
Il y a exactement deux mois, un incident était survenu suite à un redémarrage brutal du serveur hébergeant les conteneurs de production et de développement ayant entraîné une attribution inattendue d’adresses IP. Et des réponses techniques 502 Bad Gateway pour notre lectorat.
Ce 26 août, vers 15:22, un message peu engageant est arrivé par pneumatique sur nos téléscripteurs (via Signal pour être précis) : « Tiens c’est bizarre j’ai perdu accès au site. Et au serveur oups. » L’après-midi et la soirée furent longues.
Sommaire
Premier diagnostic
Le serveur répond au ping et permet les connexions TCP port 22, mais pas le SSH. Et les services web ne répondent plus. Souci matériel ? Noyau en vrac ? Attaque en cours ? Les spéculations vont bon train.
La connexion au serveur revient par intermittence, permettant à un moment d’exécuter quelques commandes, à d’autres d’attendre longuement pour l’affichage d’un caractère ou l’exécution de la commande tapée.
Le premier contact réétabli avec le serveur est assez clair (une forte charge) :
$ uptime
15:06:59 up 2 days, 2:54, 1 user, load average: 50,00, 205,21, 260,83(dernier redémarrage le week-end précédent, mais surtout une charge système moyenne respectivement de 50, 205 et 261 sur les 1, 5 et 15 dernières minutes)
Initialement on suppose qu’il s’agit d’un trop grand nombre de requêtes ou de certaines requêtes tentant des injections de code sur le site (bref le trafic de fond plutôt habituel et permanent), et on ajoute des règles de filtrage péniblement et lentement pour bloquer les IP qui ressortent le plus dans nos logs.
Le site est alors inaccessible pendant plusieurs périodes. On arrête et relance ensuite plusieurs fois les services en pensant avoir ajouté suffisamment de filtrage, mais rapidement le serveur se retrouve englué. Les services sont alors arrêtés plus longuement le temps d’analyser les logs au calme. Au calme inclut notamment ne pas juste disposer d’une connexion ssh depuis un smartphone, mais plutôt d’un clavier et d’un grand écran par exemple, de l’accès à tous les secrets et toute la documentation aussi.
