nationaliste et le bourrage de crâne des gosses, les Rois tout puissants, …
Aujourd'hui on a une fenêtre sur le monde, on peut faire de tour du monde pour pas trop cher en pas trop longtemps, faire ses études à l'étranger, étudier les philosophes sur Wikipédia et troller économie collaborative sur Linuxfr.
[^] # Re: Méta-moteurs
Posté par Ant . Évalué à 6.
Bah, c'est surtout qu'il n'y avait pas de vrai concurrents ! Google, ça été le premier moteur de recherche a indexer le contenu entier des pages web, quand beaucoup se contentaient encore de lire la balise "keywords", et d'avoir un moteur de recherche efficace. Les principaux concurrents c'était Yahoo!, t'avais plus de chance de trouver le site qui t'intéressait dans leur annuaire web qu'en faisant une recherche, Lycos, je crois que sa popularité était due en grande partir à sa mascotte et à la campagne de pub qui allait avec, et ask jeeves, qui était un méta-moteur mais pour le coup pouvait s'avérer intéressant.
[^] # Re: Méta-moteurs
Posté par djano . Évalué à 2.
Je me dois de te corriger un peu: Google a d'abord bâtit son index sur le nombre de liens arrivant sur une page et le texte que les gens mettaient sur les hyper liens, du coup il s'appuyait sur l'intelligence humaine pour fournir des liens pertinents. Ils ont ensuite indexes le contenu des pages elles mêmes pour construire leur fameux PageRank.
Ask Jeeves avait racheté un moteur de recherche prometteur appelé Teoma (voir wikipedia en anglais) dans lequel ils ont fait peu d'investissement et qui n'a pas connu la même trajectoire que Google.
Je me rappelle qu'avec Altavista il fallait aller voir les 30 ou 50 premiers liens retournes pour trouver un truc un peu pertinent.
[^] # Re: Méta-moteurs
Posté par Jean-Max Reymond (site web personnel) . Évalué à 1.
Milles excuses mais c'était d'abord et avant tout la pertinence des résultats. Altavista était le moins mauvais des concurrents mais complètement largué et du coup, on voyait arriver des méta-moteurs qui agrégeaient des résultats mais rien de faramineux car on était noyé avec l'ensemble des résultats. Je me rappelle être dans la Silicon Valley quand Google est apparu et plutôt dans le genre bouche à oreille. Cela avait démarré comme une trainée de poudre et quelques jours après, de retour en France, je donne le lien magique à un gars qui faisait beaucoup de recherches sur le Web. Je m'attendais à ce que dans les 5 minutes, il surgisse dans mon bureau avec la banane mais rien. Je n'y pense plus, passe la journée dans des réunions et le soir, je me rappelle de ce Google. Je vais voir la personne pour lui demander ce qu'il en pense et il me répond, dans le style fataliste: "ben, adopté immédiatement , évidemment". Dans les deux jours, tout le monde avait abandonné les Altavista, Lycos et compagnie pour passer sous Google.
[^] # Re: Méta-moteurs
Posté par Goffi (site web personnel, Mastodon) . Évalué à 7.
on a trouvé le coupable !
[^] # Re: Méta-moteurs
Posté par barmic . Évalué à 6.
Seeks avait vraiment quelque chose d'intéressant à proposer là dedans. L'objectif était d'avoir vraiment quelque chose de collaboratif. Au lieu de crawler le web, l'idée était que les sites (ou les particuliers ou des crawlers) allaient proposer leur pages. Grosso modo tu indique au réseau seeks que tel url est pertinente pour telle recherche. Là où c'était intéressant c'est que ça peut s'automatiser : tu fait une recherche sur linuxfr avec le moteur de recherche de linuxfr, une fois que tu aura cliqué sur le résultat qui t'intéresse linuxfr pourrait aller proposer ta recherche avec le résultat que tu a trouvé intéressant au réseau seeks.
Évidement le problème c'est de gérer le vandalisme, mais il y avait des pistes apparemment.
La partie métamoteur de seeks aurait pu servir à avoir une base d'utilisateurs suffisamment grande pour ensuite alimenter le réseau seeks.
C'est vraiment dommage que le projet soit perdu, il y avait de bonnes idées je pense. Je découvre avec cette dépêche un fork et j'espère qu'il a la même ambition que son prédécesseur.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Méta-moteurs
Posté par Nicolas Boulay (site web personnel) . Évalué à 2.
On peut imaginer le même genre de truc sur un proxy web installer sur une machine perso.
Le proxy suit la navigation, peut détecter les champs de recherche et les pages effectivement lu. Il peut aussi simplement marquer les pages regardées comme des pages intéressantes.
Ensuite, toutes ses données peuvent être mise en commun.
"La première sécurité est la liberté"
[^] # Re: Méta-moteurs
Posté par barmic . Évalué à 3.
Ça ne se rapproche pas de ce que fait ddg, ça ? (en moins bien peut être)
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Méta-moteurs
Posté par arnaudus . Évalué à 2.
De très loin, peut-être. Google affiche plusieurs photos (dont toutes ne viennent pas de Wikipédia), une information générale (acteur, chanteur, footballeur), qui ne vient pas de Wikipédia, d'ailleurs, puis une sorte de fiche signalétique (dates et lieu de naissance, nationalité…). Et enfin un lien vers Wikipédia. J'ai l'impression que DDG copie-colle WP et lui ajoute une feuille de style maison…
[^] # Re: Méta-moteurs
Posté par barmic . Évalué à 3.
En quoi ça pose problème que ça vienne de wikipedia ? Tu présume que la base que google utilise est de meilleure qualité ?
Tu parle de technique, mais fonctionnellement c'est proche. Google met plus d'images et propose google maps, mais au niveau du service rendu à l'utilisateur (qui se fout de savoir si c'est une bête recherche dans wikipedia ou une IA super évoluée), le concept est le même.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Méta-moteurs
Posté par arnaudus . Évalué à 2.
Ça ne pose pas de "problème". C'est juste que c'est une information sémantique qui est tirée de quelque part, peut-être d'un autre site, peut-être indirectement de Wikipédia, peut-être des requêtes Google, je ne sais pas.
En l'occurrence, oui. Wikipédia ne peut pas s'empêcher d'écrire que X est "humoriste, chansonnier, et écrivain", ou que Y est "acteur et réalisateur", même si une des facettes est totalement anecdotique.
Mouais, pas sûr. DDG met Wikipédia en première réponse et développe le contenu de l'article sur un court paragraphe. Je dirais, "bêtement", tel quel. Google va chercher des informations clés, qu'il présente selon ses critères, en l'agrémentant d'informations qu'il va chercher ailleurs. Je trouve que dans le principe, justement, c'est très différent, même si au niveau visuel, ça pourrait être proche.
[^] # Re: Méta-moteurs
Posté par SF . Évalué à 2.
La différence pour moi c'est que google tente de répondre à la question posée là où ddg propose des liens vers des sites qui peut être proposeront la réponse. Donner le début d'une fiche wikipedia et espérer qu'elle contienne l'info n'est pas la même chose que renvoyer l'info demandée.
Si je demande l'age d'une personne connue à google j'ai une réponse précise. Si je demande l'age de quelqu'un à ddg j'ai le début de la fiche wikipedia ou une information plus ou moins précise venant d'un autre site, donc au choix la vie du mec, sa date de naissance ou son age si j'ai de la chance.
[^] # Re: Méta-moteurs
Posté par Francafrique . Évalué à 3.
une recherche avec age de britney spears
avec google je sais qu'elle a 32 ans.
avec ddg je sais qu'elle a 32 ans 6 mois et un jour (Assuming britney spears is a person…)
par contre avec google j'ai la date de naissance alors qu'avec ddg non…
[^] # Re: Méta-moteurs
Posté par SF . Évalué à 1.
Sur ddg la réponse varie grandement en fonction de la personne recherchée.
Après il me semble qu'avec le projet wikidata notamment (si j'ai compris l'objet du projet) il y aura peut être des opportunités pour avoir des réponses plus cohérentes.