Finalement le trafic n’est pas énorme (en volume total) et si les requêtes hostiles sont bien présentes, rien ne semble inhabituel. Par contre les processus de coloration syntaxique partent en vrille, consommant chacun un processeur et aspirant allègrement la mémoire disponible. Avant d’être éliminés par le noyau Linux.
La console est remplie d’élimination de processus de ce type :
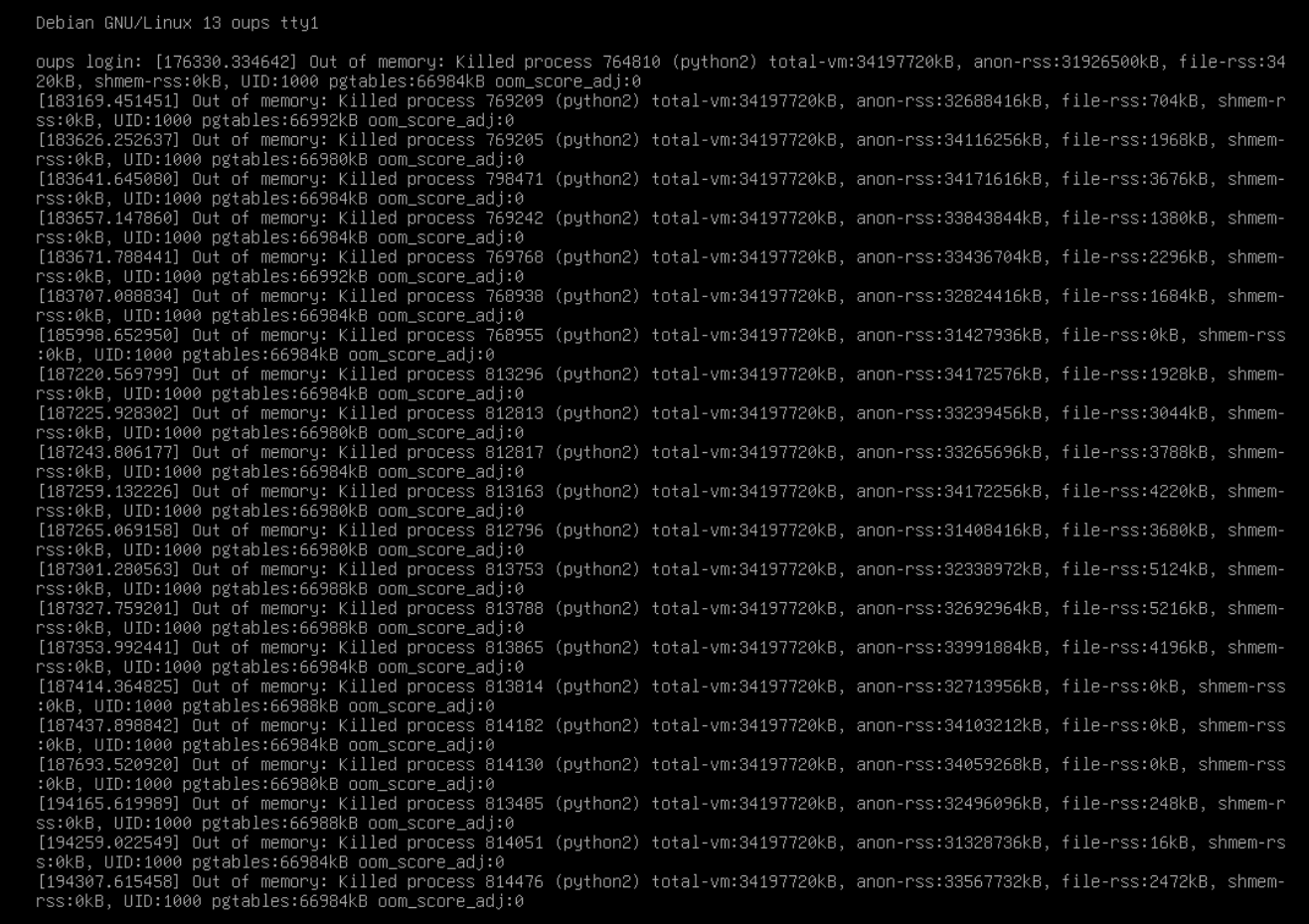
Mais si rien n’a changé niveau logiciel sur le conteneur LXC de production et si les requêtes ne sont pas inhabituelles, qu’est-ce qui peut bien écrouler le serveur et créer ces processus gourmands ?
Eh bien des requêtes habituelles…
Pendant les phases d’attente lorsque le serveur ne répondait plus vraiment, nous avons noté qu'une nouvelle entrée de suivi a été créée (merci BAud et merci RSS/Atom pour nous avoir permis de la voir alors que le serveur ne répondait déjà plus). Elle indique que la coloration syntaxique ne marche plus sur le site. Notamment l’exemple donné dans la documentation.
Pourtant le rendu fonctionne en testant en ligne de commande avec pygmentize.
Mais oui en testant l’exemple donné via le site, il est créé un processus Python2 pygment qui commence à se gaver de ressources.
Et en regardant les différents contenus et commentaires créés sur le site autour de l’incident, en filtrant sur ceux contenant des blocs avec de la coloration syntaxique, la dépêche (alors en préparation) sur G'MIC 3.6 apparaît. Et en testant cette dépêche, il est bien créé quatre processus Python2 pygment qui se gavent de ressources et ne semblent jamais vouloir se terminer. À rapprocher par exemple d’une page qui a été servie en 6785.9978s.

OK, le souci vient de requêtes tout à fait habituelles de coloration syntaxique, reste à comprendre pourquoi ces processus tournent mal.
La boucle sans fin
Un petit strace pour suivre les appels système en cours sur un des processus infernaux relève une boucle assez violente :
(...)
close(623199355) = -1 EBADF (Bad file descriptor)
close(623199356) = -1 EBADF (Bad file descriptor)
close(623199357) = -1 EBADF (Bad file descriptor)
(...)
Il semble y avoir une immense itération sur des descripteurs de fichiers, en vue de les fermer, mais à l’aveugle, sans savoir s’ils existent réellement.
En regardant le code du composant utilisé (pygments), il semble n'y avoir qu'un seul appel à close() :
# close fd's inherited from the ruby parent
import resource
maxfd = resource.getrlimit(resource.RLIMIT_NOFILE)[1]
if maxfd == resource.RLIM_INFINITY:
maxfd = 65536
for fd in range(3, maxfd):
try:
os.close(fd)
except:
passDonc on itère sur tous les descripteurs entre 3 et le maximum déterminé…
>>> import resource
>>> print(resource.getrlimit(resource.RLIMIT_NOFILE)[1])
524288
>>> print(resource.RLIM_INFINITY)
-1Un demi-million de fois ici donc. L’objectif initial de la boucle est de fermer les descripteurs de fichiers provenant du processus Ruby père, issue du fork via Open3.popen3. La version suivante du composant la remplace d’ailleurs par un ajout de l'option :close_others, qui précisément « modifie l’héritage [des descripteurs de fichiers du processus parent] en fermant les non-standards (numéros 3 et plus grands) ».
Sur une Debian 12, la limite du nombre de fichiers par défaut, c’est 1 048 576. C’est déjà probablement bien plus que la valeur qui prévalait à l’époque où a été écrit la boucle Python (on avait des limitations à 4096 à une époque reculée). Mais il s’avère que durant le week-end l’hôte du conteneur de production a été migré en Debian 13. Sans modification du conteneur de production pensions-nous. Sans modification directe du conteneur de production. Mais quid d’une modification indirecte ? Par exemple si la limite par défaut des « Max open files » était passée à 1 073 741 816 sur l’hôte, soit 1024 fois plus que quelques jours auparavant. Et donc des boucles nettement plus longues voire sans fin, sans libération de mémoire.
On ne peut mettre à jour le composant pygments dans l’immédiat, mais on peut limiter les dégâts en abaissant la limite du nombre de descripteurs de fichiers à quelque chose de raisonnable (i.e. on va gaspiller raisonnablement des cycles CPU dans une boucle un peu inutile mais brève…). Une édition de /etc/security/limits.conf, un redémarrage du conteneur de production et on peut vérifier que cela va nettement mieux avec cette réparation de fortune.
Une dernière page d’epub ?
Le conteneur LXC portant le service epub de production a assez mal pris la surcharge du serveur, et vers 20h08, systemd-networkd sifflera la fin de la récré avec un eth0: The interface entered the failed state frequently, refusing to reconfigure it automatically (quelque chose comme « ça n’arrête pas d’échouer, débrouillez-vous sans moi »). Le service epub est resté en carafe jusqu’au 27 août vers 13h31 (merci pour l’entrée de suivi).
Voir ce commentaire sur la dépêche de l’incident précédent expliquant la séparation du service epub et du conteneur principal de production (en bref : dette technique et migration en cours).
Retour en graphiques sur la journée
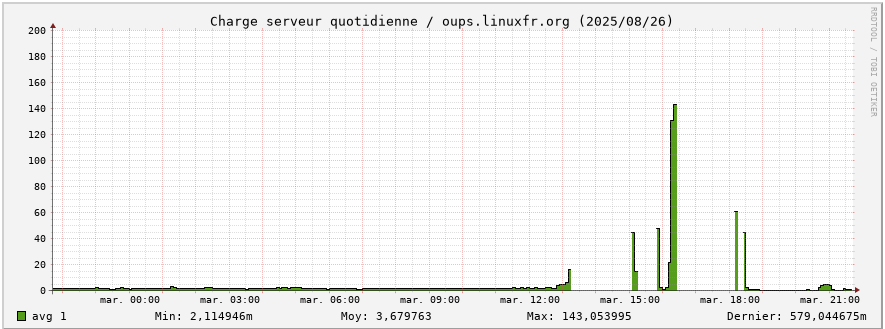
Le serveur était très occupé. Au point de n’avoir pas le temps de mettre à jour les graphiques de temps en temps.