Après Google sait répondre à tout un tas de recherches sur les spectacles, les loisirs, transports etc. Et là je ne sais pas trop où un concurrent libre pourrait obtenir l'info.
Pour se faire une idée de ce que Google peut proposer il faut tester via Android qui répond plus souvent encore aux questions (horaires film salle par exemple) que Google.fr
[^] # Re: Méta-moteurs
Posté par Francafrique . Évalué à 0.
Sur ddg je pense que le "À propos" vient de WP, l'onglet "photos" de google, l'onglet "videos" aussi et l'onglet "audio" de soundcloud :
https://duckduckgo.com/?q=die+antwoord
L'onglet Significations a l'air de venir aussi de WP :
https://duckduckgo.com/?q=cape+town
l'ensemble fait qd meme une information assez complete. Par contre, le manque d'infos geographiques et contacts est un moins par rapport à google. mais bon ddg evolue vite.
[^] # Re: Méta-moteurs
Posté par Adrien . Évalué à 6.
Je pige pas trop tes arguments :
– google est tellement bien que le mieux… est de ne rien faire pour le concurrencer. (« Développer un nouveau moteur de recherche, c'est une perte de temps. Jamais personne n'aura les ressources pour le faire correctement »)
– la vie privée… de toute façon ça sert à rien de lutter, on a perdu.
Si ce sont vraiment tes arguments… tu bosses chez Google ?
[^] # Re: Méta-moteurs
Posté par flagos . Évalué à 3.
Pour moi, ses arguments c'est: Ne perdez pas votre temps a essayer de concurrencer Google sur la recherche pure, ca fait tellement d'années que des tas de gens essaient sans succès que ca ne doit pas etre facile. Par contre, essayez plutot de prendre la prochaine tendance a savoir l'utilisation des metadonnées ou du pseudo-sémantique (chacun met ce qu'il veut dans ce genre de notions fourre-tout) pour mettre la nique a Google.
Bref, attendre la prochaine vague plutot que pagayer dans le vide.
[^] # Re: Méta-moteurs
Posté par devnewton 🍺 (site web personnel) . Évalué à 10.
Je trouve que Google est de moins en moins pertinent pour toutes les recherches "non commerciales". Les entreprises qui cherchent à vendre des produits ou des services font tellement de SEO qu'elles masquent les autres sites.
Ce post est offensant ? Prévenez moi sur https://linuxfr.org/board
[^] # Re: Méta-moteurs
Posté par arnaudus . Évalué à 1.
Absolument pas. Je dis que ça ne sert à rien d'essayer de le copier. Le problème est très simple : très peu de gens aujourd'hui seraient capables de financer, s'ils le voulaient, une infrastructure qui ne ferait qu'indexer les nouvelles pages web. Je ne parle même pas des serveurs de base de données pour traiter les requêtes, rien que l'indexation. On peut même oublier les serveurs, tiens. Juste la bande passante. Rien que ça, aucun projet libre ne pourrait le faire. Résultat, ton moteur n'est même pas encore en ligne que son contenu est déja obsolète. Tu es condamné à offrir un service effroyablement inférieur à celui de Google. Tu peux essayer si tu veux, on vit dans un pays libre, mais c'est un acte de déséquilibré.
J'ai déja dit des trucs comme ça dans d'autres posts, mais certainement pas ici. Justement, je dis que c'est un problème important, mais qu'il est totalement puéril de penser qu'offrir des outils merdiques puisse contribuer à le résoudre. Et si c'est pour créer une interface graphique qui interroge Google en arrière-plan, comme le font plusieurs des moteurs listés dans la dépèche, je pense qu'il existe beaucoup de trucs plus importants à faire.
Mon portefeuille aimerait probablement bien :-) C'est vrai qu'à force des trolls sur Microsoft et Apple, on pourrait finir par croire que toutes les boites en informatique ne font que de la merde, mais c'est faux. Google fait à la fois des trucs bien et des trucs pas bien. Et ça serait débile de ne pas reconnaitre que c'est leur capacité d'innovation et d'investissement dans leur moteur de recherche qui les maintient en position quasiment hégémonique sur ce marché. Être tout fier d'utiliser DDG en faisant semblant de ne pas savoir que ça ne fait qu'interroger Google derrière en modifiant marginalement l'order des retours, je ne vois pas l'intérêt.
[^] # Re: Méta-moteurs
Posté par Francafrique . Évalué à -1.
Mouais c un peu comme dire : etre tout fier d'utiliser firefox en faisant semblant d'ignorer que c google qui finance la fondation, je ne vois pas l'interet…
en plus pour le coup, il me semble que c plutot bing qui est utilisé par ddg mais bon l'idee est la meme.
Perso je n'utilise pas ddg par fierté, c'est surtout pour les fonctionnalités !bang (c vraiment trop puissant ce truc) et puis un peu pour la vie privée (meme si ce point est sujet à caution…).
[^] # Re: Méta-moteurs
Posté par Adrien . Évalué à 2.
OK, on est d'accord : copier Google, faut les reins solides, mais offrir une alternative, pourquoi pas. D'ailleurs dans le lot il me semble que c'était le but de seeks, avec une approche différente de Google : avoir un réseau de nœuds qui aggrège des info sur certains points d'intérêts, et qui peuvent communiquer entre eux pour avoir des choses les plus pertinentes possibles.
Enfin aujourd'hui on pourrait avoir des organisations assez puissantes qui pourraient se lancer dans l'aventure, avec les révélations de Snowden, avec des moyens conséquents. Par exemple la France, ou l'Union Européenne (oui, je rêve souvent, mais c'est comme ça)
[^] # Re: Méta-moteurs
Posté par sGendrot . Évalué à 0.
Je suis entièrement d'accord avec arnaudus, je me rappelle de ma première utilisation de Google (c'était en 2001/2002), c'était magique, il trouvait des pages en lien avec ma recherche. Bien que si je devais revenir sur d'autre moteur car Google ne trouvait pas tout, je passais d'abord par Google.
Mais je n'ai jamais ré-eu cet effet magique avec d'autres moteur de recherche, par exemple:
prenez un code erreur Windows, faites une recherche sur Bing, vous trouvez rien d'utile (le comble). Sur Google, vous trouvez les pages MSDN (site Microsoft) du problème.
Il ya certes l'indexation du web, mais il ya surtout l'algo de Google qui fait très mal à ces concurrents. Essayer d'attaquer Google sur le moteur de recherche c'est comme vouloir concurrencer Mercedes sur les voitures… en face ya du lourd.
Par contre, ce qui me gêne vraiment c'est trouver un hébergeur mail aussi bon que Gmail (notamment sur les appli Android), c'est de pouvoir utiliser OpenStreetMap au lieu de GoogleMaps, c'est d'avoir une bibliothèque libre d'ebooks de qualité, etc …
(si la NSA apprend que j'ai fait des recherches sur Python, je m'en tape un peu. Par contre, qu'ils aient accès à tous mes mails, ça me gêne vraiment)
Il ya beaucoup d'autres domaines ou Google n'est pas très fort où des projets libres peuvent être une alternative de meilleure qualité.
[^] # Re: Méta-moteurs
Posté par 🚲 Tanguy Ortolo (site web personnel) . Évalué à 4.
Euh, que veux-tu dire par là ? Android n'est pas fourni avec un logiciel de messagerie générique, il faut installer un logiciel spécifique au fournisseur de courrier ‽
[^] # Re: Méta-moteurs
Posté par sGendrot . Évalué à 2.
(quand je parle de mail, j'inclus aussi les contacts)
(ayant un Samsung, je peux difficilement parler des autres marques)
Oui, Samsung fournit une appli mail par défaut qui est naze. Je fait donc
ma ménagèremon utilisateur de moins de 50ans, je prend l'appli de mon fournisseur de mail. Et là Google enfonce le clou, l'appli Gmail fonctionne très bien.Si je veux passer à Yahoo (pour rester dans le mainstream), la synchro avec des contacts merde sous Android et te pourrit tes contacts…. ça donne envie.
On en revient au même, pourquoi Apple est majoritaire, par ce que ça marche facilement. Pourquoi Google prend le reste du marché, car ça marche facilement.