Rétrospectivement les processeurs du serveur ont travaillé dur : 140 de charge sur le graphique (mais avec des pics jusque 260 d’après la commande uptime), contre moins de 5 en temps normal (un petit facteur de 28 à 52 ô_Ô)
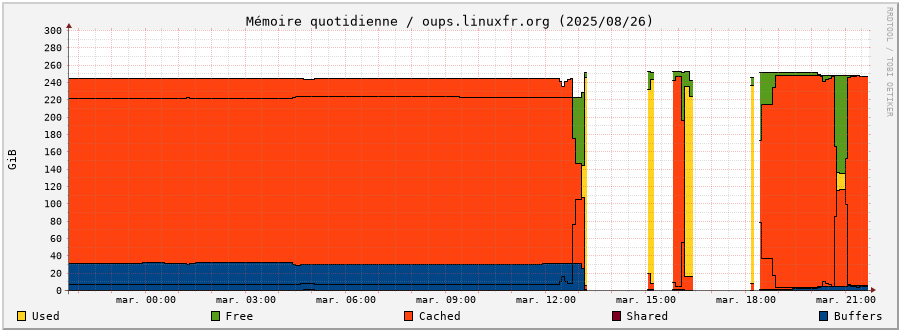
Et l’utilisation de la mémoire montre aussi de brutaux changements de comportement : libération intempestive de mémoire (Free, en vert), utilisation mémoire plus importante que d’habitude (Used, en jaune), là où le comportement normal est d’avoir le maximum en cache (Cached, en orange) et des processus tellement peu consommateurs en RAM que cela n’apparaît normalement pas.
Mesures préventives et correctives
Dans les actions en cours ou à prévoir :
- mettre à jour la documentation pour disposer facilement et rapidement des informations pour les connexions aux cartes d’administration ou les procédures de blocages d’IP
- procéder à la montée de version des composants (yapuka, épineux sujet de la dette technique à éponger)
- vérifier l’efficacité des limitations CPU/mémoire mises sur certains conteneurs LXC et les étendre aux autres
- mettre des limites sur des processus particuliers (comme ceux de pygments)
- ajouter le déploiement des limites par utilisateur dans le code Ansible
- corriger la collecte
rrddes métriques concernant les interfaces réseau - remonter les alertes OOM qui ne sont pas normales
- comprendre la surconsommation mémoire ? (les boucles actives expliquent la consommation processeur, mais pour la mémoire ?)
Bonus inattendu pour l’incident précédent du 26 juin 2025
De façon cocasse, ce nouvel incident et le temps passé à parcourir les différents logs ont permis de retrouver les infos de la carte d’administration distante et d’expliciter l’origine du redémarrage serveur intempestif. À quelque chose malheur est bon, si on peut dire. Ceci n’est pas une invitation pour un prochain incident.
# bravo
Posté par antistress (site web personnel) . Évalué à 10.
Bravo et merci pour tout ce travail déjà
[^] # Re: bravo
Posté par Mathias Bavay (site web personnel) . Évalué à 8.
Bravo et on se sent désolé pour vous, pour le stress que vous avez subi!
# pygments.rb patch
Posté par niol (site web personnel) . Évalué à 4.
Peut être que le correctif suivant use close_others Ruby mechanism to prevent file descriptor leaking to Python peut solutionner encore plus élégamment le problème.
[^] # Re: pygments.rb patch
Posté par Benoît Sibaud (site web personnel) . Évalué à 10. Dernière modification le 27 août 2025 à 17:59.
C'est précisément ce que dit la dépêche.
[^] # Re: pygments.rb patch
Posté par niol (site web personnel) . Évalué à 1.
Je n'avais pas compris que ce correctif avait été rétroporté sur les paquets en production.
# Faut voir le bon côté des choses
Posté par Ysabeau 🧶 (site web personnel, Mastodon) . Évalué à 10.