[^] # Re: Méta-moteurs
Posté par 🚲 Tanguy Ortolo (site web personnel) . Évalué à 8.
Dans ce cas, le plus pertinent serait plutôt de trouver un logiciel de messagerie générique performant. Utiliser des logiciels spécifiques, limités au service d'un fournisseur particulier, c'est évidemment le meilleur moyen d'ajouter sans raison une dépendance forte à ce fournisseur.
[^] # Re: Méta-moteurs
Posté par sGendrot . Évalué à 0.
Tout à fait, mais la très grande majorité des utilisateurs ne va pas le faire.
Mais même si je change d'appli Android, mes mails restent chez Google … on tourne au tour du pot.
Et qu'on ne me parle pas de l'auto-hébergé, je ne me vois pas héberger les boites mails de tous mes amis dessus (j'ai pas envie de me brouiller avec eux car j'ai crashé le serveur).
Du coup, quand on vient me voir pour changer d'hébergeur mail à cause de la NSA et etc … je réponds quoi ?? Yahoo ?? Microsoft ??
Je n'ai pas de réponses libres à cette question et c'est ça me soûle.
Donc voir l'argent/énergie consacrer à des moteurs de recherche, je me dis qu'on pourrait faire mieux sur d'autres sujets.
Ps: j'ai parlé des mails, mais je peux parler du stockage (Dropbox), l'agenda, les contacts, etc …
[^] # Re: Méta-moteurs
Posté par Goffi (site web personnel, Mastodon) . Évalué à 3.
le rôle des associations est sous-estimé. Par exemple j'ai été en contact avec Nanterrux (j'avais invité à faire une conf avec eux): ils font ce genre de choses: gestion de serveurs, des sauvegardes, support humain (c.-à-d. à proximité, et sans suivre un questionnaire pré-établi ou prendre les gens pour des cons), rencontres conviviales etc.
Pour les courriels j'ai conseillé mailoo a plusieurs amis qui en sont très contents (et qui sont prêts à donner quelques euros de temps en temps pour ça). Enfin on y reviendra dans la prochaine dépêche de toute façon.
Un serveur c'est pas forcément « celui qui s'y connaît » dans la famille, ça a bien plus de sens si c'est des associations. Ça peut poser d'autres problèmes (quelqu'un qu'on connaît aura plus intérêt à lire nos courriels), mais il y a des solutions techniques (chiffrement), et surtout un truc qu'on perd pas mal: la confiance.
Bref, il faudrait augmenter le nombre d'associations, et qu'elles collaborent facilement entre elles. Quand je vois les réseaux de distribution impressionnant qui s'organisent avec les AMAP par exemple, je me dis que dans l'info c'est tout à fait faisable. Je pense aussi qu'il faudrait beaucoup de petites assoces qui collaborent, plutôt qu'un énorme truc au niveau national.
[^] # Re: Méta-moteurs
Posté par barmic . Évalué à 0.
Tu me fais rêver. Pour un problème de sécurité, ta préconisation c'est la confiance ?
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Méta-moteurs
Posté par Goffi (site web personnel, Mastodon) . Évalué à 4. Dernière modification le 05 juin 2014 à 16:24.
Tu lis à moitié. Je dis qu'il y a des solutions techniques, mais elles sont (et seront probablement toujours) insuffisantes. Et oui la confiance joue un rôle en sécurité: je n'ai aucun problème à laisser mes clefs à ma famille ou mes amis, voire parfois (assez souvent en fait) à des inconnus, et pourtant ils pourraient s'en servir pour fouiller dans ma vie très facilement. À côté de ça, j'ai un gros problème à laisser des messages dans les mains de Google ou FB.
Pour faire simple: j'ai clairement plus confiance en une association, surtout si je connais les gens, qu'en de grosses entreprises avec des milliers d'employés (et souvent des pratiques qu'on sait douteuses).
[^] # Re: Méta-moteurs
Posté par barmic . Évalué à 2.
Non, la confiance (et c'est comme ça que tu le décris) c'est quand tu te permet de réduire ta sécurité. Pleins de gens ont confiance en Google, tu pense que c'est de la sécurité ? Pleins de gens sont curieux et aiment les potins leur laisser lire tes mails c'est de la sécurité ? Mettre mon mot de passe sur un port-it à coté du clavier parce que j'ai confiance en mes collègues de boulots c'est de la confiance ?
Clairement pas. C'est peut être suffisant chacun met le curseur de sécurité là où il le souhaite, mais ça n'est pas ce que l'on appel communément de la sécurité (après tu peut te faire ta définition, hein).
Là où tu as de la sécurité c'est quand tu es en mesure d'auditer, de vérifier, de contrôler,… et donc que tu as une transparence sur ce qui est fait de tes données. C'est en ça que le pote ou l'association peut se révéler meilleur en terme de sécurité.
La confiance c'est ce que te vendent les marketeux pour te faire manger du cheval payé au prix du bœuf.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Méta-moteurs
Posté par Goffi (site web personnel, Mastodon) . Évalué à 5.
Euh non, la confiance est également utilisée en chiffrement: les autorités de certification par exemple, ou le web of trust qui est utilisé par PGP.
Qui parle de laisse lire les courriels ? Je te dis justement que ça joue un rôle parce que j'ai bien plus confiance en mes amis pour ne pas lire les courriel qu'en Google (que je sais le faire). Je sais à qui je peux laisser mon portable sans risque qu'il lise mes messages. Le chiffrement c'est la serrure, la confiance c'est d'estimer que la personne va tenter de la crocheter ou pas.
Non, ça c'est juste tendre le bâton pour se faire battre. Laisser un post-it aux yeux de tous c'est un problème qui n'a rien à voir avec la confiance.
Encore une fois tu as lu à moitié, qui parle de suffisant ?
Je n'ai jamais dit qu'il ne fallait pas faire ça si on en avait la possibilité (physique et technique).
Tu cite justement ce en quoi je n'ai pas confiance. Si un jour le maraîcher de mon AMAP me vend de fausses tomates cœur de bœuf, ma confiance sera trahie.
[^] # Re: Méta-moteurs
Posté par barmic . Évalué à 2.
Oui des organismes qui sont audités, des clefs qui sont vérifiées par induction.
En principe on considère que ce qui peut être fais à ton encontre est ou sera fait.
Justement tu parle de quelque chose d'exêtrement subjectif. La sécurité n'a pas à être subjective.
La sécurité par principe c'est se prémunir contre la trahison.
Comprends bien je ne dis pas qu'on a pas à faire confiance, juste que ça n'est pas de la sécurité.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Méta-moteurs
Posté par ariasuni . Évalué à 8.
K9-mail?
Écrit en Bépo selon l’orthographe de 1990
# Et pour les utilisateurs il y a quoi ?
Posté par Khaos . Évalué à 8. Dernière modification le 03 juin 2014 à 16:45.
J'ai un petit souci avec cette liste, c'est qu'elle inclut des outils qui ne sont pas pensés pour les utilisateurs.
Exemple concret : J'utilise StartPage et j'aimerais passer à un truc plus sympa philosophiquement du style décentralisé.
Je regarde la liste et je me dis "Bon Seeks d'après la description c'est semi-mort et YaCy a l'air sympa… ok testons YaCy"
Donc je vais sur le site de YaCy. On m'y explique à nouveau tous les merveilleux concepts, qui sont effectivement sympa, je lis dans un coin que "YaCy est très facile à installer et facile à utiliser." et qu'il suffit d'avoir OpenJDK.
Youpi. Je clique donc sur l'onglet Tutoriel, pour savoir comment on installe et utilise ce truc et… Ooooh trois exposés vidéo (dont 1 de presque une heure) qui présente à nouveau les concepts. SUPAYR !!
Moi je voulais un tuto, je voulais remplacer StartPage par YaCy… Je fais comment ? Je demande à Google ?
Bref les concepts, la philosophie et les screenshots c'est bien, un tuto d'install ce serait mieux.
[^] # Re: Et pour les utilisateurs il y a quoi ?
Posté par Adrien . Évalué à 2.
Au stade où en sont les projets, les utilisateurs sont invités à contribuer pour améliorer les choses… malheureusement.
[^] # Re: Et pour les utilisateurs il y a quoi ?
Posté par Khaos . Évalué à 2.
Disons qu'ils auraient pu mettre le package de base (comment installer/utiliser)… Bon je suis mauvaise langue, l'info est dans le wiki (et donc pas sur la page tutoriel, on se demande pourquoi), mais faire 15 pages expliquant le concept et à peine une expliquant l'install c'est pas super encourageant pour l'utilisateur moyen. (Qui, soyons honnête, n'ira pas la chercher la page wiki en question)
Même moi qui ne suis pas un utilisateur "michu", je passe de "tiens c'est une bonne idée, j’arrête google maintenant tout de suite" à "Bon en fait faut que je me trouve un peu temps pour étudier tout ça, j'ai pas le temps, je le ferais un autre jour".
Par rapport au titre de la dépêche, je suis un peu déçu du coup.
[^] # Re: Et pour les utilisateurs il y a quoi ?
Posté par Franck Routier (Mastodon) . Évalué à 3.
http://www.yacy-websuche.de/wiki/index.php/Fr:DebianInstall
Ceci dit, une fois installé, l'administration est assez lourde, les réglages de perf pas triviaux (quel -Xmx,, en fonction de quelle charge, etc…). Bref, j'avais essayé de mettre en place un noeud Yacy sur un serveur dédié (Kimsufi à 10€ par mois), il a tourné quelques temps, mais il finissait toujours à la ramasse avec mémoire et CPU saturés… ça reste un peu touchy.
[^] # Re: Et pour les utilisateurs il y a quoi ?
Posté par ariasuni . Évalué à 7.
Et ça donnait des résultats pertinents?
Écrit en Bépo selon l’orthographe de 1990
[^] # Re: Et pour les utilisateurs il y a quoi ?
Posté par dzecniv . Évalué à 2. Dernière modification le 03 juin 2014 à 21:51.
Après avoir indexé quelques nouveaux sites pendant 15-20 minutes, on voit très clairement que les recherches sur les mots-clefs liés sont plus pertinentes.
J'ai essayé un coup sur mon pc (facile, il suffit d'installer un paquet debian), et c'est grisant de choisir les sites à indexer et de voir le nombre augmenter.
C'est la piste que j'aimerais également explorer: installer Yacy sur un raspberry-pi-like en moins de 2 grâce à Yunohost et le laisser crawler gentiment. Peux-tu préciser ce que ça donnait chez toi ?
Pour l'heure Yacy n'est pas trop utilisable pour des recherches, notamment parceque pas assez de monde ne participe à l'indexation et on ne peut pas choisir la langue de recherche (cf https://sortirdefacebook.wordpress.com/#sec-5-5-4)
[^] # Re: Et pour les utilisateurs il y a quoi ?
Posté par Franck Routier (Mastodon) . Évalué à 2.
De mon côté, j'ai laissé le serveur tourner quelques semaines, mais il devenait régulièrement instable/surchargé et il fallait redémarrer yacy.
Quant aux résultats, ils étaient médiocres, mais je ne m'attendais pas à des miracles. Ça ne peut marcher que si de nombreux noeuds sont créés et contribuent, ce qui n'est pas le cas pour l'instant.
[^] # Re: Et pour les utilisateurs il y a quoi ?
Posté par Damien Clauzel (site web personnel) . Évalué à 1.
Pour jouer avec YaCy, il y a le nœud de démo. L'interface d'administration n'est pas accessible, en revanche.
YaCy s'installe et fonctionne sur Debian sans rien avoir à configurer sur la machine (juste 3 réglages à choisir au premier lancement de YaCy, dans l'interface web). Par contre, il faudra le laisse tourner un peu avant de pouvoir l'utiliser, afin qu'il se synchronise au réseau et commence à remplir son index.
Je fais tourner un nœud sur mon serveur, principalement pour lui faire indexer des blogs d'auteurs que j'aime bien, des wikis de références, et des bases documentaires : ça me permet de faire facilement des recherches ciblées sur des ressources pertinentes, tout en élargissant avec les index du reste du réseau.
# Voila!
Posté par djano . Évalué à 3.
http://web.archive.org/web/20140214200727/http://173.21.64.166/photo_album/chron/desktop/opinion/2013_06_21-avoid_duck_duck_go/
[^] # Re: Voila!
Posté par claudex . Évalué à 3.
Merci, j'avais essayé de trouvé sur archive.org mais quand je suis tombé dessus, il m'a dit que la page n'était pas archivée dans archive.org (de manière général, j'ai souvent beaucoup de mal à tomber sur un résultat avec archive.org, mais c'est peut-être moi qui ne suis pas doué).
« Rappelez-vous toujours que si la Gestapo avait les moyens de vous faire parler, les politiciens ont, eux, les moyens de vous faire taire. » Coluche
# emails, calendrier, contacts, données
Posté par polytan . Évalué à 7. Dernière modification le 03 juin 2014 à 19:30.
J'essaie aussi de me "libérer" de google et consort.
Là je loue un nom de domaine avec un petit VPS et une Debian dessus.
Sans grande notion d'informatique je viens de finir d'installer :
- Postfix, dovecot et consort
- nginx
- phpMyAdmin
- postfixadmin
- roundcube
- ownCloud
Et avec tout ça, on couvre déjà une grande partie des besoins !
C'est vrai que j'en ai marre d'avoir mes contacts, emails, calendrier et données dans le "cloud" chez des gens que je ne connais pas.
Et tout fonctionne en SSL, que ça soit depuis le PC ou le mobile (BB10 en l'occurrence).
Il me reste à chiffrer les données sur le VPS pour que la boucle soit bouclée !
Et une fois que tout cela sera fait, on passera peut être à un dédié ?
Je pense qu'il faut passer l'étape du tout gratuit et comprendre que si on veut préserver sa vie privée, à un moment où un autre cela coûte un peu d'argent. (J'en suis à 3€ par mois, mais 10Go de stockage sur le VPS OVH ça fait léger, j'attends de trouver mieux)
Le tuto principal que j'ai suivi et adapté est le suivant :
http://www.xenlens.com/debian-wheezy-mail-server-postfix-dovecot-sasl-mysql-postfixadmin-roundcube-spamassassin-clamav-greylist-nginx-php5/#comment-3560
[^] # Re: emails, calendrier, contacts, données
Posté par claudex . Évalué à 4.
Je ne vois pas l'intérêt du dédié (mise à part pour une question de coût mais ce n'est pas inhérent au dédié).
« Rappelez-vous toujours que si la Gestapo avait les moyens de vous faire parler, les politiciens ont, eux, les moyens de vous faire taire. » Coluche
[^] # Re: emails, calendrier, contacts, données
Posté par gnx . Évalué à 1.
L'espace de stockage, comme il le dit, qui est toujours faiblard dans les offres VPS.
[^] # Re: emails, calendrier, contacts, données
Posté par polytan . Évalué à 2.
Oui c'est pour le stokage que je disais ça.
Cependant, d'un point de vue "écolo", je préfère le mutualisé. Après, si je trouve une config sympa en mutualisé avec un bon niveau de stockahe (entre 250 et 500Go par exemple) et les données sur du raid (ou similaire) pour garantir le stockage, je ne dirai pas non.
[^] # Re: emails, calendrier, contacts, données
Posté par claudex . Évalué à 3.
http://www.firstheberg.com/virtual-private-server a l'air intéressant et parle de deux serveurs de fichiers pour chaque VM.
« Rappelez-vous toujours que si la Gestapo avait les moyens de vous faire parler, les politiciens ont, eux, les moyens de vous faire taire. » Coluche
[^] # Re: emails, calendrier, contacts, données
Posté par Nÿco (site web personnel) . Évalué à 5.
C'est le sujet du prochain article, à bâtir… http://linuxfr.org/redaction/news/se-passer-de-google-facebook-et-autres-big-brothers-2-0-2-le-courriel
[^] # Re: emails, calendrier, contacts, données
Posté par Franck Routier (Mastodon) . Évalué à 2.