Pendant ce temps, on n'a pas eu de spam.
Je n’ai aucun avis sur systemd
# Python ?
Posté par devnewton 🍺 (site web personnel) . Évalué à 7.
Puisque linuxfr est en Ruby, pourquoi ne pas utiliser une bibliothèque dans ce langage?
Ce post est offensant ? Prévenez moi sur https://linuxfr.org/board
[^] # Re: Python ?
Posté par BAud (site web personnel) . Évalué à 5.
comme https://github.com/pygments/pygments.rb ?
[^] # Re: Python ?
Posté par Benoît Sibaud (site web personnel) . Évalué à 6. Dernière modification le 28 août 2025 à 08:20.
Qui est le composant actuellement utilisé donc, une Gem ruby qui lance du Python. https://rubygems.org/gems/pygments.rb
[^] # Re: Python ?
Posté par Benoît Sibaud (site web personnel) . Évalué à 5.
le dev ruby n'étant pas ma spécialité, en regardant les gems ruby les plus téléchargées pour la coloration syntaxique on trouve bien le composant actuel, quelques autres sans modification récentes et rouge qui semble très actif niveau développement.
[^] # Re: Python ?
Posté par Pol' uX (site web personnel) . Évalué à 10.
Si ça se trouve, tout l'écosystème Ruby est un sucre syntaxique qui s'appuie sur du code python derrière. :)
Adhérer à l'April, ça vous tente ?
[^] # Re: Python ?
Posté par Bruno Michel (site web personnel) . Évalué à 9.
À l'époque où j'avais ajouté ça, il n'existait pas de bibliothèque en Ruby autre que celle utilisée et qui lance du Python. De nos jours, il existe Rouge. Ça pourrait valoir le coup de tester le remplacement de Pygments.rb par Rouge.
[^] # Re: Python ?
Posté par Julien Jorge (site web personnel) . Évalué à 8.
P'têt bien qu'une ré-écriture de LinuxFr.org en Python est en cours ?
[^] # Re: Python ?
Posté par devnewton 🍺 (site web personnel) . Évalué à 7.
Ce toy language aurait l'avantage de permettre aux noobs de contribuer.
Ce post est offensant ? Prévenez moi sur https://linuxfr.org/board
[^] # Re: Python ?
Posté par ted (site web personnel) . Évalué à 8.
On dit "vibe-coder"
Un LUG en Lorraine : https://enunclic-cappel.fr
[^] # Re: Python ?
Posté par Colargol . Évalué à 5.
ou pourquoi pas en php, pour un retour aux origines :-)
[^] # Re: Python ?
Posté par bistouille . Évalué à 4.
Pourquoi ne pas recoder tout en Rust, ça serait "blazingly fast" et "bullet proof" :-)
# Mercis
Posté par cg . Évalué à 9.
… merci pour le chouette compte-rendu
… merci, je me suis couché plus tôt que d'habitude hier soir :D
[^] # Re: Mercis
Posté par BAud (site web personnel) . Évalué à 4.
eh ! stait revenu en stable à 23h25
[^] # Re: Mercis
Posté par Tarnyko (site web personnel) . Évalué à 3.
Ayant été là vers minuit, je confirme ;)
[^] # Re: Mercis
Posté par Faya . Évalué à 5. Dernière modification le 28 août 2025 à 15:19.
Ouais bin moi qui suis en UTC-4 ça m'a plombé ma 6e séance de mouling de la journée.
# Salon XMPP
Posté par anubis . Évalué à 3.
Y'a t'il des admins du site sur le salon linuxfr@chat.jabberfr.org pour pouvoir causer voire donner un coup de main dans ces moments là ?
aussi sur le salon xmpp:linuxfr@chat.jabberfr.org?join
[^] # Re: Salon XMPP
Posté par BAud (site web personnel) . Évalué à 7. Dernière modification le 29 août 2025 à 00:07.
nope, ce salon n'est pas officiellement affilié à LinuxFr.org (même si le logo et le titre pourraient faire penser le contraire) : c'est un peu comme le chan #linuxfr qui était sur freenode (je ne sais même pas s'il a migré sur libera.chat ou un autre serveur), des membres de LinuxFr.org ou non, avec plus ou moins de connaissances du site et de son écosystème.