A ce sujet, voir cet article, un peu désespérant, mais éclairant: http://www.slate.fr/life/87045/gmail-google-emails-prive
[^] # Re: emails, calendrier, contacts, données
Posté par Franck Routier (Mastodon) . Évalué à 1.
Et peut-être ce projet ? https://kinko.me/
# Un autre moyen de se passer de google...
Posté par bolikahult . Évalué à 10.
…est peut-être de moins utiliser les moteurs de recherche.
Nous sommes tous capable d'écrire en toute lettre une url, ou de gérer des favoris.
Or, très souvent, google est utilisé pour aller sur un site dont on a l'url exacte !
En réfléchissant 1 secondes, on peut aller directement à la source…
[^] # Re: Un autre moyen de se passer de google...
Posté par claudex . Évalué à 5.
Très souvent j'utilise Google pour chercher une URL pour que je ne connais pas. Que ce soit le site web officiel d'un projet (même si j'utilise parfois Wikipédia pour ça, en fonction des projets, je trouve ça plus pratique), une page particulière d'un site (j'ai retrouvé aujourd'hui l'url que je recherchais depuis quelques temps sur un site que je connais assez bien https://linuxfr.org/news/c-etait-mieux-avant#comment-1441595 ), ou un site que je ne connais pas mais dont la navigation est mal foutue.
Au final, j'utilise beaucoup la barre d'url de firefox pour plein de projets mais j'utilise aussi beaucoup google. Et je ne suis pas sûr que je pourrais m'en passer de manière plus importante sans perdre beaucoup en productivité.
« Rappelez-vous toujours que si la Gestapo avait les moyens de vous faire parler, les politiciens ont, eux, les moyens de vous faire taire. » Coluche
[^] # Re: Un autre moyen de se passer de google...
Posté par PiT (site web personnel) . Évalué à 3.
À nouveau, c'est plus facile de pisser dans un violon. Seules les moules vont entrer une url dans la barre idoine et les autres feront une recherche.
Si je tape example.org, je tombe sur le site … et si je tape "example org", "examlpe org", … aussi. Alors pourquoi l'utilisateur s'encombrerait d'essayer de taper un point. Il ne se soucie pas de la recherche qui est faite ni d'un éventuel clic supplémentaire à faire pour accéder à la page.
je ne dis pas qu'il ne faut pas lutter hein ! Il faut choisis ses combat. Après l'avoir répéter pendant plusieurs mois à mes étudiants, j'ai tendance à abandonner ;-)
[^] # Re: Un autre moyen de se passer de google...
Posté par arnaudus . Évalué à 9.
En fait, les moteurs de recherche remplacent une fonctionalité manquante du protocole DNS : la tolérance aux erreurs. Tu oublies le www, tu tapes example,com ou exemple.com, et hop, horrible page d'erreur. C'est acceptable pour une ip ou un numéro de téléphone, qui ne sont pas signifiants, mais c'est inacceptable avec du signifiant en langage naturel, puisque le langage naturel est assz tolérannt au éreurs (havèque dé limes hittes).
Les arguments du type "les utilisateurs sont cons", ça va deux secondes, mais pour cette question particulière, je pense que c'est faux. Pour le coup, les ingénieurs sont cons. Si tu crées un système qui renvoie une erreur obscure quand tu tapes wikipdia.org, ou pire, qui t'envoie potentiellement sur un site de phishing ; quand tu mets à jour le système et que la seule "amélioration" que tu trouves, c'est d'offir encore plus de possibilités de confusion (en autorisant l'unicode ou en créant une profusion de TLS), alors tu crées une "niche écologique" pour un service entre l'utilisateur et le DNS, qui filtre les fautes et renvoie le bon site.
Après, tu peux prétendre qu'à cause de Google, il risque d'être de plus en plus difficile d'acheter du viagra chinois sur www.wikpedia.com. Certes. Il pourrait même exister des gens qui pourraient penser que c'est une bonne chose. Ceux qui n'arrivent pas à comprendre pourquoi devraient peut-être, de temps en temps, se renseigner sur ce qu'Internet est devenu au cours des 10 dernières années…
[^] # Re: Un autre moyen de se passer de google...
Posté par arnaudus . Évalué à 5.
(c'est amusant, www.wikpedia.com, que j'avais tapé au pif, existe vraiment, et renvoie aléatoirement vers des attrappes couillon (voyance, trucs pornos, applis pour smartphones, etc). Coup de bol, mais ça appuie bien le raisonnement :-) ).
[^] # Re: Un autre moyen de se passer de google...
Posté par 🚲 Tanguy Ortolo (site web personnel) . Évalué à 10. Dernière modification le 04 juin 2014 à 11:01.
Mauvais exemple, Wikipédia, parce que c'est typiquement le site Web où tu vas une première fois, soit en tapant l'URL exacte, soit par un moteur de recherche, puis où tu retournes très probablement assez souvent pour qu'il ne sorte jamais de l'historique. Par conséquent, exception faite de la première visite, ni l'URL exacte, ni le moteur de recherche ne sont nécessaires : les fonctionnalités de la barre d'adresse du navigateur, qui propose tout seul la bonne adresse dès qu'on commence à saisir le nom du site, suffisent.
Ceci est d'ailleurs valable pour tous les sites que l'utilisateur visite fréquemment, et pour le reste, il est assez rare qu'on se rende sur un site Web à partir de sa mémoire, l'essentiel de la navigation s'effectuant en suivant des liens hypertextes.
Par ailleurs, Wikipédia étant avant tout une encyclopédie, son usage principal passe lui-même par une fonction de recherche, et son usage le plus approprié passe par un plugin de recherche pour le navigateur lui-même.
[^] # Re: Un autre moyen de se passer de google...
Posté par CrEv (site web personnel) . Évalué à 5.
Pas forcément non.
Tu as deux façons de voir les choses. Soit tu te dis "je vais aller chercher dans une encyclopédie" et dans ce cas oui tu vas chercher volontairement dans wikipedia, soit tu te dis "je cherche des informations sur…" et tu passes par Google (ou autre) qui, si cela est pertinent, te présentera les résultats de cet encyclopédie mais aussi potentiellement d'autres résultats.
Et mon avis est que dans beaucoup de cas on est plutôt dans le deuxième, le but n'est pas de chercher dans wikipedia mais de répondre à une question qu'on se pose.
[^] # Re: Un autre moyen de se passer de google...
Posté par 🚲 Tanguy Ortolo (site web personnel) . Évalué à 6.
Certes, mais ce second cas est précisément le cas normal d'usage d'un moteur de recherche générique, et un cas où on ne cherche pas spécifiquement le site Web Wikipédia. Bref, ce n'est pas un cas de détournement de moteur de recherche générique à la place de la barre d'adresse du navigateur, qui était ce qu'on critiquait plus haut.
# Searx
Posté par Reventlov . Évalué à 4. Dernière modification le 03 juin 2014 à 21:39.
J'utilise personnellement Searx qui est un méta-moteur, présenté rapidement dans cet article. Il me sert simplement à faire passer mes requêtes par mon serveur, c'est un intermédiaire. Il est possible d'utiliser plein de moteurs avec Searx mais je n'utilise que Google, les autres étant globalement pourris au niveau des résultats qu'ils proposent.
Du coup, j'essaye de ramener des gens pour l'utiliser, histoire de « camoufler » mes requêtes et les requêtes de différents utilisateurs dans la masse des autres requêtes. À noter que Searx n'est pas le « nouveau Seeks » puisque qu'il ne s'agit que d'un méta-moteur, et qu'il n'a aucun but d'inter-connexion pour l'instant, même si il a été inspiré par Seeks.
Du coup, je rappelle la page qui liste les instances publiques de Searx: https://github.com/asciimoo/searx/wiki/Searx-instances
Si ça vous parait lent, vous pouvez désactiver certain des 15 moteurs de recherche qui sont cochés dans la page de préférences.
[^] # Re: Searx
Posté par Gastlag . Évalué à 2. Dernière modification le 04 juin 2014 à 08:42.
Entre le "aucun but" et le "pour l'instant" j'avoue ne pas trop comprendre. Si Searx vise juste à être un métamoteur, il me semble ça ne sert pas à grand chose vu que c'est justement la partie de Seeks qui existe déjà.
De même tout l'intérêt de Seeks était de mettre en place un réseau distribué de résultats de recherche, groupés par groupes d'intérêts et communautés et de reléguer la difficile question de l'indexation du web et de l'Internet à plus tard ou à d'autres personnes… Du coup…?
Par contre le "pour l'instant" laisse penser que ça pourrait être développé dans le futur. Pourquoi ne pas en faire un objectif dès maintenant afin de mobiliser pas mal de monde ?
[^] # Re: Searx
Posté par Reventlov . Évalué à 2.
Mon « pour l'instant » est mal choisi. Searx n'a aucun but d'inter-connexion affiché actuellement. Ça peut peut être changer dans le futur, je n'en sais rien.
Searx est actuellement un « simple » métamoteur, qui possède tout de même un intérêt majeur par rapport à Seeks: il est maintenu et actif.
Notons que Seeks n'a pas subi de changement majeur depuis 2 ou 3 ans, et que dans l'état, il me semble que l'interconnexion n'est pas du tout utilisable. Voir https://github.com/beniz/seeks pour l'activité sur le projet.
# MySearch
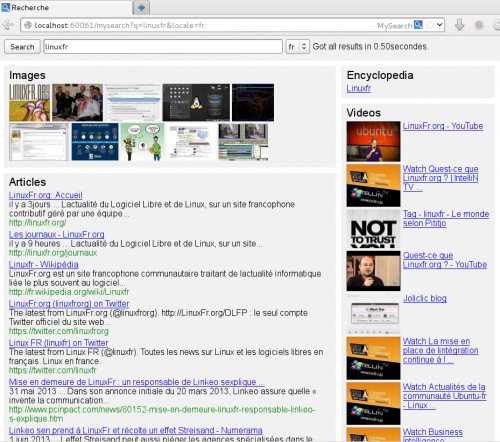
Posté par tuxicoman (site web personnel, Mastodon) . Évalué à 10.
Je suis sur le point de publier une nouvelle version décentralisée.
Le scénario se déroule ainsi : Vous avez installé Mysearch en local sur votre machine. Lorsque vous faites une recherche dessus, Mysearch va interroger une source (Google par exemple) par une connexion chiffrée par SSL. Cette connexion SSL va passer par d'autres noeuds Mysearch (relai uniquement, aucun déchiffrement au niveau des relais) avant d'arriver à destination.
De cette manière, la source (Google par exemple) sera incapable de connaître votre IP personelle à l'origine de la requête et les relais MySearch ne pourront pas voir le contenu de votre requête (ils se contentent de relayer une connexion SSL chiffrée de bout(votre Mysearch local) en bout (la source : Google par exemple)
L'aspect graphique a aussi évolué depuis le journal. Maintenant ca ressemble à ça :

Voici une instance Mysearch publique : https://search.jesuislibre.net/
Sources : http://codingteam.net/project/mysearch
[^] # Re: MySearch
Posté par Goffi (site web personnel, Mastodon) . Évalué à 2.
super ! Est-ce qu'un modo peut mettre une note dans la dépêche vers ce commentaire ?
[^] # Re: MySearch
Posté par patrick_g (site web personnel) . Évalué à 3.
Fait.
[^] # Re: MySearch
Posté par barmic . Évalué à 3.
Il manque des icônes « centralisé » pour qwant, ixquick et duckduckgo.
Je me demande si c'est pertinent de parler de mysearch comme d'une solution centralisée. Il ne s'agit pas d'un réseau paire à paire comme seeks, mais c'est une solution à installer chez soit (l'instance https://search.jesuislibre.net/ est une démo, non ?).
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: MySearch
Posté par Goffi (site web personnel, Mastodon) . Évalué à 4.
elles n'ont pas été mise parce qu'un service propriétaire implique que ça soit centralisé (enfin techniquement non on pourrait avoir un blob binaire à installer chez soi, ou ça pourrait être réparti entre plusieurs boîtes, mais en pratique c'est toujours le cas).
mysearch comme présenté dans le journal était centralisé, visiblement ça n'est plus le cas. Le fait de pouvoir installer une instance chez soi ne le rend pas décentralisé pour autant: elgg est centralisé et tu peux l'installer chez toi, de même que dotclear ou wordpress.
[^] # Re: MySearch
Posté par CrEv (site web personnel) . Évalué à 2.
Hum, décentralisé ça veut pas forcément dire que toi tu peux l'installer, c'est plus un aspect technique qu'autre chose.
Par exemple skype (bon ok lui tu l'installais) faisait du p2p et était plutôt décentralisé, et propriétaire.
[^] # Re: MySearch
Posté par barmic . Évalué à 3.
Soit on cherche à mettre l'information soit non, mais le mettre à moitié (en parler dans certains titre (pourquoi ne pas l'avoir mis pour qwant), mais ne pas mettre l'icône qui va avec) c'est dommage. Des logiciels propriétaires en paire à paire, on peut en citer pleins (btsync par exemple). L'implication propriétaire => centralisée, n'est pas correcte, même si dans le domaine des moteurs de recherche elle est peut être valide.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: MySearch
Posté par Goffi (site web personnel, Mastodon) . Évalué à 1.
On parle des moteurs de recherche ici, elle est valide dans ce cas. Sinon ça fait 6 mois au doigt mouillé que le dépêche est en rédaction collective, personne ne vous a empêché de faire les corrections qui vont bien…
[^] # Re: MySearch
Posté par barmic . Évalué à 3.
Reste calme. La dernière fois que j'ai regardé cette dépêche c'était juste un grand foutoir. Tu m'excusera de ne pas y repasser régulièrement. Surtout que je ne vois pas ce que je pouvais apporter comme contenu (et on ne voit pas l'étape de relecture comme je ne suis pas relecteur).
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: MySearch
Posté par Goffi (site web personnel, Mastodon) . Évalué à 2.
Où je ne suis pas calme ? Je dis juste que pinailler sur ce genre de truc ça fait 6 mois qu'on peut le faire, maintenant vous pouvez toujours le faire pour les prochaines.
[^] # Re: MySearch
Posté par Professeur Méphisto . Évalué à 2.
Bravo, j'aime beaucoup le concept !
Quelques questions néanmoins et une remarque…
Comment est choisi le nœud de sortie ? aléatoirement ?
Pour héberger un nœud, quelles sont les ressources nécessaires ? Un Rpi, une connexion ADSL (pas d'IP fixe) « grand public » suffisent ?
Une remarque : ajouter pour language et search engine une option « all »
[^] # Re: MySearch
Posté par tuxicoman (site web personnel, Mastodon) . Évalué à 2.
Il n'y a pas vraiment de noeud de sortie vu que chiffrement se fait de bout en bout et non pas uniquement jusqu'au dernier noeud.
Mais pour l'instant la liste des noeuds est hardcodée et seul "search.jesuislibre.net" est dans cette liste.
Pour etre un noeud relai, il te faut juste avoir le port 60062 joignable sur une IP publique
# YaCy
Posté par coid . Évalué à 5. Dernière modification le 04 juin 2014 à 09:00.
C’est intéressant et même assez impressionnant, ça semble assez complet, mais :
— c’est un peu difficile à configurer (bon pas tant que ça, juste des questions de routeur et de pare-feu à régler),
— pas très noob friendly (c’est pas demain la veille que Mme Michu va trouver ça formidable),
— il manque sans doute du monde pour parcourir le web (mais je vois que ça s’améliore avec le temps),
— seul point vraiment rebutant : c’est du Java………………… et ça me bouffe 700 Mo en tâche de fond et il a fallu que j’accorde tous les droits via mon pare-feu pour réussir à connecter javaw aux pairs.
Noooooooooooooooooooooooooooooooon ! :( :(
[^] # Re: YaCy
Posté par hsyl20 (site web personnel) . Évalué à 1.