« ces moments-là » c'est un peu tard pour s'impliquer : c'est en amont qu'il faut avoir fait ses preuves ;-)
Tu te rends bien compte que le root ne se donne pas au premier venu qui se propose et à qui il faudrait expliquer tout le contexte sur le moment, il y a un peu autre chose à faire que « causer » (récupérer la main, diagnostiquer, retrouver la doc', redémarrer les services et suivre les logs, trouver une solution ou à défaut un contournement…)
Un bon admin saura identifier les interlocuteurs et prendre contact, installer au préalable LinuxFr.org chez soi et poser les questions sur la doc' existante (qui manque un peu, mais est relativement disponible au fil des dépêches de Oumph<). Ensuite à eux de choisir de t'intégrer dans la boucle si tu le souhaites ;-)
# Concernant la mémoire
Posté par Benoît Sibaud (site web personnel) . Évalué à 8.
Prenons ce court bout de code :
Avec la valeur X=10000000, il s'exécute en 6s avec python2 .
Avec la valeur X=100000000, il s'exécute en 66s toujours avec python2. Et la mémoire s'affole.
Même machine, même code, juste en exécutant avec python3. Beaucoup plus raisonnable en mémoire. Par contre la boucle active occupe toujours le processeur forcément.
Du coup il y a une fuite quelque part avec Python2, pas directement liée au code lui-même.
[^] # Re: Concernant la mémoire
Posté par BAud (site web personnel) . Évalué à 6. Dernière modification le 29 août 2025 à 00:28.
là c'est RES qui monte à 3 Go ; sur
oupslors de l'incident, c'est VIRT qui prenait jusque 32 Go et RES qui allait à 0.032t => c'est quoi ce t ?mais oui, semble lié à une empreinte mémoire pour python2 là où python3 ne s'étend pas plusieurs fois (meilleure gestion du multithreading qui ne semble pourtant pas nécessaire pour ce code ? ou meilleure libération de buffers de logs…)
[^] # Re: Concernant la mémoire
Posté par Benoît Sibaud (site web personnel) . Évalué à 6.
Visiblement en python 2, sur ce code, VIRT et RSS se suivent (0.032t ça fait 32g ; comme on avait 2 fois 300M ou 3G dans mes tests)
[^] # Re: Concernant la mémoire
Posté par BAud (site web personnel) . Évalué à 4.
ah ok, c'est nul ces unités non homogènes dans
top:/moui, tu as pris une boucle 10x plus petite qu'en prod'.
sinon, je ne comprends pas pourquoi il n'y avait que 4 python2 sur
oups, mais bon spa trop grave.bref, passer à python3 qui lui est maintenu, pas forcément besoin de faire de l'archéologie ;-)
[^] # Re: Concernant la mémoire
Posté par Benoît Sibaud (site web personnel) . Évalué à 7.
Que quatre sur ma capture car la prod était alors stoppée et qu'il s'agit uniquement de mon test sur une copie de la dépêche G'Mic qui contient 4 blocs avec coloration. Pendant l'incident, potentiellement bien plus suivant le nombre de blocs édités (sachant que les processus ne finissent pas vraiment avant des heures, ils s'empilent jusqu'à ce que la Mort par OOM ne survienne)
Au passage, c'est un peu le code ultime qui sature ton CPU, qui sature ta RAM et qui tue tes I/O avec l'extérieur… dommage qu'il ne fasse rien d'utile.
[^] # Re: Concernant la mémoire
Posté par Julien Jorge (site web personnel) . Évalué à 7.
Je reproduis avec ton bout de code (X=100000000) :
et si je remplace le
os.close(fd)parpassc'est pareil :Par contre si je remplace le
range()par une bouclewhile fd != 100000000, ça va mieux :mais ce n'est pas très pythonic :)
[^] # Re: Concernant la mémoire
Posté par Toto . Évalué à 7.