Il faut réviser les bases du fonctionnement d'un garbage collector ;-)
http://gfx.developpez.com/tutoriel/java/gc/
Mais sinon j'avoue que j'ai demandé l'indexation de wikipedia (tant qu'à faire) sur mon installation YaCy et c'est assez violent en terme de consommation CPU.
# DDG
Posté par romu . Évalué à 3.
Bonjour,
J'ai tenté d'utiliser autre chose que Google de mon côté, voici mon petit retour.
Qwant
Les résultats me semblent assez bons, mais le truc rédhibitoire pour moi, c'est la non mémorisation de la présentation des résultats. Qwant propose les présentations mosaïque, catégories et listes. Et malheureusement, à chaque recherche, c'est toujours mosaïque qui est proposé par défaut, créer un compte chez eux, ne permet pas de régler ça.
DDG
Quand il a commencé à faire le buzz, j'ai beaucoup utilisé ce moteur, et j'ai fini par lâcher tellement les résultats étaient pourris.
Depuis quelques jours, DDG a beaucoup changé dans sa présentation, on peut chercher des images, et je trouve les résultats bien plus pertinents, adopté !
My 2 cents.
# Yacy et l'IPv6
Posté par claudex . Évalué à 3.
J'ai testé yacy mais il ne gère pas l'IPv6, du coup, c'est un peu embêtant pour le rendre accessible de l'extérieur.
« Rappelez-vous toujours que si la Gestapo avait les moyens de vous faire parler, les politiciens ont, eux, les moyens de vous faire taire. » Coluche
[^] # Re: Yacy et l'IPv6
Posté par claudex . Évalué à 5.
Et après 10-15 minutes de crawling, il s'est arrêter en disant
mais vu que la consommation mémoire ne descend pas, je ne suis pas sûr qu'il va reprendre.
« Rappelez-vous toujours que si la Gestapo avait les moyens de vous faire parler, les politiciens ont, eux, les moyens de vous faire taire. » Coluche
[^] # Re: Yacy et l'IPv6
Posté par Damien Clauzel (site web personnel) . Évalué à 1.
Sisi, YaCy supporte IPv6 : il peut joindre et être joint par le reste du réseau; faut juste ajuster un poil la config. Par contre, s'il tourne sans interface IPv4, il sera traité comme un nœud Junior et non Senior (et sera donc castré).
[^] # Re: Yacy et l'IPv6
Posté par claudex . Évalué à 3.
Tu as un lien pour cette configuration ? http://search.yacy.net/yacysearch.html?query=yacy+ipv6&query=&verify=ifexist&contentdom=text&nav=filetype%2Cprotocol%2Chosts%2Cauthors%2Cnamespace%2Ctopics&startRecord=0&indexof=off&meanCount=5&resource=global&prefermaskfilter=&maximumRecords=10 n'est pas très pertinent sur le sujet
« Rappelez-vous toujours que si la Gestapo avait les moyens de vous faire parler, les politiciens ont, eux, les moyens de vous faire taire. » Coluche
[^] # Re: Yacy et l'IPv6
Posté par 🚲 Tanguy Ortolo (site web personnel) . Évalué à 6.
Si on castre les jeunes, il va y avoir des problèmes de renouvellement…
# Je me suis demandé « c'est quoi SACD ? »
Posté par bobo38 . Évalué à -5.
Première réaction, les bordures rouges ça fait un visuel très « à gauche ». Je m'attendais à un groupuscule quelconque, et j'ai cherché (sans lire l'article bien évidemment).
Pour info c'est la Société des Auteurs et Compositeurs Dramatiques. Un repaire de tartuffes farcis aux subventions de l'État pour l'« exception culturelle », inféodé à l'interprétation orthodoxe de la mafia du droit d'auteur je présume. Qu'ils tirent à boulets rouges maladroits sur tout ce qui peut avoir un lien avec une réforme des droits de copie pour s'aligner avec la réalité du réseau mondial ne m'étonne pas.
Du coup je suis bien content qu'ils écrivent des articles mal ficelés bien pourris : « X = FN = c'est des méchants », c'est vraiment de la rhétorique éculée de bas étage bien ridicule.
[^] # Re: Je me suis demandé « c'est quoi SACD ? »
Posté par Benoît Sibaud (site web personnel) . Évalué à 5.
À mon avis, tu voulais répondre sur ce journal plutôt qu'ici.
[^] # Re: Je me suis demandé « c'est quoi SACD ? »
Posté par claudex . Évalué à 4.
Je ne suis pas sûr que ce soit le bon contenu qui a été commenté.
« Rappelez-vous toujours que si la Gestapo avait les moyens de vous faire parler, les politiciens ont, eux, les moyens de vous faire taire. » Coluche
[^] # Re: Je me suis demandé « c'est quoi SACD ? » => oups
Posté par bobo38 . Évalué à 1.
oups
# Commentaire supprimé
Posté par Yvesmarcer . Évalué à -1. Dernière modification le 22 juin 2016 à 12:29.
Ce commentaire a été supprimé par l’équipe de modération.
# Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par FantastIX . Évalué à 10.
Depuis un bon moment, Google me casse les pieds en me donnant quasi invariablement des résultats qui ne comprennent pas tous les mots clés de ma recherche. Dans les résultats, certains les contiennent tous mais faut chercher, souvent plus loin que la deuxième page, mais la plupart des résultats ne contient qu'une partie des mots-clés, jamais les mêmes.
(DuckDuckGo a aussi tendance à ne pas inclure tous les mots clés.)
Le tri par page rank, c'est cool? Quand je cherche quelque chose, dont la réponse se trouve visiblement dans des forums ou des listes de diffusion, ça ne m'arrange pas de voir les résultats de 2004, 2008, 2003, 2001 avant ceux de cette année. Tout trier par page-rank n'est pas bon. Tout trier par date n'est pas bon non plus, ça dépend du contexte en fait.
Ça fait des années que le premier résultat n'est jamais le bon, les suivants rarement. Sans compter aussi la propension de Google à considérer que les mots sont mal tapés, ont une mauvaise orthographe, alors que je SAIS que c'est la bonne, que Google modifie ma recherche en fonction de ce qu'il croit être correct, sans me demander mon avis et que ce n'est que trop rarement que j'ai devant les yeux "Vouliez-vous dire […]" (Mais oui, c'est ça que j'ai voulu dire, pourquoi tu m'écoutes pas quand je tape!?) Il fait d'abord sa petite recherche avec les termes, qu'il a rectifiés, et me propose de temps en temps un lien avec ce que j'ai tapé…
C'est bien parce que j'ai affaire à une machine (enfin, des milliers de machines) mais j'ai vraiment l'impression d'être pris pour un abruti, genre «l'autre andouille, entre la chaise et le clavier n'est pas foutu de savoir ce qu'il cherche!»
C'est particulièrement pelant quand on recherche des infos sur un nom de programme, un acronyme… ("IPO", pas "EPO"! Et non, me suis pas planté! "systemd", pas "système D", ni "system V", co****rd!) Les exemples sont fictifs. Mais ça donne le ton.
Tout ça, ça m'agace.
Je me fous pas mal de l'âge de Britney Spears, d'avoir une calculatrice dans Google, d'avoir des résultats instantanés avec javascript… (qui m'emmerde plus qu'autre chose, surtout quand je reviens en arrière et que c'est pas sur la page à laquelle je m'attends…) Au minimum, quand JE me casse le tronc pour trouver des mots clés que JE considère pertinents, c'est pas pour les ignorer et me balancer, en premier, les pages qui n'ont rien à voir avec ce que je voulais.
Alors quand je lis que c'est difficile de faire mieux que Google, pas tant que ça, à mon avis.
On est pas vendredi? désolé, je suis un peu en avance.
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par gnx . Évalué à 9.
Tout pareil !
La correction me semble de plus en plus agressive, et souvent trop agressive à mon goût. Je dois régulièrement corriger ma recherche, une fois, deux fois pour rajouter des guillemets afin qu'il ne modifie pas trop les mots-clefs que je lui ai fourni, voire qu'il ne les ignore pas tout simplement.
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par barmic . Évalué à 1.
Le pagerank inclus une viellesse, non ?
Je t'énerve si je parle de la syntaxe google ? Du style :
Pour forcer la recherche de systemd et surtout supprimer les pages qui parlent de linuxfr ?
Tu peut trouver plus d'info là https://support.google.com/websearch/answer/136861?hl=fr
Et tu as une interface pour faire ce genre de recherche là : http://www.google.com/advanced_search
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par ariasuni . Évalué à 5. Dernière modification le 05 juin 2014 à 13:44.
Donc en fait il faut deviner à l’avance les mots qu’il va automatiquement corriger parce qu’il pense qu’il a raison…
Je préfèrerais qu’il fasse une suggestion plutôt que de forcer la correction comme ça. Comme Duckduckgo par exemple.
Écrit en Bépo selon l’orthographe de 1990
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par barmic . Évalué à 3.
C'est une façon de voir une autre étant qu'il faut entourer de quotes les mots dont tu es sûr (et ça ça ne demande pas de dont divinatoire en principe).
Je présume qu'ils ont des outils pour savoir si cette fonctionnalité (qui leur bouffe des ressources) est utile ou non et que s'ils continuent à le faire c'est pas pour le fun de faire tourner leur jolis algo.
Chez moi, il retourne la page wikipedia de « Manga » quand je lui demande « mangea ». Google pour la même recherche me retourne des pages qui contiennent « mangea » (toutes dans la première page).
Très franchement c'est de l'ordre du détail d'avoir à mettre ou non des guillemets. Des gens bien moins geek que toi ou moi le font sans problème, je pense pas que l'on ai une névrose particulière qui empêche de le faire.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par FantastIX . Évalué à 5.
Ça me paraît assez audacieux de généraliser sur des centaines de millions d'individus… Perso, autour de moi, je ne connais personne qui se serve des opérateurs ET, OR. Les guillemets, je n'en parle même pas.
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par barmic . Évalué à 1.
Mes parents s'en servent. Tu as pleins de magasines et sites qui décrivent ces syntaxes. Les OR/OU et AND/ET, je n'ai pas vu grand monde s'en servir mais les +/- et quotes ça oui et plus d'une fois.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par ariasuni . Évalué à 2.
À part les guillemets, je n’ai jamais vu personne se servir du reste.
Écrit en Bépo selon l’orthographe de 1990
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par barmic . Évalué à 3.
Ça tombe bien les guillemets inclu maintenant l'ancien comportement du "+".
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par ariasuni . Évalué à 2.
Et comment on est censé savoir ça en fait? Je ne connaissais pas moi-même le +…
Écrit en Bépo selon l’orthographe de 1990
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par ariasuni . Évalué à 4.
J’ai que ça à faire de mettre des guillemets autour de tous mes mots.
Ça sert. Mais pas à moi. 9 fois sur 10 ça me fait perdre du temps.
Les résultats en français sont peut-être moins bon? Là en anglais il me trouve de plutôt bons résultats (genre «Witkionary — mangea»).
Non, ça n’est pas de l’ordre du détail, la plupart des gens ne connaissent pas et il faut réfléchir à quand l’utiliser. Mais comme on ne sait pas à l’avance.
Écrit en Bépo selon l’orthographe de 1990
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par FantastIX . Évalué à 6.
Scénario 1: je ne sais pas ce que Google va corriger tout seul:
- je tape
- il change, il cherche il trouve
- je re-tape, avec les quotes, les plus les moins, les trucs…
Moralité: j'ai perdu une recherche, je râle, ça m'emmerde.
Scénario 2: je fais gaffe et j'entoure tout avec des guillemets, je mets les points sur les i, les barres sur les t, les + et les moins, tout là où il faut…
Moralité: je perds mon temps à faire le boulot de Google et j'en ai ma claque au bout de 5 minutes. Je râle, ça m'emmerde.
Alors, oui, ta réponse m'énerve parce qu'elle indique que tu as probablement loupé le sujet.
Je rappelle aussi en passant que le comportement par défaut, supposé connu, de Google est de chercher tous les mots. Faire une recherche avancée et tout taper dans "Résultats contenant tous les termes" est identique. Les résultats aussi, d'ailleurs. Il faut donc taper davantage pour (espérer) obtenir de Google le comportement qu'il devrait avoir par défaut. D'où mon commentaire.
Je veux en venir à ce que le mode de recherche promu par Google (et par lequel il s'est probablement fait connaître) est faux: il ne recherche pas/plus les pages contenant tous les termes.
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par barmic . Évalué à -2.
Donc d'après tes 2 users stories, je présume que Google Search va couler d'ici quelques semaine ou quelques mois, je vois pas où est le problème .
Non il s'est fait connaître (et continue à se faire connaître) parce qu'il trouve ce que tu cherche (un « tu » impersonnel). Comme je disais plus haut ce que tu lui reproche c'est du travail en plus de son coté et 1ms de plus de travail pour toi c'est quelques heures par jour de travail en plus par continent, s'ils n'étaient pas convaincu que ça améliore la recherche avec des éléments tangibles à l'appui, je ne vois pas pourquoi ils le ferraient.
Si c'est un besoin si pressant, je ne doute pas qu'il doit exister un script greasmonkey qui va entourer tes termes avec +"" et qui devrait largement te soulager.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par ariasuni . Évalué à 3.
On marche sur la tête… Il faudrait un script GreaseMonkey pour que Google cesse de nous mettre des bâtons dans les roues, génial. Pourtant ça serait pas compliqué de faire une option, et ça doit bien faire chier des gens chez Google nan?
Écrit en Bépo selon l’orthographe de 1990
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par barmic . Évalué à 3.
Tu peux utiliser la page de recherche avancée dont j'ai donné le lien. Le peu de solution montre à mon avis le peu d'intérêt (à moins que vous pensez que c'est un complot).
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par ariasuni . Évalué à 2.
Et du coup ça marche avec les raccourcis web de Firefox par exemple?
Enfin c’est comme le peu d’intérêt pour les alternatives à l’azerty et au qwerty, à Windows (même si ça commence à bouger), etc.
Écrit en Bépo selon l’orthographe de 1990
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par barmic . Évalué à 2.
Crée-toi un plugin open search et demande toi pourquoi personne ne l'a fait avant (ça n'a rien de très compliqué).
Je connais bien plus de ressources sur l'utilisation de dvorak ou du bépo que de google en l'obligeant à utiliser des mots clef exact.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par Professeur Méphisto . Évalué à 3.
j'ai l’impression que quand tu mets ces mots clés entre " et " ils sont systématiquement pris en compte. Par contre tu y perds la tolérence du motuer sur l'orthogaffe
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par barmic . Évalué à 3.
Tu peut utiliser + pour ça.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par gnx . Évalué à 1.
Je ne pige pas. Le signe "+" n'apparaît pas sur les pages de doc que tu as données et il me semble que son usage avait été supprimé il y a quelques années.
Les résultats avec et sans "+" sont néanmoins effectivement différents ; mais en quoi ?…
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par barmic . Évalué à 3.
En effet en 2011, maintenant les double quote font le même boulot.
Je ne sais pas (je me sert peu du moteur de recherche de google, du moins rarement directement).
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par gnx . Évalué à 3.
Ben… au message précédent tu conseilles "+" mais tu ne sais pas ce que ça fait ?
[^] # Re: Un truc m'emmerde chez Google, chez les autres aussi d'ailleurs...
Posté par barmic . Évalué à 2.
Je viens de (re)découvrir qu'il a était enlevé (je savais qu'il existait, mais je ne m'en sert jamais).
Comme je disais je ne me sert pas directement de google et généralement c'est quand je sais pas trop comment chercher et que j'écris une phrase complète comme recherche.
Tous les contenus que j'écris ici sont sous licence CC0 (j'abandonne autant que possible mes droits d'auteur sur mes écrits)
Suivre le flux des commentaires
Note : les commentaires appartiennent à celles et ceux qui les ont postés. Nous n’en sommes pas responsables.