Et en utilisant xrange() plutôt que range() histoire d'être plus pythonic2 ? (pas de python2 sous la main, flemme de l'installer ;))
[^] # Re: Concernant la mémoire
Posté par Benoît Sibaud (site web personnel) . Évalué à 10.
Bien vu.
https://www.geeksforgeeks.org/python/range-vs-xrange-in-python/
Donc basiquement c'est juste le range() le souci, même pas la fermeture des descripteurs ou la gestion des exceptions. Et c'est qui était moche mais indolore est devenu un gouffre de ressources lors de l'extension massive de la taille de la boucle.
[^] # Re: Concernant la mémoire
Posté par Julien Jorge (site web personnel) . Évalué à 4.
Avec xrange:
[^] # Re: Concernant la mémoire
Posté par BAud (site web personnel) . Évalué à 3.
mais qui pourrait penser qu'un élément de contrôle du langage (un simple parcours de boucle) puisse prendre autant de mémoire ? /o\
[^] # Re: Concernant la mémoire
Posté par Julien Jorge (site web personnel) . Évalué à 5.
Apparemment c'était une propriété connue et acceptée de Python 2 : https://stackoverflow.com/a/94962/1171783.
Je crois que l'attitude des pythonistes m'étonnera toujours, il y a même des commentaires pour préférer
range()àxrange(). Heureusement que Python 2 est mort et que tout est passé à Python 3 :D[^] # Re: Concernant la mémoire
Posté par BAud (site web personnel) . Évalué à 5. Dernière modification le 29 août 2025 à 18:49.
/me n'échange pas son baril de
contre un baril de
range()!# la galére !
Posté par matp75 . Évalué à 10.
Merci pour l'article. Grosse galère pour les admins surtout quand tu perd la main et que ca rame a fond, savoir dans quel ordre les problèmes arrivent, c'est pas simple. Et le chateau de carte de la dette technique , bon courage mais faut bien le faire a un moment….
# Question Cloud
Posté par TheBreton . Évalué à 3.
N'étant pas du tout dev. web, je me pose une question simpliste.
Si le site avait été hébergé chez un fournisseur de machine cloud avec une options de scalabilité activé serait ce au cycle de facturation suivant (avec un montant faramineux ) que le soucis aurait été investigué ?
[^] # Re: Question Cloud
Posté par Benoît Sibaud (site web personnel) . Évalué à 10.
Sur un service payant, encore plus si la scalabilité est activée, il faut une supervision des coûts et une alerte lorsque le montant courant du mois dépasse un certain seuil (avant la facture suivante donc). Et une analyse de factures pour savoir si ce qui est dépensé est ce qui est prévu et peut être amélioré (est-ce normal que le stockage représente 42% du tout, pourquoi on paie pour cette fonctionnalité qu'on n'est pas censée utiliser, c'est quoi ces ressources nommées "temp", pourquoi il reste des serveurs d'un ancien type plus cher que le nouveau type, etc.).
Ce n'est pas spécialement une question de dev. web, plutôt d'infrastructure / admin. cloud, le souci est le même avec des bases de données, des serveurs de calculs et une ferme de compilation par exemple.
La supervision des coûts (le FinOps) peut concerner des coûts cloud (le paiement à l'usage des fonctionnalités de l'infrastructure cloud utilisée) ou la version interne de ces mêmes coûts (électricité, climatisation, achat et renouvellement du matériel, maintenance, etc.). Ici pour l'incident LinuxFR.org, on peut supposer que l'on a fait monter le coût de l'électricité pendant quelques heures (et du coup le coût de la climatisation).
[^] # Re: Question Cloud
Posté par TheBreton . Évalué à 4.
Merci pour cette réponse détaillée, je suppose que le choix des métriques à surveiller n'est pas la partie la plus simple de ce métiers dont j'ignorais l'existance.
Suivre le flux des commentaires
Note : les commentaires appartiennent à celles et ceux qui les ont postés. Nous n’en sommes pas responsables.